基于通道注意力机制与AH-Softmax的变压器声纹识别方法与流程
- 国知局
- 2024-06-21 11:26:29
本发明涉及电力设备,尤其是一种基于通道注意力机制与ah-softmax的变压器声纹识别方法。
背景技术:
1、电力变压器作为电力系统中最关键的设备之一,承担着电压变换,电能传输等艰巨的任务,因此,保证变压器正常稳定的工作对于整个电力系统的安全运行有着非常重要的意义。当变压器出现不同故障时,变压器发出的不同声音信号包含了非常丰富的状态信息,能很大程度反应变压器的运行状态。随着人工智能的快速发展,利用声纹识别技术对变压器类设备机械状态的故障诊断成为新的研究热点。
2、传统的识别方法包括bp神经网络、svm支持向量机、cnn模型和lstm模型在内的算法在速度和准确度方面已经无法满足现代电力系统的需求,在多重因素的挑战下,传统的识别方法的短板进一步凸显,具体体现在:变压器声纹类型主要分为正常声纹信号和异常声纹信号,正常声纹信号有正常工作声、正常工作声+人声、正常工作声+鸟声等类型、正常工作声+雨声,异常声纹信号有击穿、偏磁工况、短路冲击、局部放电等类型,由此可以看出变压器声纹种类过多。但是目前传统识别方法对于变压器声纹的识别主要存在速度较慢和准确度较低的问题,一方面因为传统识别模型在特征提取时往往对应着下采样,图像长宽维度降低的同时,通道数会大大增多,在众多的通道中,包含许多类型的信息,有些通道与变压器声纹的相关性高、有些低、甚至有些几乎没有。由于存在与变压器声纹的相关性低和没有相关性的通道,影响了识别模型对于变压器声纹识别的准确度,并加长了其识别时间;另一方面由于传统识别模型的分类函数部分通常以纯净样本为前提,即不包含噪音,而实际应用中,样本采集通常难以去除外部噪音,这部分样本对训练效果产生了负面影响,降低了识别模型对于变压器声纹的分类准确度。
技术实现思路
1、为解决变压器声纹的识别速度较慢和识别准确度较低的问题,本发明的目的在于提供一种能够快速准确地识别出不同类型的变压器声纹信号的基于通道注意力机制与ah-softmax的变压器声纹识别方法。
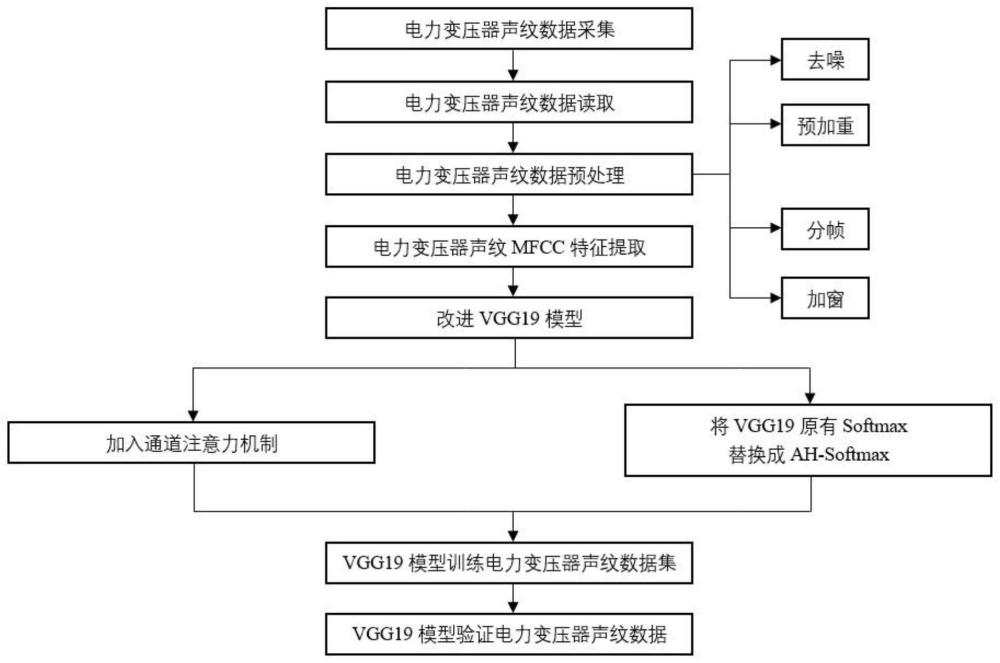
2、为实现上述目的,本发明采用了以下技术方案:一种基于通道注意力机制与ah-softmax的变压器声纹识别方法,该方法包括下列顺序的步骤:
3、(1)利用r个声纹采集传感器实时采集任意一台电力变压器的音频数据,所采集到的每个音频数据均对应一个文件地址;获取音频数据的二进制格式的声纹数据以及采样频率;
4、(2)对二进制格式的声纹数据进行预处理,得到预处理之后的声纹数据ω(n)并组成数据集,将数据集按比例划分成训练集和验证集;
5、(3)利用梅尔频率倒谱系数mfcc对训练集中的声纹数据进行特征提取,得到声纹特征并组成声纹特征训练集;
6、(4)对vgg19模型进行改进,得到改进后的vgg19模型;
7、(5)利用声纹特征训练集对改进后的vgg19模型进行训练,得到训练后的vgg19模型,再通过验证集对训练后的vgg19模型进行验证;
8、(6)将待识别的电力变压器的音频数据输入训练后的vgg19模型,识别出电力变压器声纹类型。
9、所述步骤(2)具体包括以下步骤:
10、(2a)去噪:利用基于音频幅值的端点检测方法,去掉二进制格式的声纹数据的静音部分和噪声部分,得到剩余部分;
11、(2b)预加重:利用预加重方法对剩余部分的损失进行补偿,设输入的二进制格式的声纹数据为s(n),通过一阶fir滤波器后的音频为公式如式(1)所示:
12、
13、式(1)中,a为常数,取0.96;
14、(2c)分帧:利用分帧方法将音频分成大小固定的n段语音信号,每一段语音信号为一帧,帧长frame取25ms;分帧采用交叠分段的方法,前一帧和后一帧的交叠部分为帧移,帧移与帧长的比值m取0.5;对长为n的语音信号进行分帧,如式(2)所示:
15、
16、数据被分成n帧,每一帧fn的位置为[m*frame*(n-1),m*frame*(n-1)+frame],如果最后一帧的末位置(frame*(n-1)+frame)>n,则超出部分用0填补;
17、(2d)加窗:将每一帧带入窗函数,所述窗函数选取海明窗,其表达式如式(3)所示:
18、
19、式中,rm(n)为第n帧的声纹数据,ω(n)为预处理之后的声纹数据。
20、所述步骤(3)具体包括以下步骤:
21、(3a)利用快速傅里叶变换fft将预处理之后的声纹数据ω(n)分解成两个子信号:偶数样本点信号和奇数样本点信号再将偶数样本点信号和奇数样本点信号的求和项等价为两个长度为的离散傅里叶变换dft,其具体计算过程为:对于任意k都进行n次加法操作,离散傅里叶变换dft共有n2次乘法操作;对于任意k都进行n-1次加法操作,离散傅里叶变换dft共有n(k-1)次加法操作;快速傅里叶变换fft共有n(log2n-1)次乘法操作和n log2n次加法操作;
22、(3b)利用梅尔滤波器组进行以下操作:
23、(3b1)确定经过步骤(3a)处理后的声纹数据的最低频率为0hz,最高频率为fs,梅尔滤波器的个数m为23;
24、(3b2)将最低频率和最高频率分别转换为各自的梅尔刻度low_mel和high_mel;
25、(3b3)计算两个相邻的梅尔滤波器的中心梅尔频率的距离dmel,如式(4)所示:
26、
27、式中,high_mel为最高频率的梅尔刻度,low_mel为最低频率的梅尔刻度,m为梅尔滤波器个数;
28、(3c)利用对数运算得到经过梅尔滤波器组的语音信号的频谱如式(6)所示:
29、
30、式中,h(k)为高频频谱函数,e(k)为低频频谱函数;
31、只考虑幅度,如式(7)所示:
32、
33、两边取对数,如式(8)所示:
34、
35、再在两边取逆傅里叶变换得到,如式(9)所示:
36、
37、(3d)利用离散余弦变换dct将语音信号长度扩大成原来的两倍变成2n,为让扩大后的信号关于0对称,把整个延拓的信号向右平移0.5个单位,最终dct变换公式为式(10):
38、
39、其中,n为语音信号长度,为第x个频谱,当u=0时,否则,u为广义频率;
40、(3e)将经过离散余弦变换dct后的频谱的动、静态特征结合起来提高系统的识别性能,该频谱差分参数的计算公式为式(11):
41、
42、式中,dt表示第t个一阶差分即声纹特征,ct表示第t个倒谱系数,q表示倒谱系数的阶数,k表示一阶导数的时间差。
43、所述步骤(4)具体是指:
44、(4a)在vgg19模型中加入通道注意力机制模块:
45、所述vgg19模型由2个64x3x3的卷积层、2个128x3x3的卷积层、5个2x2最大池化层组成、8个512x3x3的卷积层、3个全连接层和分类函数softmax组成;所述通道注意力机制模块由一个1x1x512的全局池化层、1个1x1x64的全连接层、1个1x1x64的激活函数层、1个1x1x512的全连接层和1个1x1x512的逻辑回归层组成;所述通道注意力机制模块加在vgg19模型的最后一个512x3x3的卷积层和最后一个2x2最大池化层之间;
46、(4b)使用新的分类函数ah-softmax替代vgg19模型中原有的分类函数softmax,新的分类函数ah-softmax如式(16)所示:
47、
48、其中,样本权重指示函数pl为样本类别l的概率,pj为样本类别j的概率,θj,l为wj和样本x的夹角,θl,l为wl和样本x的夹角,s=||wj|| ||x||,f(m),θl,l)=cos(m,θl,l),lj=d(pj)-1,wj为样本类别j的优化角度,m为边界损失函数的裕度;wl为样本类别l的优化角度;j为样本的总类别数;
49、h(t,θj,l,lj)≥1为重加权函数,用于强调不同电力变压器声纹样本的权重,分别有以下两种形式,如式(17)和式(18)所示:
50、h(t,θj,l,lj)=exp(stlj) (17)
51、h(t,θj,l,lj)=exp(st(cos(θj,l)+1)lj) (18)
52、式中,exp(stlj)为固定权重函数,exp(st(cos(θj,l)+1)lj)为自适应权重函数。
53、由上述技术方案可知,本发明的有益效果为:第一,在原有vgg19模型上加入通道注意力机制模块,得到改进后的vgg19模型,改进后的vgg19模型对各个通道的特征更有辨别能力,在训练中就得到了通道之间的关系以及其重要程度,加强对变压器声纹的辨别能力;第二,将原有vgg19模型的分类函数softmax用新的分类函数ah-softmax替代,新的分类函数ah-softmax利用权重指示函数分布作为线索估计变压器声纹样本标签,强调变压器声纹样本的信息量,可以动态区分信息量不同的变压器声纹样本,并明确强调变压器声纹样本中的信息向量,同时吸收不同变压器声纹类别间的可辨别性,以指导其区分性特征学习,通过两部分改进可以提高改进后的vgg19模型对于变压器声纹信号的识别的度和准确度。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21543.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表