一种智能语音识别和语音合成优化方法与流程
- 国知局
- 2024-06-21 11:27:03
本发明涉及语音识别和语音合成,尤其涉及一种智能语音识别和语音合成优化方法。
背景技术:
1、随着统一通信(南网通)应用在全网的深入推广,用户规模不断增长,作为服务全网30万用户的通信服务热线的话务压力将急剧增加,同时随着通信业务不断发展,通信服务业务范围也将越来越广,受限于现有人工客服人力、工作时间、知识水平等因素限制,当前的统一通信客服平台已难以满足话务咨询的增长需求。而人工坐席和传统自助语音应答系统由于采用按键交互方式,用户与系统之间的交互效率受到很大限制,客户等待时间过长导致客服体验不佳,严重影响客户体验。当用户无法快捷获取到需要的服务时候,便会转向人工服务,使人工话务压力大大增加,运营成本上升。
2、另一方面,作为电网安全稳定运行的关键环节,电力调度员、通信调度、自动化调度运行人员负责操控指挥电力系统运行,调度台每日都记录了调度员海量的调度录音数据,目前这些数据分散在各级系统,主要用于异常事件发生后通过回放录音来帮助分析故障处理过程。并且由于音频文件占用空间大,且音频格式不便于进行数据归纳分析,文件存储超过一定时限将会删去录音数据,没有办法充分挖掘这些大量生产运行数据的价值,来帮助对调度指挥行为和成效进行深入分析和科学评价。
技术实现思路
1、鉴于上述现有存在的问题,提出了本发明。
2、因此,本发明提供了一种智能语音识别和语音合成优化方法,能够解决传统技术在适应性方面表现不足,特别是在处理噪声背景、非标准语言或口音时效果较差的问题。其次,本发明还能够解决现有的语音合成系统虽然能够转换文本为语音,但生成的语音往往缺乏自然的语调和流畅性,尤其是在复杂的句子或情感表达的问题。
3、为解决上述技术问题,本发明提供如下技术方案,一种智能语音识别和语音合成优化方法,包括:
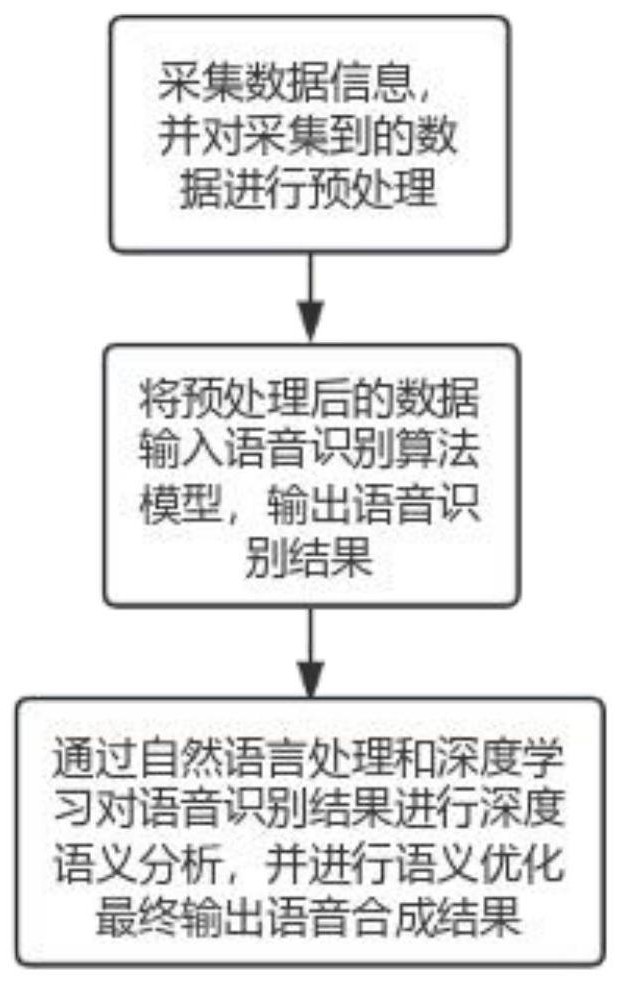
4、采集数据信息,并对采集到的数据进行预处理;将预处理后的数据输入语音识别算法模型,输出语音识别结果;通过自然语音处理和深度学习对语音识别结果进行深度语义分析,并进行语义优化最终输出语音合成结果。
5、作为本发明所述的智能语音识别和语音合成优化方法的一种优选方案,其中:所述预处理包括,对收集到的语音数据进行噪声减少、回声消除处理,并利用先进的声学模型对原始数据进行增强和清洗。
6、作为本发明所述的智能语音识别和语音合成优化方法的一种优选方案,其中:所述语音识别算法模型包括,对输入的预处理后数据进行特征提取:
7、f(x)=relu(batchnorm(w*x+b))
8、其中,relu表示非线性激活函数,batchnorm代表批量归一化操作,w表示卷积核权重,x是输入,b是偏差;
9、lstm层接收cnn层提取的特征,处理语音数据中的时间序列依赖关系,具体过程如下:
10、遗忘门:ft=σ(wf·[ht-1,xt]+bf)
11、输入门:it=σ(wi·[ht-1,xt]+bi)
12、输出门:ot=σ(wo·[ht-1,xt]+bo)
13、新记忆单元:
14、最终记忆单元:
15、最终输出:ht′=at(ht,c),ht=ot·tanh(ct)
16、其中,ht-1,xt]表示上一个时间步的隐藏状态和当前输入的组合;xt表示当前输入;ht表示是当前时间步的隐藏状态输出;ct表示当前时间步的最终记忆单元;ct-1表示上一个时间步的记忆单元;tanh是双曲正切激活函数,将值映射到-1和1之间;σ表示sigmoid激活函数,将值映射到0和1之间;ft表示当前时间步的遗忘门输出;wf表示遗忘门的权重;bf表示遗忘门的偏差项;it表示当前时间步的输入门输出;wi表示输入门的权重;bi表示输入门的偏差项;ot表示当前时间步的输出门输出;wo表示输出门的权重;bo表示输出门的偏差项;表示当前时间步的新记忆单元;wc表示记忆单元的权重;bc表示记忆单元的偏差项。
17、作为本发明所述的智能语音识别和语音合成优化方法的一种优选方案,其中:所述语音识别算法模型还包括,基于反向传播和梯度下降算法自动调整网络权重和参数,具体表示为:
18、
19、其中,η是学习率,j是损失函数,y是目标输出。
20、作为本发明所述的智能语音识别和语音合成优化方法的一种优选方案,其中:所述语音识别算法模型还包括,在损失函数中加入正则化项:
21、j'(w,x,y)=j(w,x,y)+λ||w||2
22、其中,λ表示正则化系数;
23、更新权重:
24、
25、其中,j′是加入了正则化项的损失函数。
26、作为本发明所述的智能语音识别和语音合成优化方法的一种优选方案,其中:所述深度语义分析包括,优化的语音合成技术包括利用自然语言处理和深度学习模型对文本进行深度语义分析,修正合成语音在语法、语境和情感表达上的准确性和自然度,同时通过深度学习模型进一步识别和模仿人类的情感表达。
27、作为本发明所述的智能语音识别和语音合成优化方法的一种优选方案,其中:所述语义优化包括,当深度语义分析语音内容为技术性或专业性话题时,系统调整语音分析模型,增加专业术语的敏感度,检索数据库中对应技术策略或技术响应方案;若未能在数据库检索到相应策略或方案,则自动调整语音识别权重,进一步根据用户特定口音或语速进行识别;若识别困难,则申请提供文本输入或语音转文本文件;
28、当深度语义分析语音内容非各国标准普通用语时,检索语音文件来源或语音文件内容来源,获取特定的地理位置或文化背景依据,将获得到的信息调整语义结构直至符合特定的语言习惯和文化特点,并提供地区特定的服务信息或建议。
29、作为本发明所述的智能语音识别和语音合成优化方法的一种优选方案,其中:所述语义优化包括,当深度语义分析当前语音内容和背景信息发生变化时,根据当前语音内容和背景信息实时切换语境,调整语义分析框架,同时进行语义校准判断是否出现信息重复或错位;所述语义校准是指语音文件重新经过预处理并输入语音识别算法模型,输出语音识别结果,再通过自然语音处理和深度学习对语音识别进行深度语义分析对深度语义分析结果进行二次输出;
30、当深度语义分析出现识别性能下降或错误频发的情况时,系统自动启动诊断程序,分析判断问题原因是否为模型过拟合或数据质量问题,引导下级系统进行问题报告或自动转入维护模式。
31、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现智能语音识别和语音合成优化方法的步骤。
32、一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现智能语音识别和语音合成优化方法的步骤。
33、本发明的有益效果:本发明技术在语音识别和处理领域引入了一系列革新性的改进,旨在提供更高效、准确、个性化的用户体验。首要的是显著提高了语音识别的准确率。通过采用自适应神经网络结构,本发明不仅能够精准地识别标准语言和方言,还能有效处理多种口音和在嘈杂环境下的语音。这一特性尤其在需要处理多元化语音输入的场景中显得尤为重要。此外,本发明在实时性方面也取得了显著进步。快速响应的特性极大地改善了用户交互的流畅性,特别是在那些需要即时反馈的应用场景中,如自动客服系统或实时翻译服务。快速且准确的响应不仅提高了效率,还有助于提升用户的满意度和信任感。在语音合成的自然度方面,本发明通过先进的算法生成了更加流畅和自然的语音输出。这不仅使得合成语音更易于理解,还大大增加了交流的舒适度,特别是在长时间的听力活动中,如有声读物或长篇讲演。个性化用户体验也是本发明的一大亮点。系统能够学习用户的语音习惯、偏好及交互模式,从而提供更为定制化的服务。这种个性化不仅体现在语音识别的准确性上,也表现在语音响应的风格和内容上,使得每次交互都更加贴合用户的具体需求。在应对噪声环境方面,本发明通过强化噪声抑制功能,保持了语音识别的准确性。这一点对于在嘈杂环境中使用语音系统的用户尤为重要,如在繁忙的街道、机场或工业环境中。通过有效的噪声抑制,本发明确保了即使在不理想的环境中也能提供可靠的服务。本发明的另一个重要特点是其持续学习和优化的能力。系统不断地从用户交互中学习,适应新的语音模式和用户行为。这意味着本发明能够随着时间的推移不断进步,不断提高其性能和适应性。在适应性和灵活性方面,本发明能够适应多种不同的应用环境和用户需求,从商务会议到家庭娱乐,再到日常通信,提供广泛的适用性。最终,通过提供更准确、更快速、更自然的响应,本发明显著提升了用户的整体满意度和忠诚度,使其在各种实际应用场景中更具吸引力和实用性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21599.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。