一种语音识别中说话人停顿处理的方法与流程
- 国知局
- 2024-06-21 11:27:19
本发明属于服务器维护领域,具体地说是一种语音识别中说话人停顿处理的方法。
背景技术:
1、随着人工智能ai技术的发展,语音识别asr在社会中也有广泛应用。asr识别往往处在多个流程中的靠前部分,即asr识别后的文本会送入后续流程进行处理。大多情况下,asr之后的流程依赖于用户说的话,依赖于asr识别的“完整”文本,后续流程会针对用户说的话所包含的“完整语义”做出相应的反馈动作。
2、asr客户端,从交互上可以分类两种:
3、人工控制说话的开始和结束。例如:按键按下说话,松开停止。
4、算法自动判断说话的开始和结束。例如:
5、专用vad模型(webrtc-vad、silero-vad)检测到人声时,认为是说话开始,检测不到人声时,认为是说话结束。
6、算法内部,实现连续一段时间(例如500ms)asr没有识别到文本时,认为是一句话结束。(业界有:paraformer、wenet是这样检测endpoint)
7、第一类交互方式,可以基本保证用户说话的话是完整的,但交互过程不够自动化、智能化。
8、第二类交互方式,广泛应用在更自动化、智能化的场景,可以进行全流程的语音交互,不需要触摸按键。该方案的缺点是:无法保证用户说话的完整性(用户说话中间可能会有思考、喘气等带来的停顿),如果直接使用asr的结果,可能用户只说了半句话,后面的还没说完,所以无法保证用户“意图”的完整性,进而无法保证后续流程环节的效果。
9、专利号为:cn202310131353.4,专利名称为:语音识别方法、装置、设备及介质的专利公开了如下技术方案,所述依据所述断句特征信息,对所述目标语音流信息进行语段切分,得到所述目标语音段信息,包括:对所述断句特征信息进行统计处理,得到断句时长阈值和目标断句词;对所述目标语音流信息进行持续检测,得到断句信息,所述断句信息包含停顿位置、停顿时长以及目标检测词;判断所述停顿时长是否大于所述断句时长阈值;若所述停顿时长大于所述断句时长阈值,则确定所述目标检测词是否属于所述目标断句词;若所述目标检测词属于所述目标断句词,则基于所述停顿位置对所述目标语音流进行语段切分,得到所述目标语音段信息。其缺点是:目标检测词。目标检测词在真实场景中难以确定,在2b业务中,面向客户的客户,其场景众多,要求其提供全面的目标检测词并不现实,实用性不强。
10、专利号为:cn202110983301.0,专利名称为:语音断句方法、计算机设备和存储介质的专利公开了如下技术方案,结合语音数据的静音信息(语气停顿特征)与asr识别的文本,送入断句预测模型进行预测。该专利提供的信息可以表明(其专利书中的图2-s30、图3),其使用了语音数据的静音信息与asr识别的文本作为特征,训练了一个断句预测模型(包括但不限于卷积神经网络模型、条件随机场模型以及循环神经网络等等),用该模型计算累积静音分值。其缺点是:模型训练成本高。该模型的训练,需要专门收集海量的断句文本信息、语气停顿信息。需要选择或设计一个模型结构,并进行训练。整个过程周期长、人工投入大。调用频率高。该专利需要计算两个相邻语音包的文本信息,而其示例给出的一个语音包的时长是20ms。按照20ms,可知该模型的调用频率为50次/秒。虽然其该语音包的长度(20ms)是一个示例值,但从该示例可知其不会太长,模型的调用频率必然在几十次/秒。会给服务器带来较高的并发压力。该方案投入成本高、服务端的并发压力大。
技术实现思路
1、本发明提供一种语音识别中说话人停顿处理的方法,用以解决现有技术中的缺陷。
2、本发明通过以下技术方案予以实现:
3、一种语音识别中说话人停顿处理的方法,包括如下步骤:
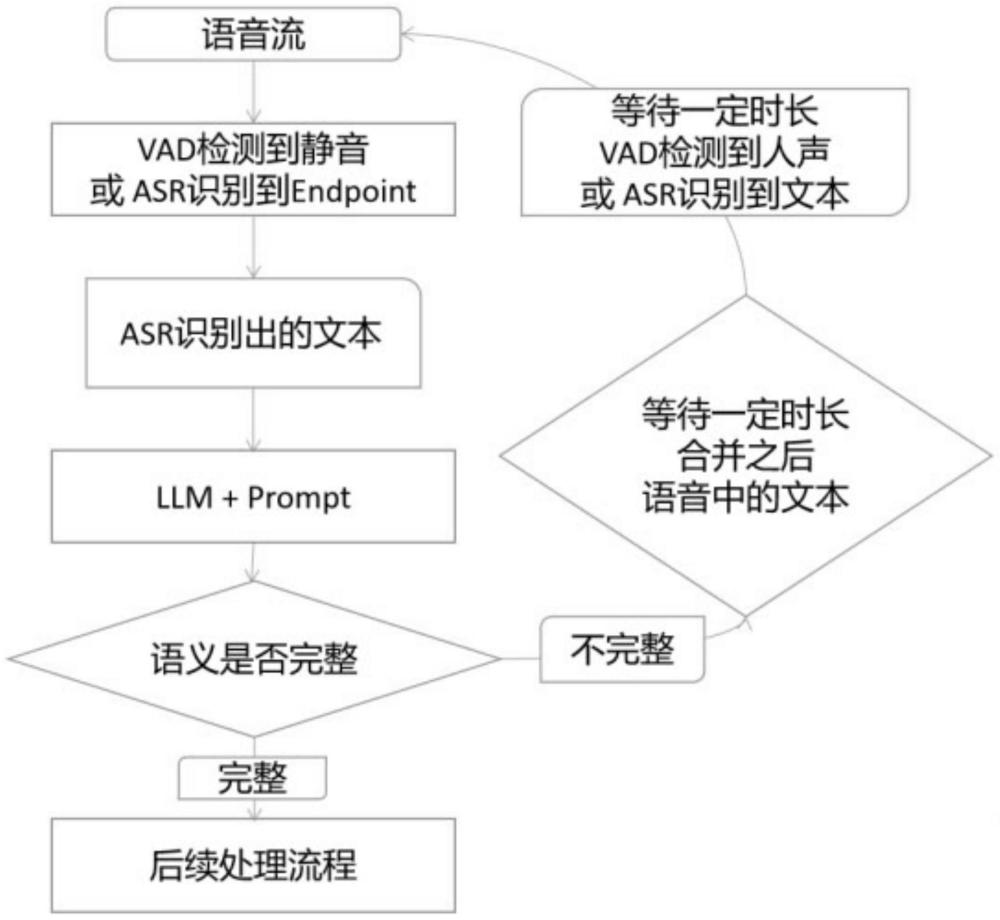
4、步骤一:获取语音,通过asr对语音进行识别;
5、步骤二:通过使用llm大语言模型的prompt提示词话术来实现断句检测;
6、步骤三:若步骤二检测断句语意完整则输出该asr文本送入后续处理流程;
7、步骤四:若步骤二检测断句语意不完整则等待一定时长的阈值,等待说话的声音,若有声音,则等说完,合并两次或多次的asr文本,送入后续处理流程,若该时长阈值内未发现说话声音,则不再等待,直接将本次asr文本送入后续处理流程。
8、如上所述的一种语音识别中说话人停顿处理的方法,所述的步骤一中语音识别为离线语音识别(即asr+vad方案又称offline asr,说完话再开始识别只在vad检测到静音时调用一次断句检测)或在线实时语音识别(asr+endpoint检测技术又称online asr,一边说一边识别,只在endpoint出现时调用一次断句检测)。
9、如上所述的一种语音识别中说话人停顿处理的方法,所述的步骤四中的等待时长的阈值为100毫秒-1000毫秒。
10、如上所述的一种语音识别中说话人停顿处理的方法,所述的步骤四中的等待次数上限为2次。
11、本发明的优点是:本发明能够解决在asr中由停顿带来的断句问题,同时本发明还有极低的研发投入、极高的准确率、并发压力小等优势,从而能够在语音识别领域广泛推广和应用。
技术特征:1.一种语音识别中说话人停顿处理的方法,其特征在于:包括如下步骤:
2.根据权利要求1所述的一种语音识别中说话人停顿处理的方法,其特征在于:所述的步骤一中语音识别为离线语音识别或在线实时语音识别。
3.根据权利要求1所述的一种语音识别中说话人停顿处理的方法,其特征在于:所述的步骤四中的等待时长的阈值为100毫秒-1000毫秒。
4.根据权利要求1所述的一种语音识别中说话人停顿处理的方法,其特征在于:所述的步骤四中的等待次数上限为2次。
技术总结一种语音识别中说话人停顿处理的方法,包括如下步骤:步骤一:获取语音,通过ASR对语音进行识别;步骤二:通过使用LLM大语言模型的Prompt提示词话术来实现断句检测;步骤三:若步骤二检测断句语意完整则输出该ASR文本送入后续处理流程;步骤四:若步骤二检测断句语意不完整则等待一定时长的阈值,等待说话的声音,若有声音,则等说完,合并两次或多次的ASR文本,送入后续处理流程,若该时长阈值内未发现说话声音,则不再等待,直接将本次ASR文本送入后续处理流程。本发明能够解决在ASR中由停顿带来的断句问题,同时本发明还有极低的研发投入、极高的准确率、并发压力小等优势,从而能够在语音识别领域广泛推广和应用。技术研发人员:黄明明受保护的技术使用者:北京中科深智科技有限公司技术研发日:技术公布日:2024/2/8本文地址:https://www.jishuxx.com/zhuanli/20240618/21627.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表