一种基于可分离注意力和块掩蔽的语音识别方法和系统
- 国知局
- 2024-06-21 11:27:18
本发明涉及一种语音识别方法和系统,尤其涉及一种基于可分离注意力和块掩蔽的语音识别方法和系统,属于语音识别领域。
背景技术:
1、语音识别技术是一种将人类语言转换为文本命令的技术,被认为是2000—2010年间信息技术领域十大重要的科技发展技术之一,在智能助理、语音搜素、自动转录、语音指令等应用领域发挥着重要作用。
2、早期的语音识别技术主要是基于模式匹配和基础的信号处理技术,但是这些方法的局限性在于它们对环境噪声和说话者变化的敏感性较高,导致了限制性能。后来,引入了一些统计学的方法,特别是隐马尔可夫模型(hmm),用于声学特征和语言模型建模。随着深度学习的兴起,语音识别取得了巨大的突破。例如,dnn在声学模型中取得了显著的性能提升,而rnn和长短时记忆网络(lstm)等结构则用于更好地建模序列数据。此外,transformer架构的引入,如自注意力机制,进一步提升了语音识别的准确性。这些方法在一定程度上提高了识别准确率但是扔受限于模型的复杂性和训练数据的质量。
技术实现思路
1、发明目的:针对上述现有技术存在的问题,本发明目的在于提供一种可以减少计算复杂度、提高计算效率、提升语音识别准确率的基于可分离注意力和块掩蔽的语音识别方法和系统。
2、技术方案:为实现上述发明目的,本发明采用如下技术方案:
3、本发明所述的基于可分离注意力和块掩蔽的语音识别方法,其特征在于,包括:构建语音识别模型,对语音识别模型进行训练,使用训练完的模型进行语音识别;
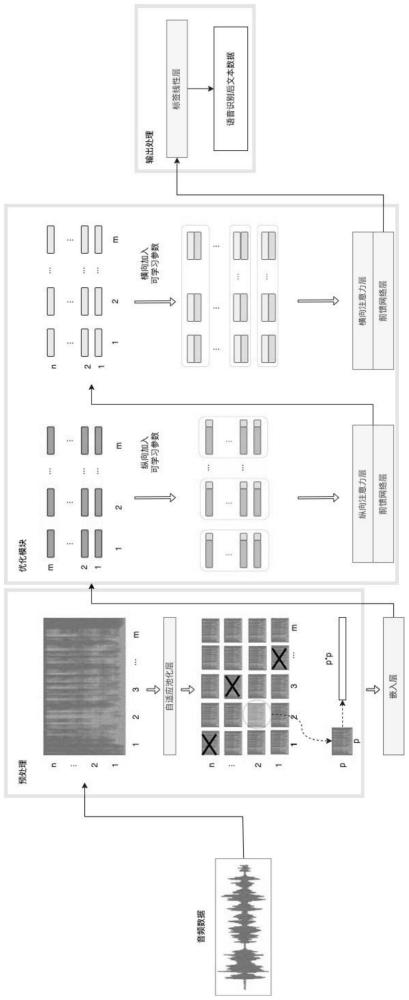
4、所述语音识别模型包括预处理模块,嵌入层,优化模块和线性层;
5、所述预处理模块,包括转化对齐模块,分块模块,块掩蔽模块和延展模块;
6、所述转化对齐模块,用于对原始语音进行转化,得到原始语音对应的频谱图,使用自适应池化层,将所有频谱图的时间维度进行整体对齐;所述分块模块,用于将频谱图分割成若干块序列;所述块掩蔽模块,用于随机丢弃部分块序列;所述延展模块,用于将剩余块序列进行延展;
7、所述优化模块,包括可分离注意力层和前馈网络层;
8、所述可分离注意力层,包括横向注意力层和纵向注意力层。
9、进一步地,所述对原始语音进行转化,得到原始语音对应的频谱图,使用自适应池化层,将所有频谱图的时间维度进行整体对齐包括以下步骤:
10、通过短时傅里叶变换stft,将原始语音每个音频样本转化为二维时频矩阵,stft变换公式为:
11、
12、其中x[a]是语音的离散输入信号,w[]是窗函数,nx是stft长度,a是音频信号的时间索引,k是音频信号转换后的频率分量,j是虚数单位,h是帧索引,表示音频信号的时间窗口的位置,r为常数,e是自然常数;语音数据经过转化后获得对应的频谱图x∈rt×f,其中t代表频谱图的时间维度的大小,f代表频谱图的频率维度的大小;
13、将每个batch内部不同长度的频谱图在时域上对齐,并记录原始有效长度,获得其中lmax代表每个batch中最长的语音频谱图的时间长度;
14、使用自适应池化层,将所有batch之间的频谱图的时间维度进行整体对齐,
15、xpooling=adaptivepooling(xalign)
16、得到池化后的频谱图xpooling∈rl×f,其中l表示经过自适应池化层后的频谱图长度。
17、进一步地,所述分块模块,将池化后的频谱图xpooling∈rl×f分割成p×p大小的块序列,其中l表示经过自适应池化层后的频谱图长度,f代表频谱图的频率维度的大小,p的大小需要被l和f整除,得到数量为m×n的块序列,其中m为横向块序列数量,n为纵向块序列数量。
18、进一步地,所述的块掩蔽模块,随机丢弃部分块序列的具体方法为,随机抽取一部分块序列并丢弃,随机方式与位置无关;或随机丢弃频谱图中某几个整列/整行提取的块。
19、进一步地,所述延展模块,将剩余每个块序列延展为一个一维序列,每个一维序列长度为p2,
20、xpatch=extend(slicing(xpooling))
21、xpooling为池化后的频谱图,此时延展后的频谱图数据的张量表示为其中m为横向块序列数量,n为纵向块序列数量。
22、进一步地,所述嵌入层,将延展后的频谱图数据序列矩阵xpatch的维度p2扩展到d维,d为常量,
23、xmapping=linear(xpatch)
24、使输入数据从低维度映射到更高维度的特征空间,放大数据特征,获得扩展后的频谱图xmapping∈rm×n×d,其中m为横向块序列数量,n为纵向块序列数量。
25、进一步地,所述可分离注意力层包括横向注意力层和纵向注意力层,两者为统一模型结构,均采用一致的注意力机制,
26、xf=xmapping+paramf
27、
28、
29、
30、对扩展后的频谱图xmapping∈rm×n×d在频率维度上添加可学习参数paramf∈r1×n×d得到xf∈rm×n×d,再经过纵向多头注意力计算后得到再对在时间维度上添加可学习参数paramt∈rm×1×d,得到xt∈rm×n×d,经过横向多头注意力计算后输出其中d为常量,m为横向块序列数量,n为纵向块序列数量;
31、所述前馈网络层用于加深网络深度,使可分离注意力层学习结果分别经过一个前馈网络层和规范层后得到xnew∈rm×n×d,采用残差计算的方式,将新的输出与可分离注意力层学习结果相加得到最终的xfinal∈rm×n×d。
32、进一步地,所述线性层,对优化模块的结果xfinal∈rm×n×d经过线性层映射,将维度d转为原始的维度p2,并经过维度转换后得到xconvert∈rl×f,其中l=m×p,f=n×p,其中,d为常量,m为横向块序列数量,n为纵向块序列数量,l表示经过自适应池化层后的频谱图长度,f表示频谱图的频率维度的大小,再通过一个分类器即线性层,将l维度转为length大小,得到xlabel∈rlength×f,其中length大小表示数据集中所出现的所有的去重后的文字的数量。
33、进一步地,所述对语音识别模型进行训练,将ctc损失函数应用于模型编码器的输出,计算模型的预测与真实文本标签之前的差异,将语音在时间上的帧序列和相应的转录文字序列在模型训练过程中自动对齐;使用随机梯度下降法最小化ctc损失,更新模型的权重参数,完成模型训练。
34、基于相同的发明构思,本发明还提供了一种计算机系统,其特征在于,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述计算机程序被加载至处理器时实现上述任一项所述的基于可分离注意力和块掩蔽的语音识别方法的步骤。
35、有益效果:本发明所提出的基于可分离注意力和块掩蔽的语音识别方法,能够更加有效地捕捉输入语音信号中长语音序列的上下文依赖关系,提高识别准确率;通过对部分数据块进行掩蔽,以提高模型的计算效率且不影响最终的识别准确度,对于移动端语音识别的工业化落地有较大的现实意义。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21625.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表