基于端到端的人-机器人语音交互系统的制作方法
- 国知局
- 2024-06-21 11:28:15
本发明涉及语音交互,尤其涉及一种基于端到端的人-机器人语音交互系统。
背景技术:
1、随着人工智能技术的发展,具备语音交互能力的机器人在行动指挥、警卫警戒、巡逻等任务场景越来越发挥着重要的作用,目前语音交互的方案大多数是采用卷积神经网络(convolutional neural network,cnn)、循环神经网络(recurrent neural network,rnn)等常见网络为基础的混合识别系统来进行语音识别,采用自然语言理解技术来进行语音理解,采用文本分析+声学模型+声码器的组合方式来进行语音合成。
2、然而,现有的语音交互技术有着一些缺点。例如,语音识别误差大,难以正确理解上下文和语义等,这都会影响到机器人在一些任务场景下的表现。
技术实现思路
1、针对现有技术存在的问题,本发明提供一种基于端到端的人-机器人语音交互系统。
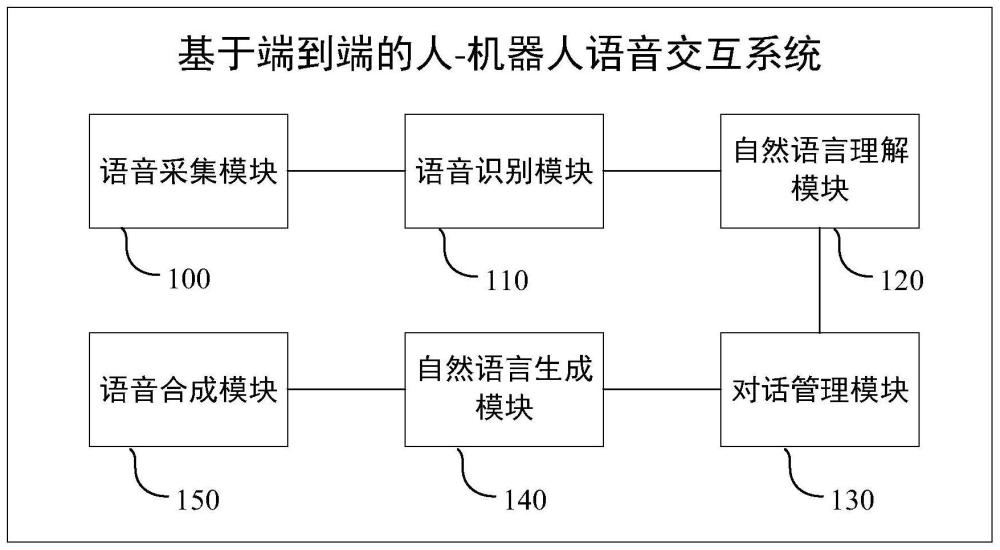
2、第一方面,本发明提供一种基于端到端的人-机器人语音交互系统,包括:
3、语音采集模块,用于采集用户的音频信号;
4、语音识别模块,用于基于端到端的语音识别模型,得到所述音频信号的文本结果;
5、自然语言理解模块,用于基于语义向量之间的距离识别出所述文本结果的相似语句,所述相似语句作为所述文本结果的语义理解结果;
6、对话管理模块,用于根据所述相似语句从数据库中选择相应的回复语句或者执行相应的动作指令;
7、自然语言生成模块,用于根据所述回复语句生成回复文本;
8、语音合成模块,用于将所述回复文本转换成语音进行输出。
9、在一些实施例中,所述基于语义向量之间的距离识别出所述文本结果的相似语句,包括:
10、将所述文本结果输入语义编码模型,得到所述文本结果的相似语句;
11、其中,所述语义编码模型用于对输入的所述文本结果进行分词处理和向量表示,得到所述文本结果对应的语义向量,然后基于语义向量之间的距离,从语句数据集中选择与所述文本结果对应的语义向量具有最高相似度且满足相似度阈值条件的目标语义向量所对应的语句,输出为所述文本结果的相似语句。
12、在一些实施例中,所述语义向量之间的距离基于语义向量之间的余弦相似度进行表征。
13、在一些实施例中,所述相似度阈值条件包括语义向量之间的余弦相似度大于第一阈值,所述第一阈值的取值范围为0.7~0.8。
14、在一些实施例中,所述基于端到端的语音识别模型,得到所述音频信号的文本结果,包括:
15、通过预训练模型提取所述音频信号的语音特征,然后通过所述端到端的语音识别模型对所述语音特征进行识别,得到所述音频信号的文本结果。
16、在一些实施例中,所述预训练模型支持多语种音频信号的语音特征提取。
17、在一些实施例中,所述端到端的语音识别模型为卷积神经网络模型。
18、在一些实施例中,所述采集用户的音频信号,包括:
19、通过设于所述机器人中的同心双环麦克风阵列采集用户的音频信号。
20、在一些实施例中,所述同心双环麦克风阵列的内环和外环上都均匀分布6个麦克风。
21、在一些实施例中,所述语音识别模块支持本地离线语音识别。
22、本发明提供的基于端到端的人-机器人语音交互系统,通过端到端的机器学习模型进行语音识别,并通过语义向量空间距离的相似语句识别方法进行语义理解,不仅提升了语音识别的准确率,而且提升了语义理解的准确度,从而能够大大提升该系统在相应任务场景下的表现。
技术特征:1.一种基于端到端的人-机器人语音交互系统,其特征在于,应用于机器人,包括:
2.根据权利要求1所述的基于端到端的人-机器人语音交互系统,其特征在于,所述基于语义向量之间的距离识别出所述文本结果的相似语句,包括:
3.根据权利要求2所述的基于端到端的人-机器人语音交互系统,其特征在于,所述语义向量之间的距离基于语义向量之间的余弦相似度进行表征。
4.根据权利要求3所述的基于端到端的人-机器人语音交互系统,其特征在于,所述相似度阈值条件包括语义向量之间的余弦相似度大于第一阈值,所述第一阈值的取值范围为0.7~0.8。
5.根据权利要求1所述的基于端到端的人-机器人语音交互系统,其特征在于,所述基于端到端的语音识别模型,得到所述音频信号的文本结果,包括:
6.根据权利要求5所述的基于端到端的人-机器人语音交互系统,其特征在于,所述预训练模型支持多语种音频信号的语音特征提取。
7.根据权利要求5所述的基于端到端的人-机器人语音交互系统,其特征在于,所述端到端的语音识别模型为卷积神经网络模型。
8.根据权利要求1所述的基于端到端的人-机器人语音交互系统,其特征在于,所述采集用户的音频信号,包括:
9.根据权利要求8所述的基于端到端的人-机器人语音交互系统,其特征在于,所述同心双环麦克风阵列的内环和外环上都均匀分布6个麦克风。
10.根据权利要求1、5、6或7所述的基于端到端的人-机器人语音交互系统,其特征在于,所述语音识别模块支持本地离线语音识别。
技术总结本发明提供一种基于端到端的人‑机器人语音交互系统,该系统应用于机器人,包括:语音采集模块,用于采集用户的音频信号;语音识别模块,用于基于端到端的语音识别模型,得到音频信号的文本结果;自然语言理解模块,用于基于语义向量之间的距离识别出文本结果的相似语句,相似语句作为文本结果的语义理解结果;对话管理模块,用于根据相似语句从数据库中选择相应的回复语句或者执行相应的动作指令;自然语言生成模块,用于根据回复语句生成回复文本;语音合成模块,用于将回复文本转换成语音进行输出。本发明提供的系统,不仅提升了语音识别的准确率,而且提升了语义理解的准确度,从而能够大大提升该系统在相应任务场景下的表现。技术研发人员:邸荻,贾晓磊,侯文琦,刘佳龙,李佳林受保护的技术使用者:中国人民解放军32398部队技术研发日:技术公布日:2024/2/19本文地址:https://www.jishuxx.com/zhuanli/20240618/21701.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。