一种基于知识图谱和语音特征融合网络的语音理解方法
- 国知局
- 2024-06-21 11:27:47
本发明涉及对语音数据处理的,尤其是涉及一种基于知识图谱和语音特征融合网络的语音理解方法。
背景技术:
1、语音理解旨在将人类的语音信息转化为计算机可以理解的字符序列,语音理解主要包括了自动语音识别automatic speech recognition(asr)和语音识别纠错两大环节。语音理解作为重要的一环,很容易受到现实环境中的噪声影响,所以语音增强的方法常被用于语音的去噪来提高语音识别的表现。针对语音识别的输出,语音识别纠错也被广泛用于优化asr的输出结果,随着深度学习的推出,已有大量的研究将深度学习用于asr,目前主流的方案是使用联合训练框架,同时对语音增强和asr以相同的目标共同优化,因为在实现鲁棒性的asr时,语音增强和语音识别不是两个独立的任务,它们明显可以相互受益,但这些方案只使用增强后的特征用于语音识别,会受到增强导致的语音失真的影响。语音识别纠错是一种典型的序列到序列任务,它以asr模型生成的句子为源序列,以真实句子为目标序列,对源序列中的错误进行纠错,与英语等西方语言相比,汉语错误检测更加复杂,因为汉语书面文本中没有单词分隔符,字词的纠错只能在单词级别上进行,而且以往的方法大多数没有加入外部知识来支持纠错,在特定场景下的纠错难以突破瓶颈。
2、因此,提供了一种基于知识图谱和语音特征融合网络的语音理解方法。
技术实现思路
1、本发明的目的是提供一种基于知识图谱和语音特征融合网络的语音理解方法,能够降低语音背景噪声的影响,降低语音理解系统的字符错误率,能够在特定领域下,对于语音识别的结果,使用基于知识图谱的方法进行可靠性更高的纠错,这些使得语音理解系统能更稳健的部署在实现应用环境中。
2、为实现上述目的,本发明提供了一种基于知识图谱和语音特征融合网络的语音理解方法,包括以下步骤:
3、s1:获取大型语音数据集,并自行录制领域对话语音数据集,对大型语音数据集和领域对话语音数据集中的每条语音都与噪声混叠来生成嘈杂语音数据集;
4、s2:依据领域对话语音数据集,查阅相关资料并构建对应领域的知识图谱;
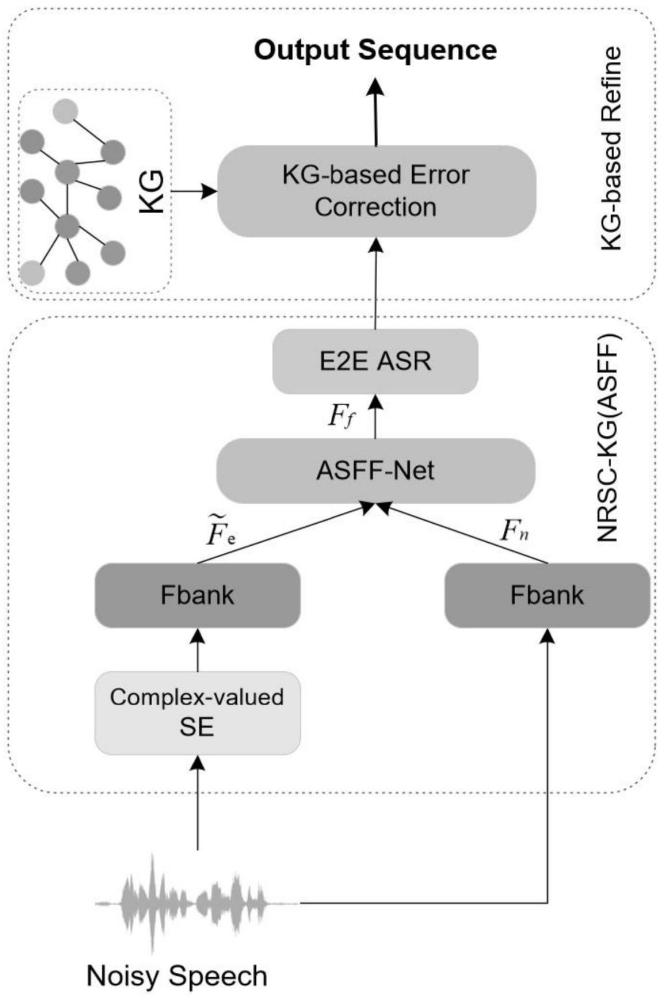
5、s3:构建提取语音fbank特征的fbank特征提取网络,选择能进行复值操作的深度复卷积递归网络dccrn,作为复值域的语音增强网络;
6、构建自适应性的语音特征融合网络;
7、使用e-branchformer作为编码器,transformer作为解码器,构建端到端的语音识别网络;
8、s4:使用步骤s1中的嘈杂语音数据集来同时训练语音增强网络、自适应性的语音增强融合网络和语音识别网络,将训练好的语音增强网络、自适应性的语音增强融合网络和语音识别网络进行级联,组成声学模型;
9、s5:对声学模型进行优化,直到符合标准;
10、s6:使用步骤s5中的声学模型,输入待识别的语音,进行语音的识别,输出字符序列的句子;
11、s7:使用步骤s2中的知识图谱对声学模型输出的字符序列的句子进行一次纠错,得到一次纠错结果;
12、s8:使用基于macbert的端到端纠错模型,对步骤s6中的一次纠错结果再进行纠错,在不改动一次纠错修改内容的前提下,得到二次纠错结果,二次纠错结果为最终的识别结果。
13、优选的,所述步骤s3中,构建fbank特征提取网络的参数如下:
14、fbank特征提取网络以32ms汉明窗长8ms窗移的stft对输入语音提取stft特征,再通过257x80的矩阵乘法转换为80维的fbank特征。
15、优选的,所述步骤s3中,构建自适应语音特征融合网络的过程如下:
16、自适应语音特征融合网络包括若干个局部注意力模块和若干个全局注意力模块,其中局部注意力模块接受张量输入,得到张量输入之后,先经过第一个卷积层的计算,之后紧跟着一个bn1层和relu激活函数,relu函数处理后的输出,馈送到第二卷积层,之后再输送第二个bn2层,在bn2层之后得到局部注意力模块的输出;
17、其中全局注意力模块接受张量输入,得到张量输入之后,先对输入进行一个1维全局平均池化操作,然后经过第一个卷积层的计算,之后紧跟着一个bn1层和relu激活函数,relu函数处理后的输出,馈送到第二卷积层,之后再输送第二个bn2层,在bn2层之后得到全局注意力模块的输出。
18、优选的,所述步骤s5中,对声学模型进行优化的过程如下:
19、计算声学模型的损失函数,公式如下:
20、l=αlenh+βlasr
21、上式中,l表示声学模型总的损失函数,lenh表示语音增强网络的损失函数,lasr表示语音识别网络的损失函数,α和β分别表示这两个损失函数的权重参数;
22、采用adamw优化器来优化声学模型,设置批大小为32,学习率为0.001,权重衰减设为0.01,在每一次迭代优化中,同时调整语音增强网络、自适应性的语音增强融合网络和语音识别网络的网络参数;
23、当声学模型的损失函数的值在一个区间波动时,优化过程结束。
24、优选的,所述步骤s6中,声学模型的识别过程,包括步骤如下:
25、s61:对于输入语音,先使用fbank特征提取网络,提取原始语音特征;再使用语音增强网络对输入的语音信号进行增强,使用fbank特征提取网络得到增强后的语音特征;
26、s62:自适应性的语音特征融合网络中,增强后的语音特征和原始语音特征作为整个融合网络的输入,先将增强后的语音特征和原始语音特征相加,然后将相加的结果同时馈送到局部注意力模块1和全局注意力模块1,经这两个注意力模块处理后分别得到局部注意力模块1输出loutput1和全局注意力模块1输出goutput1,再将loutput1和goutput1相加,相加后的结果通过一个sigmod激活函数,sigmod激活函数处理后将得到第一个逐元素掩码w1,将增强后的语音特征和原始语音特征分别与w1和(1-w1)相乘,将相乘后的结果相加,然后将相加的结果同时馈送到局部注意力模块2和全局注意力模块2,局部注意力模块1和局部注意力模块2的网络结构和初始参数相同,全局注意力模块1和全局注意力模块2的网络结构和初始参数相同;
27、经这两个注意力模块处理后,分别得到局部注意力模块2输出的loutput2和全局注意力模块2输出的goutput2,再将loutput2和goutput2相加,相加后的结果通过一个sigmod激活函数,sigmod激活函数处理后将得到第二个逐元素掩码w2,将增强后的特征和原始语音特征分别与w2和(1-w2)相乘,将相乘后的结果相加,则得到融合后的特征,公式如下:
28、
29、ff是融合后特征,fn分别表示增强后的特征和原始语音特征,w2是学习得到的逐元素掩码;
30、s63:使用融合后的特征ff作为语音识别网络的输入进行语音识别,输出字符序列的句子。
31、优选的,所述步骤s7中,使用知识图谱进行一次纠错的过程如下:
32、针对声学模型输出的字符序列的句子,使用当前进行纠错句子的前两条输出句子及后两条输出句子,共5条句子作为输入,对于所有输入的句子,分两路展开,一路对句子中的字符按unigram到7-gram的方式切分词语获取词组集,另一路提取字符单元,并逐个查询每个字符单元是否在知识图谱中提及,然后获取每个在知识图谱中被提及的字符单元所对应的目标节点,并发散性地获取这些节点周边的其他节点,将字符单元对应的节点和周边节点的这些节点词作为候选集,之后,逐一计算词组集中每个词与候选集中每个词的相似度,相似度的值为两词发音相似度和形状相似度中的最大值,设定一个阈值δ,当相似度大于阈值δ,则认为词组集中的词是错误的,使用候选集中大于阈值δ的词组对词组集中错误的词进行替换,全部替换后,得到一次纠错结果。
33、因此,本发明采用上述方法的一种基于知识图谱和语音特征融合网络的语音理解方法,具有以下好处:
34、(1)在本发明中,将多个语音处理网络级联为声学模型,解决嘈杂环境下的语音识别错误率高和语音识别纠错效果差等问题的能力;
35、(2)在本发明中,设计了自适应性的语音特征融合网络来对增强后的特征和原始语音特征进行动态融合,得到更适合用于语音识别任务的鲁棒性特征;
36、(3)在本发明中,利用知识图谱的实体和关系的语义信息,提高语音识别纠错的检错和纠错能力;
37、(4)本发明中结合深度学习的方法,设计了一种基于领域知识图谱的发散感知语音识别纠错方法,从而提高了语音识别纠错的性能和可靠性。
38、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21670.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表