一种基于CRG-MGAN网络的语音增强方法
- 国知局
- 2024-06-21 11:27:45
本发明涉及语音增强,具体涉及一种基于crg-mgan网络的语音增强方法。
背景技术:
1、原始的基于gan(生成对抗网络)的语音增强方法只预测幅度信息,而越来越多的研究表明,相位信息对提高语音质量同样重要,研究工作者采用同时模拟频谱和振幅的双路网络语音增强结构,提高了增强语音的质量,但在一定程度上牺牲了合成语音的速度,不能快速地提取语音的特征,因此,有必要提出一种基于crg-mgan(融合门控循环单元以及卷积空间门控单元的conformer度量gan网络)的语音增强方法,以解决上述问题。
技术实现思路
1、本发明的目的在于针对现有技术的不足之处,提供一种基于crg-mgan网络的语音增强方法,以解决现有技术在提高增强语音的质量的同时无法快速地提取语音的特征的问题。
2、本发明提供一种基于crg-mgan网络的语音增强方法,包括:
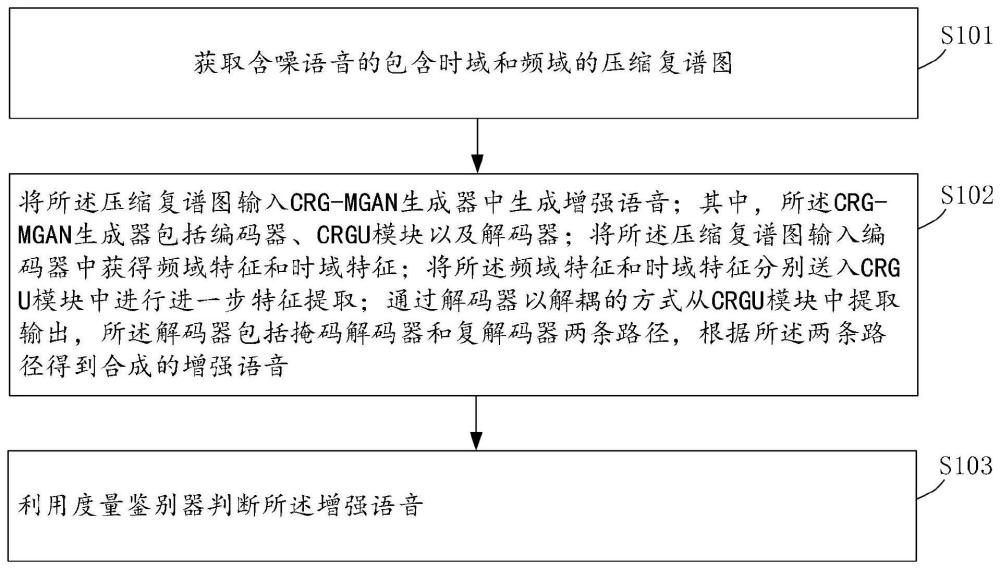
3、获取含噪语音的包含时域和频域的压缩复谱图;
4、将所述压缩复谱图输入crg-mgan生成器中生成增强语音;其中,所述crg-mgan生成器包括编码器、crgu模块以及解码器;将所述压缩复谱图输入编码器中获得频域特征和时域特征;将所述频域特征和时域特征分别送入crgu模块中进行进一步特征提取;通过解码器以解耦的方式从crgu模块中提取输出,所述解码器包括掩码解码器和复解码器两条路径,根据所述两条路径得到合成的增强语音;
5、利用度量鉴别器判断所述增强语音。
6、进一步地,获取含噪语音的包含时域和频域的压缩复谱图,包括:
7、将含噪语音进行短时傅里叶变换,将所述含噪语音的波形转换为包含时域和频域的复谱图;
8、将所述复谱图进行幂律压缩得到压缩谱图。
9、进一步地,将含噪语音进行短时傅里叶变换,将所述含噪语音的波形转换为包含时域和频域的复谱图,包括:
10、将含噪语音y∈rl×1进行短时傅里叶变换,其中l代表语音信号的长度,表示l×1维矩阵,r表示维数,将波形转换为包含时域和频域的复谱图yo∈rt×f×2,其中t和f分别代表时间维和频率维,采用的数据集为公开的语音银行+需求数据集。
11、进一步地,将所述复谱图进行幂律压缩得到压缩谱图,包括:
12、将所述复谱图进行幂律压缩得到压缩谱图式中yr和yi分别代表压缩谱图的实分量和虚分量,yp代表相位,c表示压缩指数,j代表虚部。
13、进一步地,将所述压缩复谱图输入编码器中获得频域特征和时域特征的步骤中,所述编码器由两个卷积块和一个扩展后的densenet组成,第一个卷积块由深度可分离卷积和实例归一化加prelu组成,用于将三个输入特征扩展到一个c通道的中间特征映射;扩展后的densenet包含四个密集的卷积块,用于聚合之前所有的特征图,提取出不同的特征级别;最后一个卷积块用于降维,降低计算的复杂度。
14、进一步地,将所述频域特征和时域特征分别送入crgu模块中进行进一步特征提取,包括:
15、将所述频域特征和时域特征分别输入由两个全连接层组成,中间有一个空间门控卷积单元的fgcn层,再经过轻量化处理后的多头自注意力机制和卷积模块,然后输入到g门控循环单元加线性层中,最后对其进行正则化,此外,有一个包含1*1卷积层的残差通道连接在输入和输出中。
16、进一步地,所述掩码解码器的目标是预测一个掩码,首先输入扩展的densenet,然后分别进行relu和卷积层加sigmoid激活函数运算,经过加权之后再使用prelu层来预测最终的掩码;所述复解码器直接预测实部和虚部,其结构包含一个扩张的densenet、两个卷积层以及实例归一化加prelu。
17、进一步地,利用度量鉴别器判断所述增强语音,包括:
18、分别将所述增强语音与原始干净语音输入度量鉴别器中判别真假;
19、将判别结果反馈给crg-mgan生成器,直到判别为真时,对抗训练停止,crg-mgan生成器输出增强语音。
20、进一步地,分别将所述增强语音与原始干净语音输入度量鉴别器中判别真假的步骤中,所述度量鉴别器由4个卷积块组成,每块从一个卷积层开始,然后是实例归一化和一个prelu;在卷积块之后,经过全局平均池化、两个线性层和一个sigmoid激活函数;在度量鉴别器中将pesq作为标签,对度量鉴别器进行训练来估计增强的pesq分数。
21、进一步地,将判别结果反馈给crg-mgan生成器,直到判别为真时,对抗训练停止,crg-mgan生成器输出增强语音包括:
22、将判别结果反馈给crg-mgan生成器,对crg-mgan生成器进行训练以生成类似于原始干净语音的增强语音,从而使pesq标签接近1。
23、本发明具有以下有益效果:本发明提供的一种基于crg-mgan网络的语音增强方法,改进了解码器模块,增加了包含relu与卷积层加sigmoid激活函数的双路径处理方式,提高了增强语音的质量,并改进了conformer模块,在保证特征提取的效率的同时降低了计算复杂性,提高了模型的训练速度。
技术特征:1.一种基于crg-mgan网络的语音增强方法,其特征在于,包括:
2.根据权利要求1所述的一种基于crg-mgan网络的语音增强方法,其特征在于,获取含噪语音的包含时域和频域的压缩复谱图,包括:
3.根据权利要求2所述的一种基于crg-mgan网络的语音增强方法,其特征在于,将含噪语音进行短时傅里叶变换,将所述含噪语音的波形转换为包含时域和频域的复谱图,包括:
4.根据权利要求3所述的一种基于crg-mgan网络的语音增强方法,其特征在于,将所述复谱图进行幂律压缩得到压缩谱图,包括:
5.根据权利要求4所述的一种基于crg-mgan网络的语音增强方法,其特征在于,将所述压缩复谱图输入编码器中获得频域特征和时域特征的步骤中,所述编码器由两个卷积块和一个扩展后的densenet组成,第一个卷积块由深度可分离卷积和实例归一化加prelu组成,用于将三个输入特征扩展到一个c通道的中间特征映射;扩展后的densenet包含四个密集的卷积块,用于聚合之前所有的特征图,提取出不同的特征级别;最后一个卷积块用于降维,降低计算的复杂度。
6.根据权利要求5所述的一种基于crg-mgan网络的语音增强方法,其特征在于,将所述频域特征和时域特征分别送入crgu模块中进行进一步特征提取,包括:
7.根据权利要求6所述的一种基于crg-mgan网络的语音增强方法,其特征在于,所述掩码解码器的目标是预测一个掩码,首先输入扩展的densenet,然后分别进行relu和卷积层加sigmoid激活函数运算,经过加权之后再使用prelu层来预测最终的掩码;所述复解码器直接预测实部和虚部,其结构包含一个扩张的densenet、两个卷积层以及实例归一化加prelu。
8.根据权利要求7所述的一种基于crg-mgan网络的语音增强方法,其特征在于,利用度量鉴别器判断所述增强语音,包括:
9.根据权利要求8所述的一种基于crg-mgan网络的语音增强方法,其特征在于,分别将所述增强语音与原始干净语音输入度量鉴别器中判别真假的步骤中,所述度量鉴别器由4个卷积块组成,每块从一个卷积层开始,然后是实例归一化和一个prelu;在卷积块之后,经过全局平均池化、两个线性层和一个sigmoid激活函数;在度量鉴别器中将pesq作为标签,对度量鉴别器进行训练来估计增强的pesq分数。
10.根据权利要求9所述的一种基于crg-mgan网络的语音增强方法,其特征在于,将判别结果反馈给crg-mgan生成器,直到判别为真时,对抗训练停止,crg-mgan生成器输出增强语音包括:
技术总结本发明公开一种基于CRG‑MGAN网络的语音增强方法,包括:获取含噪语音的包含时域和频域的压缩复谱图;将压缩复谱图输入CRG‑MGAN生成器中生成增强语音;CRG‑MGAN生成器包括编码器、CRGU模块以及解码器;将压缩复谱图输入编码器中获得频域特征和时域特征;将频域特征和时域特征分别送入CRGU模块中进行进一步特征提取;通过解码器以解耦的方式从CRGU模块中提取输出,解码器包括掩码解码器和复解码器两条路径,根据两条路径得到合成的增强语音;利用度量鉴别器判断增强语音。本发明提高了增强语音的质量,在保证特征提取的效率的同时降低了计算复杂性,提高了模型的训练速度。技术研发人员:于玲,张文卓,刘熙,李润卿,张娜,孙淑美受保护的技术使用者:辽宁工业大学技术研发日:技术公布日:2024/2/19本文地址:https://www.jishuxx.com/zhuanli/20240618/21668.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表