3D数字人的语音驱动方法、装置、存储介质及相关设备与流程
- 国知局
- 2024-06-21 11:26:48
本技术涉及语音驱动,尤其涉及一种3d数字人的语音驱动方法、装置、存储介质及相关设备。
背景技术:
1、近年来,由于gan、nerf的不断发展,以及元宇宙内容创作与生成的兴起,在电商、金融、影视、游戏和金融等行业与领域,人们对于构建可交互的数字人日渐迫切。数字人是指使用计算机技术、人工智能和虚拟现实等技术创建的人类仿真实体。它们可以拥有类似人类的外貌、智能和情感,并且可以通过自然语言交互与人类进行沟通和互动,为了实现更加真实、有趣和沟通友好的数字人交互体验,还可以通过语音驱动数字人说话。
2、现有技术中,使用语音驱动算法来驱动数字人说话时,一般是直接根据语音和参考人脸图像生成具有对应唇形的数字人人脸,具体过程主要是通过将语音映射到某一个中间模态,然后再将中间模态映射到口型,以此来进行二维渲染后得到数字人。但由于二维渲染的过程中缺少了三维信息,且映射的过程难以保证语音与口型的同步性,进而导致现有的技术方案存在嘴形丰富度低、嘴形同步性低等缺点,无法满足元宇宙3d场景数字人音频驱动唇形的需求。
技术实现思路
1、本技术的目的旨在至少能解决上述的技术缺陷之一,特别是现有技术中的语音驱动算法存在嘴形丰富度低、嘴形同步性低等缺点,无法满足元宇宙3d场景数字人音频驱动唇形的需求的技术缺陷。
2、本技术提供了一种3d数字人的语音驱动方法,所述方法包括:
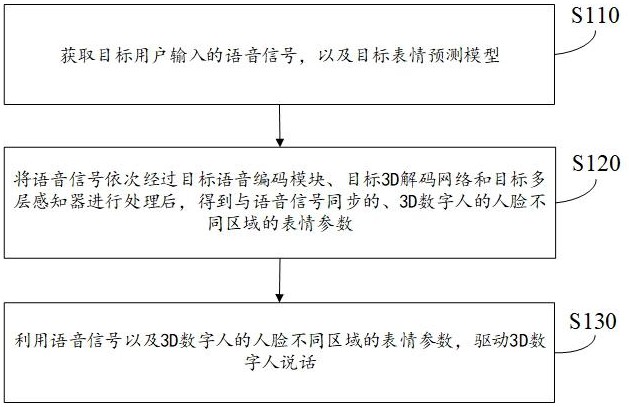
3、获取目标用户输入的语音信号,以及目标表情预测模型,其中,所述目标表情预测模型包括目标语音编码模块、目标3d解码网络和目标多层感知器;
4、将所述语音信号依次经过所述目标语音编码模块、所述目标3d解码网络和所述目标多层感知器进行处理后,得到与所述语音信号同步的、3d数字人的人脸不同区域的表情参数;
5、利用所述语音信号以及所述3d数字人的人脸不同区域的表情参数,驱动所述3d数字人说话。
6、可选地,所述将所述语音信号依次经过所述目标语音编码模块、所述目标3d解码网络和所述目标多层感知器进行处理后,得到与所述语音信号同步的、3d数字人的人脸不同区域的表情参数,包括:
7、利用所述目标语音编码模块生成与所述语音信号对应的音频特征后,通过所述目标3d解码网络生成与所述音频特征同步的唇形特征,其中,所述目标语音编码模块和所述目标3d解码网络是利用预设的目标音唇同步模型作为判别器训练得到的;
8、利用所述目标多层感知器将所述唇形特征转化为3d数字人的人脸不同区域的表情参数,其中,所述目标多层感知器是使用多个维度且相互解耦的3d人脸变形器的变形参数作为初始权重参数训练得到的。
9、可选地,所述目标语音编码模块为基于bert的编码网络,所述语音信号为具有时序关系的任意时长的语音特征;
10、所述将所述语音信号经过所述目标语音编码模块进行处理的过程,包括:
11、通过所述基于bert的编码网络提取所述语音特征中具有上下文信息、且时序信息相关联的目标语音特征。
12、可选地,所述目标表情预测模型还包括唇形风格映射模块;
13、所述将所述语音信号依次经过所述目标语音编码模块、所述目标3d解码网络和所述目标多层感知器进行处理的过程,包括:
14、将所述语音信号依次经过所述目标语音编码模块和所述目标3d解码网络进行处理后,得到对应的唇形特征;
15、通过所述唇形风格映射模块将所述唇形特征映射到对应的唇形风格上,并将带有唇形风格的唇形特征输入至所述目标多层感知器中进行处理。
16、可选地,所述目标表情预测模型的训练过程,包括:
17、获取人脸视频数据集,并提取所述人脸视频数据集中每个视频数据的每帧视频对应的样本语音信号和真实表情参数;
18、确定初始表情预测模型,所述初始表情预测模型包括初始语音编码模块、初始3d解码网络和初始多层感知器;
19、利用所述初始语音编码模块生成与所述样本语音信号对应的预测音频特征后,通过所述初始3d解码网络提取所述样本语音信号对应的视频帧中的预测嘴形图像;
20、通过所述初始多层感知器将所述预测嘴形图像转化为3d数字人的人脸不同区域的预测表情参数;
21、以所述预测音频特征与所述预测嘴形图像同步、所述预测表情参数趋近于所述真实表情参数为目标,对所述初始表情预测模型的参数进行更新;
22、当达到预设的第一训练条件时,将训练后的初始表情预测模型作为目标表情预测模型。
23、可选地,所述以所述预测音频特征与所述预测嘴形图像同步、所述预测表情参数趋近于所述真实表情参数为目标,对所述初始表情预测模型的参数进行更新,包括:
24、利用预设的目标音唇同步模型计算所述预测音频特征与所述预测嘴形图像之间的生成器损失;
25、利用预设的全局及局部损失函数计算所述预测表情参数与所述真实表情参数之间的表情损失;
26、根据所述生成器损失和所述表情损失对所述初始表情预测模型的参数进行更新。
27、可选地,所述利用预设的目标音唇同步模型计算所述预测音频特征与所述预测嘴形图像之间的生成器损失,包括:
28、获取目标音唇同步模型,所述目标音唇同步模型包括目标音频同步编码模块和目标唇形同步编码模块;
29、通过所述目标音频同步编码模块提取所述预测音频特征中的音频同步特征,以及,通过所述目标唇形同步编码模块提取所述预测嘴形图像中的唇形同步特征;
30、获取所述目标音唇同步模型在训练阶段计算得到的、与所述样本语音信号对应的视频数据的多个同步损失值;
31、对多个同步损失值进行对数运算后,将对数运算结果作为所述音频同步特征与所述唇形同步特征之间的生成器损失。
32、可选地,所述目标音唇同步模型的训练过程,包括:
33、提取所述人脸视频数据集中每个视频数据的每帧视频对应的样本音频和样本嘴形图像;
34、确定初始音唇同步模型,所述初始音唇同步模型包括初始音频同步编码模块和初始唇形同步编码模块;
35、通过所述初始音频同步编码模块提取所述样本音频中的预测音频同步特征,以及,通过所述初始唇形同步编码模块提取所述样本嘴形图像中的预测唇形同步特征;
36、以所述预测音频同步特征与所述预测唇形同步特征具有同步关系为目标,对所述初始音唇同步模型的参数进行更新;
37、当达到预设的第二训练条件时,将训练后的初始音唇同步模型作为目标音唇同步模型。
38、可选地,所述以所述预测音频同步特征与所述预测唇形同步特征具有同步关系为目标,对所述初始音唇同步模型的参数进行更新,包括:
39、利用预设的余弦损失函数计算所述预测音频同步特征与所述预测唇形同步特征之间的同步损失值;
40、根据所述同步损失值对所述初始音唇同步模型的参数进行更新。
41、可选地,所述预测表情参数包括预测3d顶点坐标和预测嘴部三角面法线,所述真实表情参数包括真实3d顶点坐标和真实嘴部三角面法线;
42、所述利用预设的全局及局部损失函数计算所述预测表情参数与所述真实表情参数之间的表情损失,包括:
43、通过预设的全局损失函数计算所述预测3d顶点坐标与所述真实3d顶点坐标之间的全局损失;
44、通过预设的局部损失函数计算所述预测嘴部三角面法线与所述真实嘴部三角面法线之间的局部损失。
45、可选地,所述预测嘴部三角面法线的生成过程,包括:
46、提取所述预测3d顶点坐标中嘴部的顶点坐标,并形成嘴部顶点坐标集合;
47、将所述嘴部顶点坐标集合中相邻的三个顶点组成一个三角面,得到多个三角面;
48、计算每个三角面的法线后,形成预测嘴部三角面法线。
49、可选地,所述真实嘴部三角面法线的生成过程,包括:
50、获取所述预测嘴部三角面法线中各个三角面的法线;
51、使用icp算法将各个法线进行统一变换并对齐后,得到对齐结果;
52、根据所述对齐结果确定所述真实3d顶点坐标中与所述预测嘴部三角面法线对应的真实嘴部三角面法线。
53、可选地,所述利用所述目标语音编码模块生成与所述语音信号对应的音频特征之前,还包括:
54、对所述语音信号进行预处理,并将预处理后的语音信号进行快速傅里叶变换,得到对应的功率谱;
55、将mel滤波器组应用于所述功率谱,并求取所述mel滤波器组能量的对数后,对所述mel滤波器组能量的对数进行离散余弦变换,得到所述mel滤波器组的dct系数;
56、将所述dct系数第2~13维的数值保留,其他维度的数值丢弃,得到所述语音信号对应的mfcc特征,并将所述mfcc特征作为所述目标语音编码模块的输入特征。
57、可选地,所述利用所述初始语音编码模块生成与所述样本语音信号对应的音频特征之前,还包括:
58、对所述样本语音信号进行预处理,并将预处理后的样本语音信号进行快速傅里叶变换,得到对应的功率谱;
59、将mel滤波器组应用于所述功率谱,并求取所述mel滤波器组能量的对数后,对所述mel滤波器组能量的对数进行离散余弦变换,得到所述mel滤波器组的dct系数;
60、将所述dct系数第2~13维的数值保留,其他维度的数值丢弃,得到所述样本语音信号对应的mfcc特征,并将所述mfcc特征作为所述初始语音编码模块的输入特征。
61、本技术提供了一种3d数字人的语音驱动装置,包括:
62、数据获取模块,用于获取目标用户输入的语音信号,以及目标表情预测模型,其中,所述目标表情预测模型包括目标语音编码模块、目标3d解码网络和目标多层感知器;
63、表情参数确定模块,用于将所述语音信号依次经过所述目标语音编码模块、所述目标3d解码网络和所述目标多层感知器进行处理后,得到与所述语音信号同步的、3d数字人的人脸不同区域的表情参数;
64、数字人驱动模块,用于利用所述语音信号以及所述3d数字人的人脸不同区域的表情参数,驱动所述3d数字人说话。
65、本技术提供了一种存储介质,所述存储介质中存储有计算机可读指令,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行如上述实施例中任一项所述3d数字人的语音驱动方法的步骤。
66、本技术提供了一种计算机设备,包括:一个或多个处理器,以及存储器;
67、所述存储器中存储有计算机可读指令,所述计算机可读指令被所述一个或多个处理器执行时,执行如上述实施例中任一项所述3d数字人的语音驱动方法的步骤。
68、从以上技术方案可以看出,本技术实施例具有以下优点:
69、本技术提供的3d数字人的语音驱动方法、装置、存储介质及相关设备,当获取到目标用户输入的语音信号时,可以获取目标表情预测模型,然后将语音信号输入至目标表情预测模型中,由于本技术的目标表情预测模型不仅包括了目标语音编码模块和目标3d解码网络,还包括了目标多层感知器,这样既可以利用目标语音编码模块生成与语音信号对应的音频特征后,通过目标3d解码网络生成与音频特征同步的唇形特征,又可以利用目标多层感知器将唇形特征转化为3d数字人的人脸不同区域的表情参数;利用该表情参数以及语音信号驱动3d数字人说话时,既可以通过人脸不同区域的表情参数来生成嘴形丰富度较高的3d数字人,又可以控制3d数字人说话时语音与嘴形的同步性,为用户提供接近于实时与真人自然交流的体验,从而在极大程度上提升用户的互动感与沉浸感,满足元宇宙3d场景数字人音频驱动唇形的需求。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21572.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表