一种自适应语音识别方法及系统与流程
- 国知局
- 2024-06-21 11:27:44
本发明涉及语音识别,尤其涉及一种自适应语音识别方法及系统。
背景技术:
1、语音识别是实现人工智能的基础,很多机器人、物联网、移动设备都采用语音作为交互入口。
2、现有的语音识别模型和声学模型通常仅适用于某个特定领域或应用场景,在复杂环境中,如噪声丰富、混响严重的情况下,识别性能下降。缺乏强大的环境自适应能力,限制了在真实世界场景中的应用。而且,难以自动适应不同说话人的语音特点,尤其在存在口音、语速差异等情况下,识别准确率受限。对于复杂的语义关系和上下文理解仍存在限制,导致在高层次语义分析中效果有限。
3、另外,在现有技术中,如何根据不同的数据量和来源选择合适的模型仍然是一个挑战。这导致在不同情况下,模型性能可能不尽如人意。
技术实现思路
1、鉴于上述的分析,本发明实施例旨在提供一种自适应语音识别方法及系统,用以解决现有语音识别无法自适应不同场景的语音,不能进行个性化处理,而且在语义理解方面存在不足的问题。
2、一方面,本发明实施例提供了一种自适应语音识别方法,包括以下步骤:
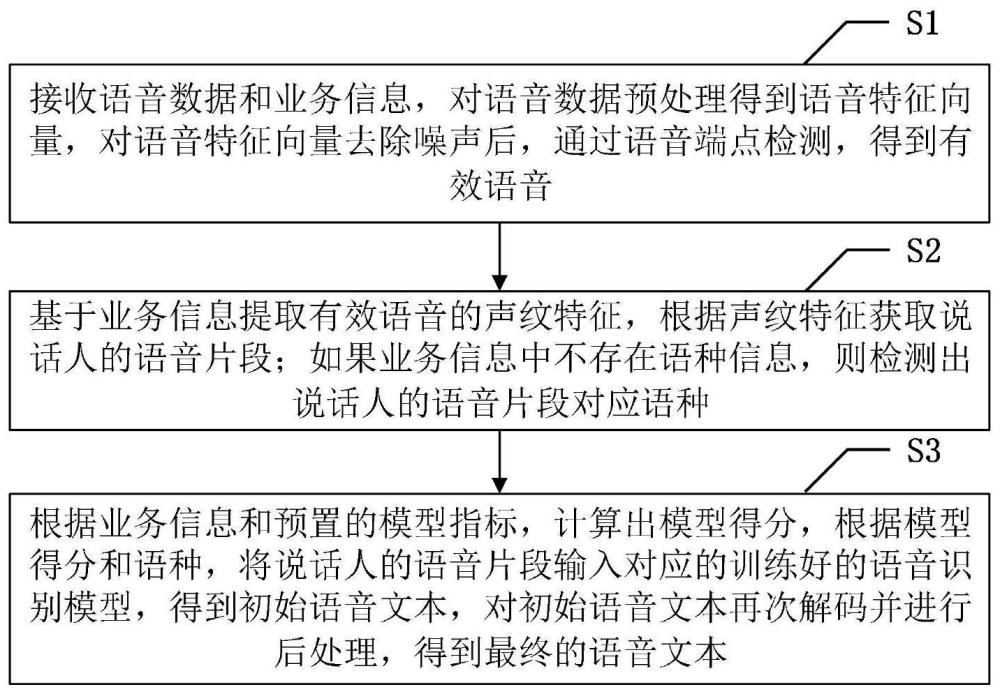
3、接收语音数据和业务信息,对语音数据预处理得到语音特征向量,对语音特征向量去除噪声后,通过语音端点检测,得到有效语音;
4、基于业务信息提取有效语音的声纹特征,根据声纹特征获取说话人的语音片段;如果业务信息中不存在语种信息,则检测出说话人的语音片段对应语种;
5、根据业务信息和预置的模型指标,计算出模型得分,根据模型得分和语种,将说话人的语音片段输入对应的训练好的语音识别模型,得到初始语音文本,对初始语音文本再次解码并进行后处理,得到最终的语音文本。
6、基于上述方法的进一步改进,语音识别模型包括各语种对应的业务领域小模型和语音大模型,根据模型得分与分数阈值的比较结果和语种进行选择;各语种对应的业务领域小模型是通过混合各业务领域的业务语音样本与公开语料库样本后对conformer模型训练而得到,各语种对应的语音大模型是利用公开语料库样本对包含编码和解码的transformer模型训练而得到。
7、基于上述方法的进一步改进,混合各语种在各业务领域的业务语音样本与公开语料库样本后对conformer模型训练时,损失函数包括交叉熵损失函数,以及,根据各业务领域的权重计算的业务权重损失函数,两者的加权和作为联合损失函数来更新conformer模型参数。
8、基于上述方法的进一步改进,根据各业务领域的权重,通过以下公式计算业务权重损失函数:
9、
10、其中,loss_w表示业务权重损失函数,wj表示第j个业务领域的权重,q(aj)表示业务语音样本在第j个业务领域的预测概率。
11、基于上述方法的进一步改进,根据业务信息和预置的模型指标,计算出模型得分,是先从业务信息中获取各项模型指标的指标值,再根据模型指标的评分规则,得到各项模型指标的得分,最后根据各项模型指标的权重,加权得到总得分,作为模型得分。
12、基于上述方法的进一步改进,基于业务信息提取有效语音的声纹特征,包括:
13、如果业务信息中的业务场景是多人场景,则对有效语音进行最小分段后,将有效语音各子段输入训练好的声纹模型中,得到各子段声纹特征;否则,直接将有效语音输入训练好的声纹模型中,得到声纹特征。
14、基于上述方法的进一步改进,根据声纹特征获取说话人的语音片段,包括:
15、如果是多人场景,则根据人数获取类别数量,通过聚类算法和余弦相似度,对各子段声纹特征进行聚类;根据聚类结果,依次合并相邻且类别相同的有效语音子段及其声纹特征,得到同一说话人的语音片段和对应的片段声纹特征,在各语音片段的信息中记录开始时间和持续时间;
16、将多人场景下各说话人任一片段声纹特征,或者,单人场景下的声纹特征,与语料库中人员的声纹特征进行比对,得到说话人信息,记录在语音片段的信息中。
17、基于上述方法的进一步改进,对初始语音文本再次解码并进行后处理,得到最终的语音文本,包括:
18、将初始语音文本传入训练好的语言模型中,得到解码后文本;将解码后文本传入训练好的改进的标点加工模型中,得到加入标点后的文本;将加入标点后的文本输入训练好的kenlm语言模型中,输出纠错后的文本;基于语法规则的wfst,对纠错后的文本进行文本逆正则化,得到最终的语音文本。
19、基于上述方法的进一步改进,改进的标点加工模型依次包括:输入数据处理层、特征提取器、标点预测器、标点添加器和输出文本生成器;其中,输入数据处理层用于根据自注意力机制在输入文本的词向量中融合上下文信息,将得到的特征向量传入特征提取器;特征提取器用于从特征向量中提取出关键特征传入标点预测器;标点预测器用于预测出每个token后的标点类型;标点添加器根据预测结果在原始文本序列中添加标点,传入输出文本生成器中,输出文本。
20、另一方面,本发明实施例提供了一种自适应语音识别系统,包括:
21、语音处理模块,用于接收语音数据和业务信息,对语音数据预处理得到语音特征向量;
22、语音检测模块,用于对语音特征向量去除噪声;通过语音端点检测,得到有效语音;
23、声纹识别模块,用于基于业务信息提取有效语音的声纹特征,根据声纹特征获取说话人的语音片段;
24、语种识别模块,用于如果业务信息中不存在语种信息,则检测出说话人的语音片段对应语种;
25、语音识别模块,用于根据业务信息和预置的模型指标,计算出模型得分,根据模型得分和语种,将说话人的语音片段输入对应的训练好的语音识别模型,得到初始语音文本;
26、文本处理模块,用于对初始语音文本再次解码并进行后处理,得到最终的语音文本。
27、与现有技术相比,本发明至少可实现如下有益效果之一:
28、1、在环境适应方面,根据语音数据的业务信息,智能调整语音分离参数,从而在复杂环境下提升识别性能;在个性化方面,系统自动学习和适应不同说话人的语音特点,提升多样化说话人的识别准确性;而且在识别出文本后进行深层语义理解,实现更精准的语义解析。
29、2、根据语音数据的业务信息,从多个维度评估语音数据的特点,结合语种自适应选择业务领域小模型或语音大模型,其中业务领域小模型适用于数据量较小且与业务领域耦合性强的语音识别,语音大模型适用于数据量大且通用的语音识别;通过实际情况自适应选择,提高了识别性能和识别准确性。
30、本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
技术特征:1.一种自适应语音识别方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的自适应语音识别方法,其特征在于,所述语音识别模型包括各语种对应的业务领域小模型和语音大模型,根据模型得分与分数阈值的比较结果和语种进行选择;所述各语种对应的业务领域小模型是通过混合各业务领域的业务语音样本与公开语料库样本后对conformer模型训练而得到,各语种对应的语音大模型是利用公开语料库样本对包含编码和解码的transformer模型训练而得到。
3.根据权利要求2所述的自适应语音识别方法,其特征在于,所述混合各语种在各业务领域的业务语音样本与公开语料库样本后对conformer模型训练时,损失函数包括交叉熵损失函数,以及,根据各业务领域的权重计算的业务权重损失函数,两者的加权和作为联合损失函数来更新conformer模型参数。
4.根据权利要求3所述的自适应语音识别方法,其特征在于,根据各业务领域的权重,通过以下公式计算业务权重损失函数:
5.根据权利要求2所述的自适应语音识别方法,其特征在于,所述根据业务信息和预置的模型指标,计算出模型得分,是先从业务信息中获取各项模型指标的指标值,再根据模型指标的评分规则,得到各项模型指标的得分,最后根据各项模型指标的权重,加权得到总得分,作为模型得分。
6.根据权利要求1所述的自适应语音识别方法,其特征在于,所述基于业务信息提取有效语音的声纹特征,包括:
7.根据权利要求6所述的自适应语音识别方法,其特征在于,根据声纹特征获取说话人的语音片段,包括:
8.根据权利要求1所述的自适应语音识别方法,其特征在于,对初始语音文本再次解码并进行后处理,得到最终的语音文本,包括:
9.根据权利要求8所述的自适应语音识别方法,其特征在于,所述改进的标点加工模型依次包括:输入数据处理层、特征提取器、标点预测器、标点添加器和输出文本生成器;其中,输入数据处理层用于根据自注意力机制在输入文本的词向量中融合上下文信息,将得到的特征向量传入特征提取器;特征提取器用于从特征向量中提取出关键特征传入标点预测器;标点预测器用于预测出每个token后的标点类型;标点添加器根据预测结果在原始文本序列中添加标点,传入输出文本生成器中,输出文本。
10.一种自适应语音识别系统,其特征在于,包括:
技术总结本发明涉及一种自适应语音识别方法及系统,属于语音识别技术领域,解决了现有语音识别的自适应、个性化和语义理解不足的问题。包括:接收语音数据和业务信息,对语音数据预处理得到语音特征向量,对语音特征向量去除噪声后,通过语音端点检测,得到有效语音;基于业务信息提取有效语音的声纹特征,根据声纹特征获取说话人的语音片段;如果业务信息中不存在语种信息,则检测出说话人的语音片段对应语种;根据业务信息和预置的模型指标,计算出模型得分,根据模型得分和语种,将说话人的语音片段输入对应的训练好的语音识别模型,得到初始语音文本,对初始语音文本再次解码并进行后处理,得到最终的语音文本。实现了语音识别的自适应性和准确性。技术研发人员:庹成,陈培华,冯永兵受保护的技术使用者:维音数码(上海)有限公司技术研发日:技术公布日:2024/2/19本文地址:https://www.jishuxx.com/zhuanli/20240618/21666.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。