基于多模态的语音情感识别方法和系统
- 国知局
- 2024-06-21 11:26:52
本发明涉及机器学习和人机交互,特别涉及一种基于多模态的语音情感识别方法和系统。
背景技术:
1、随着网络的发展,情感识别在交通安全,智能交互,医疗健康,信息安全等领域也越来越重要。通过互联网,人们可以通过视频,语音,文本,图片等多样化的信息进行自身情感的表达。在现实生活中,人们可以利用情感进行详细的分析,获取有用的信息。例如在信息安全领域,也可以通过对嫌疑人的情感识别,判断对方的情感波动程度和情感转化方式,来识别对方是否涉嫌欺骗,间谍活动等违法行为。上述的情景大多都涉及多个模态,如警察的执法记录仪就采集了在执法过程中人物的声学信息和讲话内容的文本信息以及人物图像等多模态信息,如何利用好上述多模态信息,将多模态特征进行信息融合是当前研究的热点。
2、本专利注重在公安领域的多模态语音情感识别,特别的,针对执法记录仪记录的处警数据进行情感分析。在警务人员出警过程中,会打开执法记录仪记录下执法的详细过程。里面包含了当事人、民警等人的语音和文本等多模态的信息。
3、利用这些多模态的信息进行情感分析,有利于对涉案人员进行人物情感建模,分析人物的行为和表现,对案件进行辅助性决策。同时也可以帮助民警提升他们的沟通和情绪管理能力。
4、在多模态语音情感识别中,确实存在许多挑战和困难。在模型层面上,语音和文本之间存在较大的差异,包括嵌入表示和时间尺度的差异。如何关键,有效地将语音和文本进行融合。并且在细粒度的时间尺度对齐,以更好地融合两个领域的情感信息是目前面临的一大挑战。另一个挑战是语音和文本的语义信息不同。说话者的语调、语速等因素会导致同一个文本表达不同的情感。此外,由于缺乏情感解析和提炼,不同的嵌入空间可能会不兼容或存在冲突。在实际案例中,执法记录仪的语音数据包含大量的噪音,并且一段语音数据中存在不同人员说话的情况。这造成了对不同人物的情感分析比较的困难。如何将数据进行清晰,剥离出有效部分,同时区分多个讲述人的声音,也是目前面临的困难。
技术实现思路
1、本发明针对现有技术的缺陷,提供了一种基于多模态的语音情感识别方法和系统。首先对数据进行了预处理。首先对音频数据进行了降噪处理,剥离出了音频数据中的噪音部分。对将剥离后的语音进行分段,获取其中的声纹信息并通过聚类得到不同人物的声音。将得到的声音经过转译成为文本数据。利用语音和文本数据进行多模态的情感识别。本发明使用单模态和多模态相结合的方法,充分利用单模态情感信息,并结合多模态融合来捕捉模态之间的语义信息,这样可以提高情感分析的性能和准确性。模型包括单模态的情感学习、跨模态的情感融合学习。模型不仅可以独立的学习文本和语音各自的情感特征,也可以将文本和语音两种模态的特征进行融合,学习之间的情感和语义信息,大大提升了情感识别的准确度。
2、为了实现以上发明目的,本发明采取的技术方案如下:
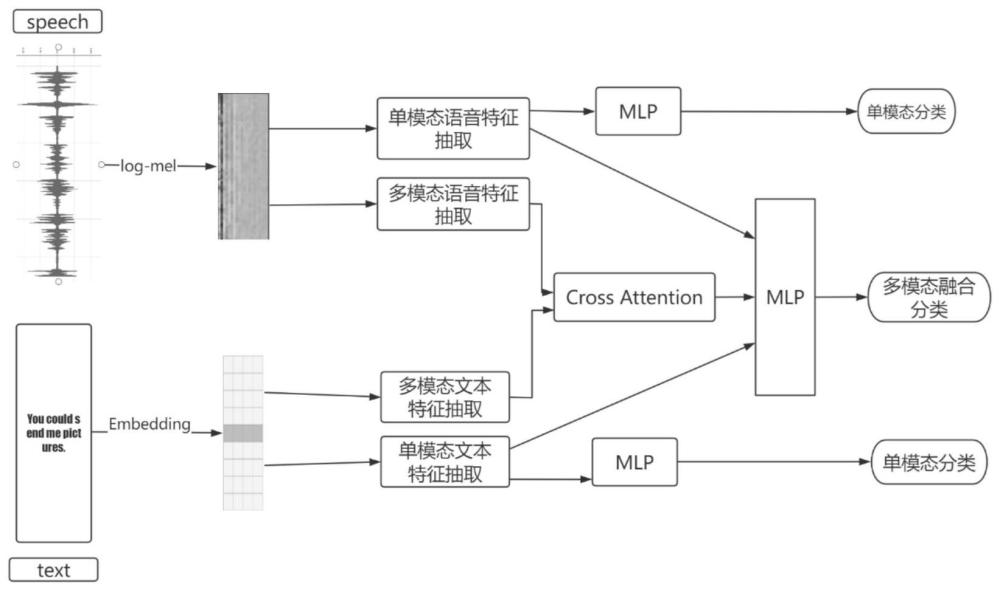
3、如图1所示,一种基于多模态的语音情感识别方法,包括以下步骤:
4、步骤一.对语音和文本数据进行预处理,将语音进行降噪和文本数据进行编码,转化为模型可以处理的形式;
5、步骤二.将文本数据输入到两个相同的特征提取层,获取单模态的文本情感信息和要进行融合的跨模态的文本情感信息;
6、步骤三.将语音数据输入到两个相同的特征提取层,获取单模态的语音情感信息和要进行融合的跨模态的语音情感信息;
7、步骤四.将步骤三提取出的单模态语音情感信息和步骤二提取的单模态文本情感信息送入各自的全连接层中,进行单模态的情感分类;
8、步骤五.将步骤三提取出的跨模态语音情感信息和步骤二提取的跨模态文本情感信息输入到跨模态的注意力层中,将两个模态情感的信息进行融合;
9、步骤六.将融合后的跨模态情感信息以及语音和文本的单模态情感特征一起输入到全连接层,进行跨模态的情感分类。
10、步骤七.使用训练好的模型对新的语音数据进行情感识别,在输出层得到情感分类结果。
11、进一步地,所述步骤一具体为:
12、11)对音频数据进行降噪处理。
13、12)对降噪后的语音数据进行切分。将每一句话分为一段音频。
14、13)将分段好的音频数据输入到声纹模型ecapa-tdnn中提取声纹信息,并将其聚类,选取合适的聚类个数,区分不同人的声音信息。并通过asr进行转移,获取文本信息。
15、14)将文本信息和音频信息进行编码,统一数据的长度。对数据进行切分或者补零,让其符合输入模型的长度。
16、进一步地,所述步骤二具体为:
17、21)将文本数据特征采用两个lstm来提取文本的长时间语义特征。lt表示语音特征的长度,ft表示语音特征的维度。
18、22)在lstm的特征提取之后,引入了由于transformer的encoder层的多头注意力机制,进一步的情感特征。
19、进一步地,所述步骤三具体为:
20、31)输入语音数据特征其中la表示语音特征的长度,fa表示语音特征的维度。利用lstm(long short-term memory)提取语音数据的时间特征,cnn(convolutional neural network)提取语音数据的空间特征,并将时间特征和空间特征相加,得到语音的初级特征h。
21、32)将初级特征h后划分为两个部分,与分别从正向和负向提取情感信息。
22、33)为了避免未来情感信息的干扰,并且提取长期特征,采用因果卷积网络来处理情感信息。在卷积之后,对数据进行归一化,并通过relu函数进行激活,并使用dropout进行处理。
23、34)对每一个时间步的两个输出与将其相加在一起并进行平均操作,采用卷积网络进行维度的对齐,处理不同说话人的语速和音调差异。
24、进一步地,所述步骤四具体为:
25、41)将步骤三提取出的单模态语音情感信息和步骤二提取的单模态文本情感信息送入到各自的全连接层中,得到两个(4,1)的结果输出。
26、42)将语音和文本的结果经过softmax层行概率归一化,softmax层将输出结果转化为概率分布,表示分别属于每个情感类别的概率,得到最后的分类输出。
27、43)根据分类输出和真实的标签结果,进行单模态的情感分类,并通过反向传播,训练全连接层和特征提取层。
28、进一步地,所述步骤五具体为:
29、51)使用步骤三提取的跨模态语音情感信息作为查询的输入,将步骤二的跨模态文本情感信息作为键和值的输入。各自的输入乘以矩阵xq,xk,xv,得到查询(q)、键(k)和值(v)。然后,根据公式(1)进行文本信息的融合:
30、att(q,k,v)=ω(qkt)v (1)
31、ω表示激活函数。
32、52)同样,再用步骤二的跨模态文本情感信息作为查询的输入,步骤三提取的跨模态语音情感信息作为键和值的输入。各自的输入乘以矩阵xq,xk,xv,得到查询(q)、键(k)和值(v)。再根据公式(1)进行语音信息的融合。
33、53)最后将两个融合后的情感向量连接再一起,得到最后的输出。
34、作为优选,在步骤五中采用了mse loss对融合后的特征进行相似性约束,来让两个模态的融合可以学习到更多的相关信息。
35、进一步地,所述步骤六具体为:
36、61)将步骤五融合后的跨模态情感信息以及步骤二与步骤三提取的单模态的情感信息连接在一起输入到全连接层中得到(4,1)的输出,并将结果经过softmax后得到分类的结果。
37、62)根据分类输出和真实的标签结果,进行跨模态的情感分类,并通过反向传播,训练全连接层和跨模态的特征提取层。
38、本发明还公开了一种基于多模态的语音情感识别系统,该系统能够用于实施上述的基于多模态的语音情感识别方法,具体的,包括:
39、数据预处理模块:对输入的语音和文本数据进行预处理,包括降噪处理语音数据和将文本数据编码为模型可处理的形式。
40、文本特征提取模块:将文本数据输入到两个相同的特征提取层,获取单模态的文本情感信息和要进行融合的跨模态的文本情感信息。
41、语音特征提取模块:将语音数据输入到两个相同的特征提取层,获取单模态的语音情感信息和要进行融合的跨模态的语音情感信息。
42、单模态情感分类模块:将步骤3提取出的单模态语音情感信息和步骤2提取的单模态文本情感信息送入各自的全连接层中,进行单模态的情感分类。
43、跨模态注意力融合模块:将步骤3提取出的跨模态语音情感信息和步骤2提取的跨模态文本情感信息输入到跨模态的注意力层中,将两个模态情感的信息进行融合。
44、跨模态情感分类模块:将融合后的跨模态情感信息以及语音和文本的单模态情感特征一起输入到全连接层,进行跨模态的情感分类。
45、情感识别模块:使用训练好的模型对新的语音数据进行情感识别,在输出层得到情感分类结果。
46、本发明还公开了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述基于多模态的语音情感识别方法。
47、本发明还公开了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述基于多模态的语音情感识别方法。
48、与现有技术相比,本发明的优点在于:
49、噪音鲁棒性:在实际应用中,本发明能够有效应对来自噪音环境的干扰,通过噪音去除算法和噪音抑制技术降低噪音对情感识别的影响,从而实现在嘈杂环境中的可靠情感识别。
50、多模态融合:本发明能够有效整合多模态数据,如语音、文本和图像等,充分利用不同模态的信息来提高情感识别的准确性。通过多模态融合,模型能够更全面地理解人的情感状态,进一步提升识别性能。
51、现实场景应用:本发明在警察执法实际场景中的应用具有实际意义。通过测试和验证,证明了模型在噪音环境下的出色性能表现。这种应用能够帮助警方更准确地判断和处理情感相关的事件,提高工作效率和决策水平。
52、数据差异性处理:本发明对训练数据和实际应用数据之间的差异进行处理,采用数据增强、领域适应和数据预处理等方法,确保模型在不同环境下具备鲁棒性和稳定性。这样可以更好地适应实际应用场景,提高模型的实用性和可靠性。
53、性能度量:本发明的性能度量使用加权精度和未加权精度作为实验指标,针对情感识别任务进行评估。经过训练和测试,本发明取得了较高的准确率,证明了多模态融合在情感识别中的有效性和优越性。消融实验结果也进一步验证了多模态融合比单模态效果更好的事实。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21578.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表