一种基于混合分层分类的音频场景识别方法
- 国知局
- 2024-06-21 11:27:20
一、本发明属于音频场景识别领域,尤其是涉及一种基于混合分层分类的音频场景识别方法。
背景技术:
0、二、背景技术
1、1.1音频场景识别
2、音频场景主要是指在自然环境下或者社会生活中的环境音频记录,它是某个真实场景下的声音混合形成的整体环境声音。音频场景识别(acoustic sceneclassification,asc)通过对音频记录特征信息进行分析,识别其所处的音频场景,可以应用于视觉辅助、智能家居和安全监护等领域。例如,音频场景可以不受光线和遮挡的干扰,作为视觉辅助系统,帮助视障人士识别所处的位置和周围环境,来决定下一步的行动。在智能家居领域,音频场景识别系统可以自动监听识别破窗声、火灾报警等异常声音,从而实现智能安全监控,保障家庭安全。
3、随着深度学习的发展,基于深度学习的音频场景识别方法逐渐成为主流,其主要流程包括数据增强、数据预处理、特征提取和分类。目前,在数据预处理、特征提取和建模等多个方面已经提出了各种方法来提高音频场景识别的准确率,取得了一定的识别性能。
4、然而,音频场景识别任务仍存在以下几个问题:(1)同一音频场景的声学特征存在高度的多样性,不同的音频场景的声学特征又存在一定的相似性,导致难以提取有效的音频场景特征(2)音频信号缺乏结构化的信息,难以建模(3)源数据和目标数据的分布不匹配,如多设备等(4)传统的asc算法是基于一组互斥的类。然而,在真实世界的数据中,都存在着音频场景类之间的层次结构。上述问题的存在使得音频场景识别的准确性仍然较低。
5、1.2多层次分类方法
6、层次化分类方法是在偏序集(c,<)上定义的树结构的规则概念层次结构。其中c是一个有限集合,它列举了应用领域中的所有类概念,关系<表示“is-a”关系。“is-a”关系具有不对称性、反自反性和传递性,在同一层次上互斥,可以表示为:
7、(1)唯一的最大元素“r”是树的根;
8、(2)若ci<cj,则ci≥cj;
9、(3)ci≥ci;
10、(4)ck∈c,若ci<cj,且cj<ck,则必有ci<ck。
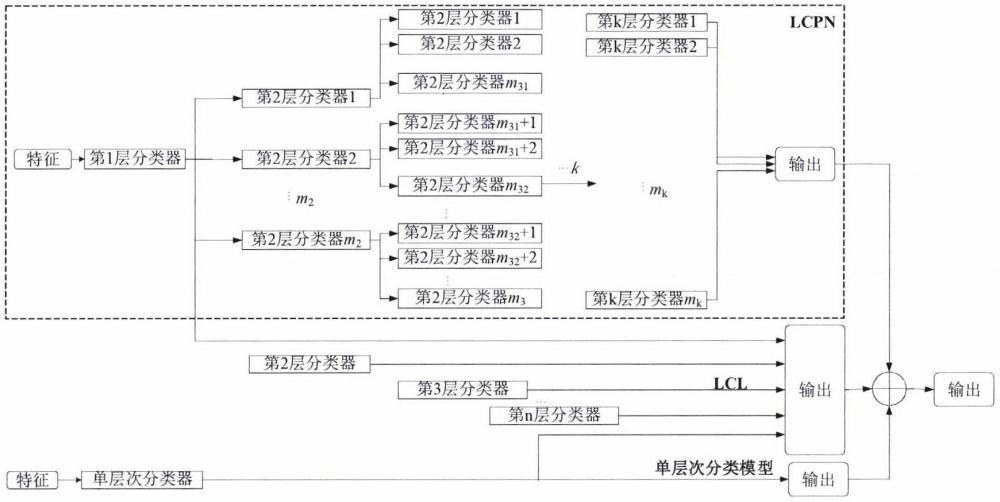
11、对于音频场景识别问题,分层分类算法可以由以下4个因素来确定。一是预测标签的路径,表明算法可以在层次结构中为每个数据样本分配一条或多条路径,spp表示单路径,mpp表示在某个类别上的多个预测标签;二是预测深度,确定算法是否总是分配叶类,nmlnp表示算法可以在任何级别上分配类(包括叶类)。三是类层次结构的类型,包括树和有向非循环图(dag),树与dag的区别在于每个节点在树中只有一个父节点,而dag中的节点可以有多个父节点;四是分层分类算法类型,包括每节点本地分类器(lcn)、每父节点本地分类器(lcpn)和每局部分类器(lcl)。三种分层分类算法具体如下:
12、(1)lcn方法为除根节点之外的类层次结构中的每个节点训练一个二值分类器,需要选择正样本和负样本来对其进行训练。由于lcn的每个节点都会给出一个输出来表示输入是否属于其节点类,因此是多分类的。这种算法中有多个分类器,因此,在测试过程中可能会导致跨类级别的预测不一致问题,从而影响系统的识别准确率。通常可以通过自上而下的预测方法来解决,当前级别上的预测是由在其父节点级别上预测的类来决定的。
13、(2)lcpn方法为层次结构中的每个父节点训练一个多分类器,并预测其子类。通常,lcpn方法在整个层次结构中使用相同的分类器。同lcn算法一样,其多重分类器也存在预测不一致问题,需要通过自上而下的预测方法来解决。然而,lcpn中的自上而下的预测方法会导致层间误差的传播,其中一个类节点上的错误分类会向下传播到其所有的子类中,从而影响识别的准确率。
14、(3)lcl方法为层次结构中的每个级别训练一个多类别分类器。当所有叶节点的深度相同时,最深层次的分类器是一个单层次分类器,它只预测叶节点上的类。由于这种算法有多个不同级别的分类器,因此也可能会导致类别预测不一致的问题,通常会使用后处理方法进行修正。
技术实现思路
0、三、技术实现要素:
1、有鉴于此,本发明提出了一种基于混合分层分类的音频场景识别方法,将层次化分类方法引入音频场景识别领域,分析和建模音频场景类之间的分层结构,使其符合人类的感知模式,从而提升音频场景识别的准确率。
2、为达到上述目的,本发明的技术方案是这样实现的:
3、一种基于混合分层分类的音频场景识别方法,包括如下步骤:
4、步骤1:对原始音频数据进行数据增强,获得增强后的音频数据,以增加训练样本的多样性和提高模型的泛化性;
5、步骤2:对增强后的音频数据进行特征提取,得到其对数梅尔能量特征作为输入特征;
6、步骤3:将对数梅尔能量特征输入到分层网络中,得到不同分层的特征向量以及对应的概率输出;
7、步骤4:对不同层次的输出概率加权求和作为最后的概率输出,并给出预测结果。
8、进一步的,所述步骤1中的数据增强方式有多种,不做限制。这里列举出如下几种数据增强方式:(1)混合。随机混合来自同一音频场景类的两个音频数据。(2)音调偏移。以均匀分布随机移动音调。(3)时间拉伸。在不影响音调的条件下,随机改变音频信号的速度或持续时间。(4)添加随机噪声。在音频数据中随机添加高斯噪声。(5)动态范围压缩。降低音频中响亮声音音量或放大安静声音,从而压缩音频信号的动态范围。(6)频谱矫正。将给定的输入声谱转换为参考设备的声谱。(7)随机擦除。用随机数随机替换掉音频信号中的特征块。(8)频谱滚动。水平、垂直、或扁平化后随机移动声谱。(9)声道混淆。随机拼接或用随机权重拼音频的谐波分量和冲击分量。
9、进一步的,所述步骤2中具体包括如下步骤:
10、步骤201:对数据增强后的音频信号进行分帧、加窗处理;
11、步骤202:对分帧加窗后的短时信号进行短时傅里叶变换,将音频信号转化到时频域,形成一个2维时频谱;
12、步骤203:将得到的2维时频谱通过一个梅尔滤波器组,并取其对数,得到对数梅尔能量特征。梅尔频率与单位为hz的频率之间的转换关系如下:
13、
14、其中,fmel是梅尔频率值,f是单位为hz的频率值;
15、进一步的,所述步骤3中所述的分层分类方法可以描述为一个针对n个预定义类别的音频场景,k个层次p1,p2,p3,…,pk,第i个层次上的节点为的音频场景分类问题,其中,mi表示第i层的节点总数。
16、进一步的,所述步骤3中具体包括如下步骤:
17、步骤301:设计构建混合分层分类模型的单层次分类模型。单层次分类模型设计为一个n分类器,它是非层次结构的,直接通过输入特征来判断最终的音频场景类;
18、步骤302:设计构建混合层次分类模型的lcpn模型。lcpn模型根据第i层的节点的下一级子节点个数设计相应类别数的分类器,父类控制其下一级子类的训练数据,并采用自顶向下的预测方法来避免类层次间的类预测不一致问题;
19、步骤303:设计构建混合层次分类模型的lcl模型。lcl模型同样根据第i层的节点子节点个数设计相应类别数的分类器,基于相同数据集和不同的层次分类标签进行训练,且不使用父类与其下一级子类之间的层次结构进行约束。将lcpn系统的p1~pk-1层的分类器与单层次系统的n分类器组合形成lcl系统,在不同的层次分类标签上进行预测,从而完成lcl模型的搭建;
20、进一步的,所述步骤4中具体包括如下步骤:
21、步骤401:将音频特征输入到上述搭建的单层次分类模型,lcpn模型以及lcl模型中,训练组成3个模型的各级分类器,并得到相应的预测输出x1,x2,x3;
22、步骤402:将构建的单层次分类模型、lcpn模型与lcl模型的预测输出按照权重求和,给出最后的预测结果,计算公式如下:
23、x=ω1x1+ω2x2+ω3x3
24、其中,ω1,ω2,ω3分别为单层次分类模型、lcpn模型、lcl模型的权重系数。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21628.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表