用户自主个性化文本转语音的声音生成的制作方法
- 国知局
- 2024-06-21 11:26:56
本公开总体上涉及文本转语音(text-to-speech)的声音生成,并且在提供用户自主个性化文本转语音的声音生成方法方面找到了特定的(尽管不是排他性的)实用性。
背景技术:
1、基于音频的内容项比基于文本的内容项具有更高的进入壁垒。例如,缺乏记录和编辑设备可能会阻碍用户向在线系统提供基于音频的内容项。音频录制的质量可能会基于用于录制音频片段的装置和录制音频片段的环境而有很大差异。另外,编辑音频片段比编辑文本更困难。与可被轻易修改的文本不同,如果希望改变音频片段,则用户可能需要重新录制音频片段以避免给基于音频的内容项引入瑕疵(artifact)。
2、在线系统中的基于音频的内容项的另一个进入壁垒是:很多人对收听其声音的录音感到不舒服。与一个人听声音录音中的他或她自己的声音时相比,该人在说话时听他或她自己的声音时,该人的声音通常听起来是不同的。例如,与一个人感知他或她自己的声音相比,人的声音录音可能会显得具有更高的音调。由于声音录音听起来与人所认为的他或她自己的声音不同,因此人在收听声音录音时可能会感到不舒服。
技术实现思路
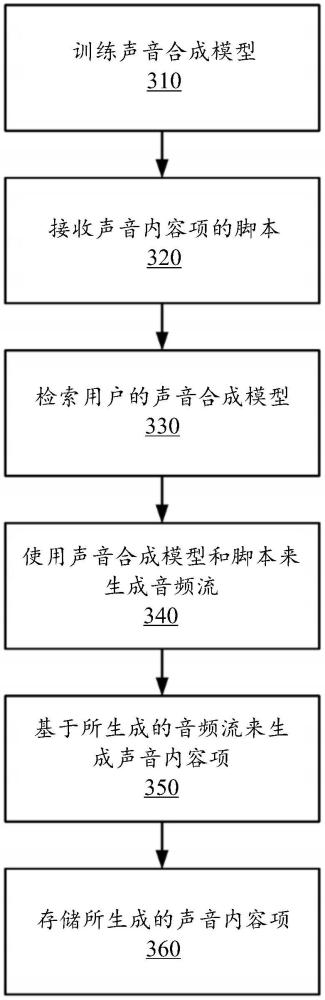
1、为了降低基于音频的内容项的进入壁垒,在线系统允许用户使用所生成的声音合成模型来生成基于音频的内容项以模仿该用户的声音。在线系统接收来自发布用户的客户端设备的基于声音的内容项的脚本。在线系统检索存储在发布用户的用户资料中的声音合成模型,且使用所检索到的声音合成模型并基于所接收到的脚本来生成合成音频流。在线系统向发布用户呈现所生成的合成音频流,并接收用于修改合成音频流的指令。在线系统基于所接收到的指令生成第二音频流,并基于所生成的第二音频流编写基于声音的内容项。
2、根据第一方面,提供了一种方法,该方法包括:接收来自在线系统的发布用户的客户端设备的基于声音的内容项的脚本;检索存储在该发布用户的用户资料中的声音合成模型,该声音合成模型至少基于该发布用户的多个声音样本而被训练;使用所检索到的声音合成模型并基于所接收到的脚本来生成合成音频流;向发布用户呈现所生成的合成音频流;接收用于修改该合成音频流的指令;基于所接收到的指令生成第二音频流;基于所生成的第二音频流编写基于声音的内容项;以及向在线系统的观看用户呈现该基于声音的内容项。
3、该脚本可以包括对基于声音的内容项的情绪的指示。检索声音合成模型可以包括:从存储在发布用户的用户资料中的一组声音合成模型中选择该声音合成模型,对该声音合成模型的选择是基于该基于声音的内容项的情绪的。
4、生成第二音频流可以包括:检索存储在发布用户的用户资料中的第二声音合成模型;以及使用所检索到的第二声音合成模型并基于所接收到的脚本和所接收到的用于修改合成音频的指令来生成该第二音频流。
5、该方法还可以包括:接收发布用户的所述多个声音样本;使用该发布用户的该多个声音样本生成声音合成模型;使用该发布用户的该多个声音样本生成鉴别器模型,该鉴别器模型用于确定音频流是否包括该发布用户的声音记录;使用声音合成模型生成测试音频流;使用鉴别器模型确定该测试音频流的分类;以及基于所确定的测试音频流的分类来改进声音合成模型和鉴别器模型。
6、该方法还可以包括:将声音合成模型存储在发布用户的用户资料中。
7、用于修改合成音频流的指令可以包括以下中的至少一者:用于改变所生成的合成音频流中的一个或多个词语或短语的语调或发音的指令,用于在所生成的音频流中添加停顿的指令,用于移除所生成的合成音频流中的停顿的指令,用于改变所生成的合成音频流的至少一部分的节奏的指令,以及用于向所生成的合成音频流添加音效的指令。
8、该方法还可以包括:基于所接收到的脚本生成音素流,其中,合成音频流是基于所生成的音素流、通过使用所检索到的声音合成模型而生成的。
9、该方法还可以包括:向发布用户呈现音素流;以及接收来自该发布用户的客户端设备的经修改的音素流,其中,合成音频流是基于所接收到的经修改的音素流、通过使用所检索到的声音合成模型而生成的。
10、根据第二方面,提供了一种计算机可读存储介质,该计算机可读存储介质包括指令,所述指令在被计算机执行时使得该计算机执行第一方面所述的方法。该介质可以是非暂态的。
11、根据第三方面,提供了一种系统,该系统包括:用户资料存储库,该用户资料存储库被配置为存储在线系统的每个用户的用户资料,每个用户资料包括至少基于该用户的多个声音样本而被训练的一组声音合成模型;以及基于声音的内容项生成器,该基于声音的内容项生成器被配置为执行第一方面所述的方法。
12、根据第四方面,提供了一种计算机程序,该计算机程序包括指令,所述指令在该程序被计算机执行时使得该计算机执行第一方面所述的方法。
技术特征:1.一种方法,包括:
2.根据权利要求1所述的方法,其中,所述脚本包括对所述基于声音的内容项的情绪的指示,并且其中,检索所述声音合成模型包括:
3.根据权利要求1或2所述的方法,其中,生成所述第二音频流包括:检索存储在所述发布用户的所述用户资料中的第二声音合成模型;以及
4.根据任一项前述权利要求所述的方法,还包括:
5.根据权利要求4所述的方法,还包括:
6.根据任一项前述权利要求所述的方法,其中,用于修改所述合成音频流的所述指令包括以下中的至少一者:用于改变所生成的所述合成音频流中的一个或多个词语或短语的语调或发音的指令,用于在所生成的所述音频流中添加停顿的指令,用于移除所生成的所述合成音频流中的停顿的指令,用于改变所生成的所述合成音频流的至少一部分的节奏的指令,以及用于向所生成的所述合成音频流添加音效的指令。
7.根据任一项前述权利要求所述的方法,还包括:
8.根据权利要求7所述的方法,还包括:
9.一种计算机可读存储介质,包括指令,所述指令在被计算机执行时使得所述计算机执行如任一项前述权利要求所述的方法。
10.一种系统,包括:
11.一种计算机程序,包括指令,所述指令在所述程序被计算机执行时使所述计算机执行如权利要求1至8中任一项所述的方法。
技术总结在线系统接收来自发布用户的客户端设备的基于声音的内容项的脚本。在线系统检索存储在发布用户的用户资料中的声音合成模型,且使用所检索到的声音合成模型并基于所接收到的脚本来生成合成音频流。在线系统向发布用户呈现所生成的合成音频流,并接收用于修改合成音频流的指令。在线系统基于所接收到的指令生成第二音频流,并基于所生成的第二音频流编写基于声音的内容项。然后向观看用户呈现该基于声音的内容项。技术研发人员:特伦特·理查德·沃基维奇,玛丽亚·费尔南德斯·瓜哈多受保护的技术使用者:元平台公司技术研发日:技术公布日:2024/2/8本文地址:https://www.jishuxx.com/zhuanli/20240618/21587.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表