一种基于醉汉模型的轻量化声学场景感知方法
- 国知局
- 2024-06-21 11:27:15
本发明涉及声学场景分类,特别涉及一种基于醉汉模型的轻量化声学场景感知方法。
背景技术:
1、声学场景分类作为深度卷积神经网络在音频领域的重要应用之一,通过模拟人类对外界环境的感知能力来对周围环境做出正确分类,已广泛用于音频监控、智能辅助驾驶、声纹识别等领域。声学场景分类任务大多采用自上而下的串联方式,将提取的特征信息直接输入神经网络模型进行预测,但上述方式存在一些限制。目前主流的神经网络仍属深度卷积神经网络,此外,一些高精度的轻量化模型也被提出。例如,高效的bc-resnet架构,通过按频率的二维卷积和时间的一维卷积,提取出两个特定于频率和时间维度的特征图,取得了优异的性能。融合bc-resnet和res2net结构提出的bc-res2net,可以通过广播学习有效获取频率和时间维度的特征,并且可以多尺度运行,性能显著。近几年提出的mobilenet系列模型和shufflenet通过引入深度卷积和混洗(shuffle)操作,实现了轻量化的高效网络。
2、声学场景分类主要包括特征提取和分类模型构建两部分,将提取的特征信息直接输入神经网络模型进行预测。目前主流的音频特征为对数梅尔谱(log-mel)特征、mfccs(mel frequency cepstral coefficients)以及时域一阶差分和二阶差分等。部分声学场景分类任务中采用单一的特征提取方式,虽然可以节省计算开销,但会忽略部分重要信息,导致分类性能较差。而采用多种特征提取方式可能包含冗余的特征图,导致不必要的计算成本。
3、模型方面,用于声学场景分类任务的网络受其结构的限制,计算开销会随着模型加深而增加,这不利于在资源有限设备上的部署。而且上述任务中多采用单一的神经网络模型,可能无法充分提取关键的音频特征,且目前并没有确定的最佳模型架构和超参数组合,容易导致场景类别的错误决策。
4、参考文献
5、[1]j.hu,l.shen,g.sun,"squeeze-and-excitation networks,"proceedings ofthe ieee conference on computer vision and pattern recognition,7132-7141,2018;
6、[2]k.he,x.zhang,s.ren,et al.,"deep residual learning for imagerecognition,"proceedings of the ieee conference on computer vision andpattern recognition,770-778,2016。
技术实现思路
1、本发明针对现有技术的缺陷,提供了一种基于醉汉模型的轻量化声学场景感知方法。
2、为了实现以上发明目的,本发明采取的技术方案如下:
3、一种基于醉汉方法论的轻量化声学场景感知方法,包括以下步骤:
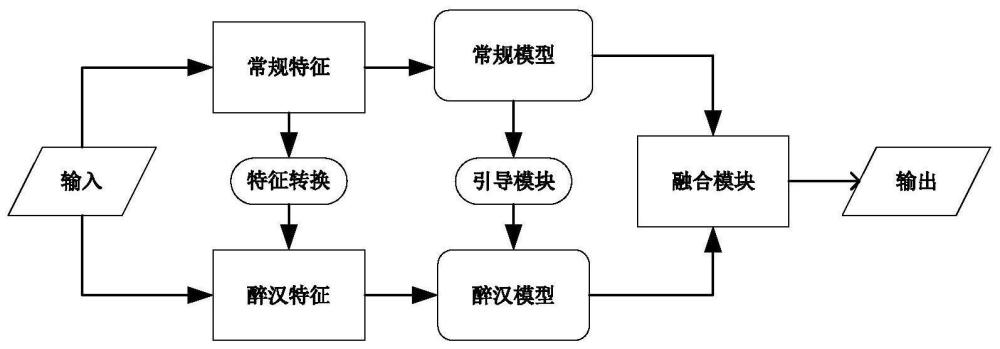
4、1)常规音频特征提取:收集原始音频数据,采用对数梅尔频谱和一阶差分以及二阶差分方式将原始音频数据转换为常规音频特征。
5、2)醉汉特征提取:基于squeeze-and-excitation(se)注意力模块,设计了一个基于注意力机制的特征转换模块。常规音频特征通过特征转换模块处理,去除冗余信息后得到醉汉特征。
6、3)常规模型训练:使用常规模型的结构和参数进行训练。通过输入常规音频特征,训练模型并进行场景感知能力学习。
7、4)引导模块操作:使用常规模型进行通道缩减和添加频率分组融合卷积的操作,以得到醉汉模型的初始版本。通过实验和调整,找到最佳的通道数量和分组卷积设置。
8、5)醉汉模型训练:使用引导模块得到的初始版本的醉汉模型进行训练。与常规模型训练类似,输入醉汉特征并对醉汉模型进行训练和优化。
9、6)融合模块操作:使用常规模型作为教师模型,醉汉模型作为学生模型,通过知识蒸馏的方式来提升学生模型的性能。蒸馏损失是基于学生和教师模型的预测结果计算的,通过软标签预测结果计算蒸馏损失和硬标签损失的加权和来得到最终的损失。
10、7)评估模型:对融合后的轻量化模型进行评估,检查其在声学场景感知任务上的准确率和性能,得到评估结果。
11、8)模型优化:根据评估结果,对轻量化模型进行优化和调整。得到最终的醉汉模型。
12、9)将醉汉音频特征输入醉汉模型,得到声学场景感知结果。
13、进一步地,步骤2)醉汉特征提取中:在全局平均池化操作将常规特征中每个通道的空间维度降为一个标量,将每个通道的信息进行压缩,得到每个通道的全局平均值,以捕获通道内的全局统计信息并减少计算量,并且提取通道内的特征相关性。
14、通过全连接层学习通道间的相关性,并利用sigmoid激活函数获取不同通道维度特征的权重。最后,将权重与各个原始特征相乘,得到醉汉特征。
15、进一步地,所述醉汉模型包括:频率分组融合卷积(fregroupconv2d)、分组卷积(groupconv2d)、改进瓶颈块(fcresnet_block)、卷积层和池化层。
16、构建醉汉模型的运行流程为:经过频率分组融合卷积丰富特征信息,经过卷积层和池化层,进行通道扩展和下采样,以提取更高级的特征表示。经过多个堆叠的改进瓶颈块,改进瓶颈块的通道数量和步长不同,加入dropout以防止过拟合。将各组输出在通道维度级联,以保持输入和输出的通道数量一致。经过全局平均池化和全连接层后,输出分类结果。
17、所述改进瓶颈块是对残差网络resnet中的瓶颈块进行修改的结果,主要由分组卷积组成。改进瓶颈块则将瓶颈块中的3×3卷积替换为分组卷积。分组卷积将通道维度均匀划分为多个组,每个组都经过一个3×3卷积。
18、进一步地,在醉汉模型的第一层,将频率分组融合卷积放置。频率分组融合卷积对输入特征的频率维度进行划分,将频率维度划分为多条分支。每个分支通过一个3×3的卷积层进行处理。除了第一分支外,其他分支都会接收来自前一分支的特征信息,从低频到高频逐渐提取特征。将每个分支的输出在通道维度进行级联,然后输入到下一阶段。
19、与现有技术相比,本发明的优点在于:
20、1.提高模型的性能:通过引入特征转换模块和融合模块操作,可以提高模型的性能和准确率。特征转换模块可以去除冗余信息,减少模型的复杂度,提高特征的区分度和表征能力。融合模块操作利用知识蒸馏的方式提升学生模型的性能,使其逼近教师模型的性能。在资源受限的情况下,仍能获得较高的准确率和较低的损失值,准确率最高提升至45.2%,损失较基线降低了0.634。
21、2.轻量化模型:通过通道缩减和分组卷积等操作,轻量化模型的参数量和计算复杂度得到降低。这可以提高模型的运行效率,适用于资源受限的环境和设备。醉汉模型在参数量仅为442.67k的条件下,能够达到41.5%的准确率。超越了主流轻量化模型。
22、3.引导模块操作:引导模块操作可以提供醉汉模型的初始版本,减少训练时间和计算资源的消耗。通过实验和调整,找到最佳的通道数量和分组卷积设置,进一步优化模型的性能。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21621.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表