一种基于检索模式的声纹识别方法和系统与流程
- 国知局
- 2024-06-21 11:27:00
本发明涉及声纹识别,尤其是一种基于检索模式的声纹识别方法和系统。
背景技术:
1、声纹识别技术起源于声学和信号处理领域,经过多年的研究和发展,已经取得了显著的进展。声纹识别的基本原理是通过分析声音信号中的频率、声调、语速、共振等声学特征,来唯一地识别一个个体。与其他生物识别技术(如指纹和虹膜扫描)相比,声纹识别具有独特的优势,因为它无需接触,可实现远程身份验证。在当今数字化时代,数据泄露和身份盗窃问题不断增加。声纹识别提供了一种更加安全、便捷和高效的身份验证方式,用于保护敏感信息和系统免受未经授权的访问。随着生物识别技术的不断发展,声纹识别有望成为许多行业的核心技术,为用户提供更好的体验,同时增强了数据和系统的安全性。
2、现有的声纹识别技术主要通过音频单模态样本数据进行声纹识别,单一模态数据的性能波动较大,对于不同的个体和不同的录制条件,性能差异明显,这使得算法的性能有限。仅依赖音频数据容易受到环境噪音、录制条件变化等因素的影响,从而导致准确性下降。
技术实现思路
1、本发明的目的之一在于提供一种基于检索模式的声纹识别方法,其将声纹识别模型与检索模式结合,并且在声纹识别任务中添加了语音识别任务,通过音频和文本的两个模态训练声纹识别模型,以提高识别准确率和识别速度,并同时完成语音识别任务。
2、本发明的目的之一采用以下技术方案实现:一种基于检索模式的声纹识别方法,其包括训练部分和预测部分;
3、所述的训练部分包括以下步骤:
4、步骤一,获取声纹的预训练语言模型;
5、步骤二,预训练语言模型多任务学习,通过声纹识别和语音识别两个任务进行预训练,训练出一个用于将声纹转化为向量的模型,即声纹识别模型;
6、步骤三,构建声纹数据库,将每个人的声纹通过声纹识别模型转换为向量形式与对应人名进行存储;
7、步骤四,声纹数据库内全量声纹的向量索引构建;
8、所述的预测部分包括以下步骤:
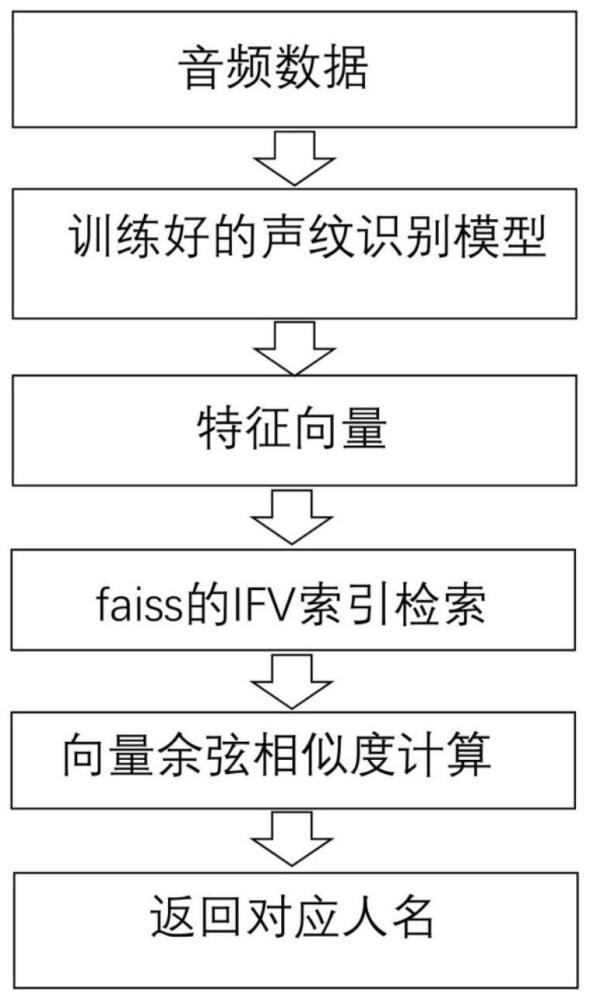
9、步骤五,输入待识别的声纹音频;
10、步骤六,将待识别的声纹音频通过声纹识别模型转化为特征向量表示;
11、步骤七,将上述待识别声纹音频的特征向量表示,利用faiss的ifv索引在声纹数据库中进行检索,与声纹数据库中的向量进行比较,从声纹数据库中挑选出相似的声纹向量后,作为候选向量;
12、步骤八,将待识别的声纹音频的特征向量表示与候选向量集合中的向量表示进行精确相似度计算,挑选出相似度最高的向量;
13、步骤九,返回相似度最高的向量所对应的人名,作为最终声纹识别的结果。
14、进一步地,所述的预训练语言模型,为由cnn卷积层和transformer模块组成的wav2vec模型。
15、进一步地,所述的声纹识别将语音输入并输出对应人名标签,语音识别将语音输入并输出文本,通过在声纹识别的训练中,添加一个语音识别的目标,提高声纹识别的准确率,得到一个声纹识别模型。声纹识别是本发明的主要任务,语音识别在训练期间起到支撑作用,通过提供文本方面的数据特征,提升声纹识别的准确性。
16、进一步地,所述的构建声纹数据库,需要收集音频文件和音频文件对应的说话人,通过声纹识别模型将音频文件转换成向量进行存储。
17、进一步地,所述的声纹数据库内全量声纹的向量索引构建,主要使用faiss工具对声纹数据库中的向量进行索引构建。
18、进一步地,所述faiss的ivf索引算法,它将向量划分为不同的子集,然后对每个子集建立倒排文件,允许faiss快速定位到候选向量集合,减少需要计算相似性的向量数量。
19、进一步地,所述的精确相似度计算,通过计算向量之间的夹角余弦值来计算两个向量之间的相似度。
20、进一步地,步骤七的具体内容如下:将声纹数据库中向量数据集进行聚类,将向量分配到不同的簇中;为每个簇构建一个倒排文件,其中记录了该簇中的向量;创建一个索引结构,将每个簇的倒排文件关联到一个索引表中,以便进行快速检索。
21、本发明的第二个目的在于提供一种基于检索模式的声纹识别系统,包括:
22、预训练模块,使用wav2vec模型进行声纹识别和语音识别两个训练任务,得到声纹识别模型,该声纹识别模型用于将输入的声纹音频文件转化为对应向量;
23、声纹数据库索引库模块:其由声纹音频转化的向量特征和对应的人名标签组成,将已有的声纹音频文件依次通过声纹识别模型提取得到所述的向量特征;
24、召回模块:通过faiss中的ifv检索挑选出声纹数据库中的候选向量集合;
25、精排模块:通过计算两个向量之间的余弦值,得到向量之间的相似度,对候选向量进行排序;
26、声纹识别模块:用于从声纹数据索引库模块中检索与待识别声纹的向量特征最匹配的向量特征,将检索结果对应的人名作为识别结果。
27、本发明具有的有益效果如下:本发明利用音频和文本两个模态对声纹识别进行训练提升声纹识别的准确;并使用faiss检索,快速减少相似性搜索的候选项数量,从而提高搜索效率。
技术特征:1.一种基于检索模式的声纹识别方法,其特征在于,包括训练部分和预测部分;
2.根据权利要求1所述的基于检索模式的声纹识别方法,其特征在于,所述的预训练语言模型,为由cnn卷积层和transformer模块组成的wav2vec模型。
3.根据权利要求1所述的基于检索模式的声纹识别方法,其特征在于,所述的声纹识别将语音输入并输出对应人名标签,语音识别将语音输入并输出文本,通过在声纹识别的训练中,添加一个语音识别的目标,提高声纹识别的准确率,得到一个声纹识别模型。
4.根据权利要求1所述的基于检索模式的声纹识别方法,其特征在于,所述的构建声纹数据库,需要收集音频文件和音频文件对应的说话人,通过声纹识别模型将音频文件转换成向量进行存储。
5.根据权利要求1所述的基于检索模式的声纹识别方法,其特征在于,所述的声纹数据库内全量声纹的向量索引构建,主要使用faiss工具对声纹数据库中的向量进行索引构建。
6.根据权利要求1所述的基于检索模式的声纹识别方法,其特征在于,所述faiss的ivf索引算法,它将向量划分为不同的子集,然后对每个子集建立倒排文件,允许faiss快速定位到候选向量集合,减少需要计算相似性的向量数量。
7.根据权利要求1所述的基于检索模式的声纹识别方法,其特征在于,所述的精确相似度计算,通过计算向量之间的夹角余弦值来计算两个向量之间的相似度。
8.根据权利要求1所述的基于检索模式的声纹识别方法,其特征在于,步骤七的具体内容如下:
9.一种基于检索模式的声纹识别系统,其特征在于,包括:
10.根据权利要求9所述的基于检索模式的声纹识别系统,其特征在于,所述的声纹识别模块中,采用近似最近邻匹配方式,相似度计算公式为:
技术总结本发明公开了一种基于检索模式的声纹识别方法和系统。本发明的声纹识别方法包括:输入待识别的声纹音频;将待识别的声纹音频通过声纹识别模型转化为特征向量表示;将上述待识别声纹音频的特征向量表示,与声纹数据库中的向量进行比较,利用faiss的IVF索引算法在声纹数据库中快速定位到候选向量的集合;将待识别的声纹音频的特征向量表示与候选向量集合中的向量表示进行精确相似度计算,挑选出相似度最高的向量;返回相似度最高的向量所对应的人名,作为最终声纹识别的结果。本发明利用音频和文本两个模态对声纹识别进行训练,提升声纹识别的准确率;并使用faiss检索,快速减少相似性搜索的候选项数量,从而提高搜索效率。技术研发人员:沈然,孙钢,沈皓,章江铭,金良峰,王庆娟,倪琳娜,吴慧,陈金鹏,姜伟昊受保护的技术使用者:国网浙江省电力有限公司营销服务中心技术研发日:技术公布日:2024/2/8本文地址:https://www.jishuxx.com/zhuanli/20240618/21594.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。