一种音色迁移训练方法、语音转换系统和电子装置与流程
- 国知局
- 2024-06-21 11:26:58
本申请涉及语音识别领域,特别涉及一种音色迁移训练方法、语音转换系统和电子装置。
背景技术:
1、语音风格迁移或者音色迁移通常在变声系统、加密系统、语音聊天、游戏等场景中得到应用,将一个语音风格的声音通过变声器等方法,以其他语音风格或者目标的语音风格输出,从而在保持语义不变的情况下,可以隐藏用户的身份信息或者增加娱乐效果等。
2、现有技术中,实现音色迁移的方法主要分为训练模型以及使用,具体如下:
3、一、训练模型
4、为了获得足够的测试样本,需要使用大量源说话人和目标说话人的语音,每人至少半小时以上,然后训练变声器算法模型,分离说话人的音色和内容。
5、二、使用
6、在使用阶段:
7、首先,确保变声器模型中存在源说话人和目标说话人的音色矢量,
8、然后,分离源说话人的语音为音色矢量和内容矩阵,保留内容,舍弃音色。
9、最后,把目标说话人的音色矢量与上一步得到的内容结合,生成变声后的语音。
10、在游戏的业务场景中,通常目标说话人经常是游戏角色,有固定的音色,且此音色被广大玩家所接受和认可,因此任务是把其他说话人的音色变为目标说话人的音色。
11、对于在游戏的这类场景中,存在以下现实的不足和缺陷:
12、1、新游戏项目在初期难以积累大量语音,使得提供音色的目标说话人数据不足,模型无法很好地提取目标音色;
13、2、源说话人的音色也不多,特别是在招募声替,使用临时声音演员的情况下,大量采集源说话人的音色不现实,而且基于经济成本的考虑,大多数情况只有1分钟左右的录音。
14、基于上述的不足和缺陷,目前在业界会的解决方案是使用一种称为any-to-any的变声器模型来试图解决此问题,此方法允许源说话人或目标说话人不在训练模型用的数据里,然后使用较短的音频提取音色,但是此种模型难以很好地建立说话人音色,得到的音色结果品质难以达到商用标准。
技术实现思路
1、为解决上述问题,本发明提供一种音色迁移方法,包括如下步骤:
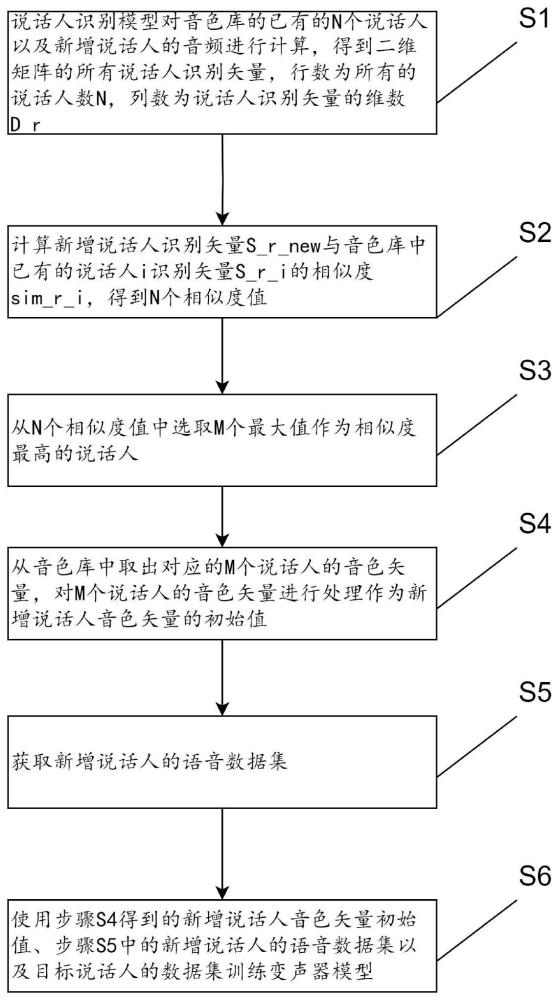
2、s i:说话人识别模型对音色库的已有说话人以及新增说话人的音频进行计算,得到二维矩阵的所有说话人识别矢量,行数为所有的说话人数n,列数为说话人识别矢量的维数d_r;
3、s2:计算新增说话人识别矢量s_r_new与音色库中已有的说话人i识别矢量s_r_i的相似度s im_r_i,得到n个相似度值;
4、s3:从n个相似度值中选取m个最大值作为相似度最高的说话人;
5、s4:从音色库中取出对应的m个说话人的音色矢量,对m个说话人的音色矢量进行处理作为新增说话人音色矢量的初始值。
6、s5:获取新增说话人的语音数据集;
7、s6:使用步骤s4得到的新增说话人音色矢量初始值、步骤s5中的新增说话人的语音数据集以及目标说话人的数据集训练变声器模型。
8、进一步地,步骤s2中,计算相似度s im_r_i的公式为:
9、s im_r_i=(s_r_new·s_r_i)/(||s_r_new||·||s_r_i||)
10、其中1<=i<=n,操作“·”为内积,操作||...||为取模,s im_r_i为一个取值范围在0到1之间的值,0代表新增说话人和说话人i的语音完全不相似,1代表他们说话声音完全一致。
11、进一步地,步骤s1中,对新增说话人的音频进行计算时,若新增说话人的语音为2条以上的语音文件,则分别进行计算后取平均值。
12、进一步地,步骤s4中:对m个说话人的音色矢量进行处理的方法为对m个说话人的音色矢量求平均值,该平均值作为新增说话人音色矢量的初始值。
13、本发明还提供一种用于训练音色迁移的神经网络系统,包括说话人识别模型以及变声器模型,所述神经网络系统为所述音色迁移训练方法得到。
14、本发明还提供一种语音转换方法,所述的神经网络系统,包括如下步骤:
15、获取源说话人语音信息并进行编码处理;
16、分离源说话人的语音信息为音色矢量矩阵和内容矩阵;
17、将分离得到的内容矩阵以及目标说话人的音色矢量进行融合,得到目标说话人的语音信息。
18、本发明还提供一种语音转换系统,包括说话人识别单元、变声单元、融合单元,其中:
19、说话人识别单元用以获取源说话人语音信息并进行编码处理;
20、变声单元用以分离源说话人的语音信息为音色矢量矩阵和内容矩阵;
21、融合单元用以将分离得到的内容矩阵以及目标说话人的音色矢量进行融合,得到目标说话人的语音信息。
22、本发明还一种计算机存储介质,所述计算机存储介质可存储有可执行程序,当所述可执行程序在计算机上运行时,所述计算机执行上述任一所述的音色迁移方法。
23、本发明还一种电子装置,所述电子装置包括处理器以及存储器,所述存储器用于存储可执行程序,所述处理器用于执行所述可执行程序以实现上述的音色迁移方法。
24、为了对本发明有更清楚全面的了解,下面结合附图,对本发明的具体实施方式进行详细描述。
技术特征:1.一种音色迁移训练方法,应用于神经网络系统中,其特征在于,包括如下步骤:
2.如权利要求1中所述的训练方法,其特征在于,步骤s2中,计算相似度sim_r_i的公式为:
3.如权利要求1中所述的训练方法,其特征在于,步骤s1中,对新增说话人的音频进行计算时,若新增说话人的语音为2条以上的语音文件,则分别进行计算后取平均值。
4.如权利要求1中所述的训练方法,其特征在于,步骤s4中:对m个说话人的音色矢量进行处理的方法为对m个说话人的音色矢量求平均值,该平均值作为新增说话人音色矢量的初始值。
5.一种用于训练音色迁移的神经网络系统,包括说话人识别模型以及变声器模型,其特征是,所述神经网络系统为权利要求1至4至任一所述音色迁移训练方法得到。
6.一种语音转换方法,其特征是,应用于权利要求4所述的神经网络系统,包括如下步骤:
7.一种语音转换系统,其特征是,包括说话人识别单元、变声单元、融合单元,其中:
8.一种计算机存储介质,所述计算机存储介质可存储有可执行程序,当所述可执行程序在计算机上运行时,所述计算机执行权利要求6所述的音色迁移方法。
9.一种电子装置,其特征在于,所述电子装置包括处理器以及存储器,所述存储器用于存储可执行程序,所述处理器用于执行所述可执行程序以实现权利要求6所述的音色迁移方法。
技术总结本发明提供一种音色迁移训练方法、语音转换系统和电子装置,其音色迁移训练方法包括,SI:说话人识别模型对音色库的已有的N个说话人以及新增说话人的音频进行计算;S2:计算新增说话人与音色库中已有的说话人的相似度sim_r_i,得到N个相似度值;S3:从N个相似度值中选取M个最大值作为相似度最高的说话人;S4:从音色库中取出对应的M个说话人的音色矢量,对M个说话人的音色矢量进行处理作为新增说话人音色矢量的初始值;S5:获取新增说话人的语音数据集;S6:使用S4和S5的结果以及目标说话人的数据集进行训练。本发明能够通过少量数据让变声器模型训练出足够优质的新音色矢量,并且实现高品质变声。技术研发人员:刘嘉受保护的技术使用者:上海暖叠网络科技有限公司技术研发日:技术公布日:2024/2/8本文地址:https://www.jishuxx.com/zhuanli/20240618/21591.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。