基于语音韵律的数字人头部驱动装置
- 国知局
- 2024-06-21 11:29:30
本发明涉及数字人视频生成,具体涉及一种基于语音韵律的数字人头部驱动装置。
背景技术:
1、近年来,随着以深度学习为核心的人工智能技术的飞速发展,虚拟数字人技术也受到了越来越多的关注。虚拟数字人指存在于非物理世界中,由计算机图形学、图形渲染、动作捕捉、深度学习、语音合成等计算机手段创造的,具有人类外貌,表演能力,交互能力等多重特征的综合产物。虚拟数字人技术在教育、医疗、娱乐等各个领域都具有非常广阔的应用前景。
2、当前高质量虚拟数字人,例如数字说话人生成主要依赖于真人的头部与面部动作捕捉,例如高分辨率相机。这种方法高度依赖昂贵的设备和专业的表演人员。如何利用前沿人工智能技术来突破这些限制,实现高逼真的数字人生成迅速成为了当前虚拟数字人最受关注的方向之一。
3、基于人工智能技术,不再需要特殊的数据采集设备,常见的视频,语音,文本等都可以成为驱动数据源,仅需要基本计算资源的支持即可实现触手可及的驱动效果,这对于整个数字人领域来说具有极大的价值和应用潜力。然而现阶段,这种依靠人工智能的驱动方案仅能做到嘴型的对齐。如何利用简单易得的数据实现更复杂的数字人头部驱动是当前虚拟数字人中的热点问题,其旨在利用前沿人工智能,特别是跨模态生成技术解决上述问题。数字人头部驱动可以被一般性的定义为:给定一段驱动数据即语音、文本或者视频等和一张包含有目标人物图像或一段视频的参考数据,利用这些输入中包含的信息,合成一段包含目标人物自然表达驱动数据,信息量更为丰富的视频。其本质上是从不同模态的数据中提取信息,在语义层面将信息扩充,融合和对齐,最终以直观自然的视觉形式呈现出来。
4、语音驱动数字人头部的工作很早就有人开始探索,早期的方法主要是利用计算机图形学和传统机器学习的方法,生成结果质量较差,且存在较明显的人工合成痕迹。
5、在“chung j s,jamaludina,zissermana.you said that?[j].arxiv preprintarxiv:1705.02966,2017”的文献中,第一次利用卷积神经网络提取音频和图像特征,然后将不同模态的特征做融合,接下来再通过解码器对融合特征做解码,生成视频帧。但这个方法生成的结果存在很多问题,例如生成的视频帧模糊,相邻帧的内容不连续,生成的视频内容抖动明显,内容只有面部区域等。
6、在“chen l,maddox r k,duan z,et al.hierarchical cross-modal talkingface generation with dynamic pixel-wise loss[c]//proceedings of the ieee/cvfconference on computer vision and pattern recognition.2019:7832-7841”的文献中,提取参考图片的面部特征点作为人脸的先验信息,利用语音驱动面部特征点,然后基于生成的特征点生成视频。这种引入人脸表征的方式明显改善了生成过程中人脸结构的稳定性问题,所以之后的语音驱动数字人头部的工作也都开始采用这种思路。但驱动范围扩展到头部动作的生成时,二维的表征展示出很明显的局限性,因为头部动作是一个三维空间的概念,将带有头部动作的人脸进行关键点检测后,很容易产生关键点重叠,以及整个关键点轮廓变形,这就使得后续的生成模型难以准确的理解人脸的结构。
7、在“yi r,ye z,zhang j,et al.audio-driven talking face video generationwith learning-based personalized head pose[j].arxiv preprint arxiv:2002.10137,2020”的文献中,引入了3dmm方法来表征人脸,这种表征方法有巨大的优势,表情、动作、脸部形状等各属性的分离使得数字人各部分的驱动分离,不会互相干扰。
8、上述各个文献中公开的方法均将整个语音作为一个整体,模型主要学习一个从语音到头部面部动作的笼统映射。这种将语音韵律和内容信息当作一个整体的做法通常使模型陷入到一些简单映射关系的学习中,例如从语音音素到口型的映射学习,更复杂的内容,例如面部表情的变化,头部动作同语音的匹配关系等都很难学习。这种对语音韵律信息的忽略导致这些方法生成的数字人的细微表情和动作同语音的一致性较差,多样性不足,表现力普遍欠佳。
技术实现思路
1、本发明是为了解决上述问题而进行的,目的在于提供一种基于语音韵律的数字人头部驱动装置。
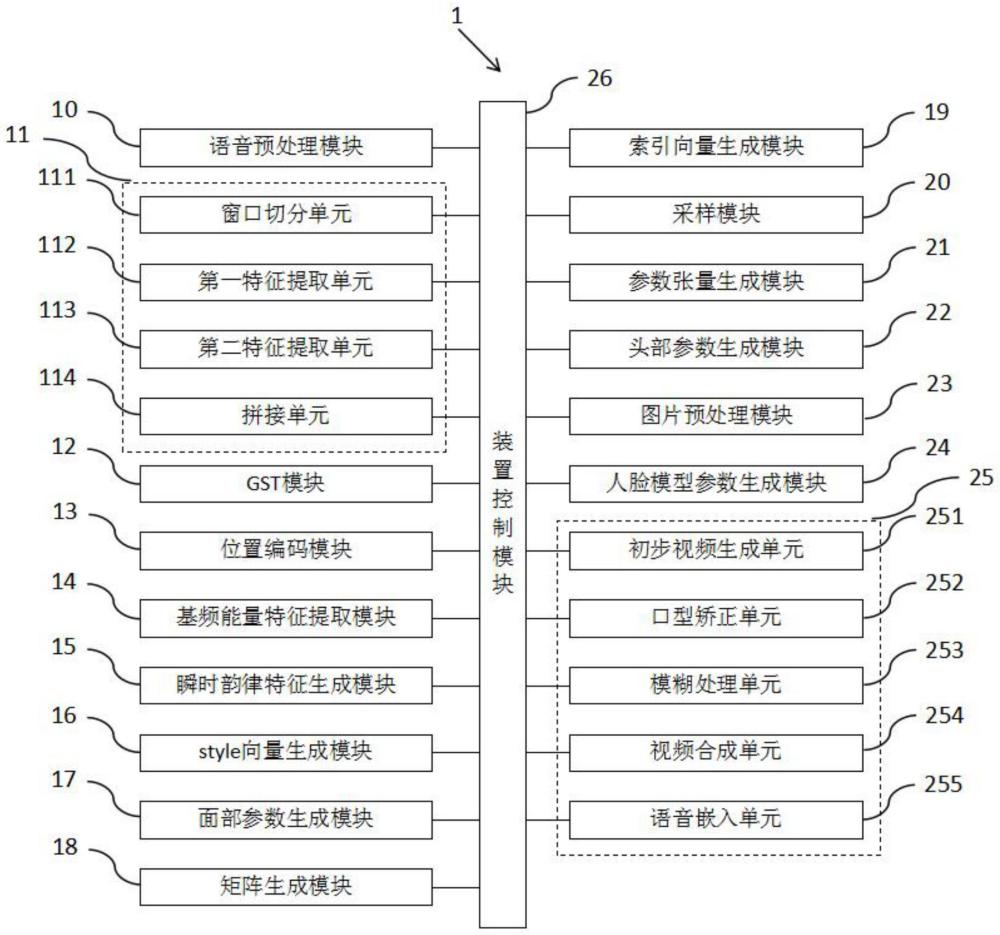
2、本发明提供了一种基于语音韵律的数字人头部驱动装置,用于根据语音数据和包含人物头像的图片数据得到数字人视频,具有这样的特征,包括:语音预处理模块,用于对语音数据进行采样,得到语音序列;语音特征提取模块,用于根据语音序列得到多个mfcc特征和语音特征;gst模块,用于对所有mfcc特征进行处理,得到全局韵律特征;位置编码模块,用于对全局韵律特征加入位置编码,得到编码后全局韵律特征;基频能量特征提取模块,用于通过滑动窗口根据基频和能量对语音序列进行特征提取,得到多个基频特征和能量特征;瞬时韵律特征生成模块,用于对所有基频特征和能量特征进行卷积操作,得到瞬时韵律特征;style向量生成模块,用于对编码后全局韵律特征和瞬时韵律特征依次进行拼接和线性变化,得到n个style向量;面部参数生成模块,包含n层卷积网络,用于将语音特征输入融合n个style向量的n层卷积网络,得到面部表情参数向量序列;矩阵生成模块,包含训练好的采样器,用于将所有基频特征和能量特征的拼接结果输入采样器,得到矩阵;索引向量生成模块,包含softmax层,用于对矩阵进行处理,得到索引向量;采样模块,存储有预设的离散特征空间,用于根据索引向量从离散特征空间进行采样,得到采样向量;参数张量生成模块,包含解码器,用于对采样向量进行解码得到参数张量;头部参数生成模块,用于对所有参数张量在时序上进行拼接,得到头部动作参数序列;图片预处理模块,用于对图片数据进行预处理,得到预处理图片数据;人脸模型参数生成模块,包含预训练好的3dmm模型,用于对预处理图片数据进行处理,得到人脸模型参数;视频生成模块,用于根据语音数据、面部表情参数向量序列、头部动作参数序列和人脸模型参数,得到数字人视频。
3、在本发明提供的基于语音韵律的数字人头部驱动装置中,还可以具有这样的特征:其中,解码器和离散特征空间的构建过程包括以下步骤:步骤s1,构建初始编码器、初始解码器和初始离散特征空间;步骤s2,从现有的视频中提取各视频帧对应的头部动作序列;步骤s3,从所有头部动作序列中选取一个头部动作序列作为优化序列;步骤s4,对优化序列进行窗口切分,得到多个动作参数;步骤s5,将各个动作参数经由初始编码器编码,得到对应的编码向量;步骤s6,根据所有编码向量更新初始离散特征空间;步骤s7,将各个动作参数经由初始解码器解码,得到对应的解码向量;步骤s8,根据编码向量和对应的解码向量以及编码向量和初始离散特征空间中对应的离散特征进行损失计算,得到第一损失计算结果;步骤s9,根据第一损失计算结果更新初始编码器和初始解码器的参数;步骤s10,重复步骤s3至步骤s9,直至达成预设的更新完成条件,则将更新好的初始解码器作为解码器,并将更新好的初始离散特征空间作为离散特征空间。
4、在本发明提供的基于语音韵律的数字人头部驱动装置中,还可以具有这样的特征:其中,采样器的构建过程包括以下步骤:步骤t1,构建初始采样器;步骤t2,对视频提取基频特征和能量特征;步骤t3,根据初始采样器结合基频特征和能量特征从离散特征空间中采样得到采样特征;步骤t4,根据解码器对采样特征进行解码,得到解码头部动作序列;步骤t5,根据解码头部动作序列与视频对应的真实头部动作序列进行损失计算,得到第二损失计算结果;步骤t6,根据第二损失计算结果优化初始采样器;步骤t7,重复步骤t2至步骤t6,直至达成预设的优化完成条件,则将优化好的初始采样器作为采样器。
5、在本发明提供的基于语音韵律的数字人头部驱动装置中,还可以具有这样的特征:其中,在图片预处理模块中,预处理的具体过程为:对图片数据进行人脸位置检测得到检测框坐标,根据检测框坐标对图片数据进行裁剪并缩放,得到预处理图片数据。
6、在本发明提供的基于语音韵律的数字人头部驱动装置中,还可以具有这样的特征:其中,语音特征提取模块包括窗口切分单元、第一特征提取单元、第二特征提取单元和拼接单元,窗口切分单元用于对语音序列进行窗口切分,得到多个窗口序列,第一特征提取单元用于对各个窗口序列进行特征提取,得到对应的mfcc特征、zcr特征和rms特征,第二特征提取单元用于对各个mfcc特征进行特征提取,得到对应的mfcc delta特征,拼接单元用于将每个窗口序列对应的mfcc特征、zcr特征、rms特征和mfcc delta特征进行拼接,得到对应的语音特征。
7、在本发明提供的基于语音韵律的数字人头部驱动装置中,还可以具有这样的特征:其中,在位置编码模块中,加入位置编码的表达式为:式中pos为位置,i为维度,d为全局韵律特征的维度。
8、在本发明提供的基于语音韵律的数字人头部驱动装置中,还可以具有这样的特征:其中,n个style向量通过adain融入n层卷积网络,adain的计算表达式为:式中fsty为style向量,x为语音特征,μ为均值操作,σ为方差操作。
9、在本发明提供的基于语音韵律的数字人头部驱动装置中,还可以具有这样的特征:其中,人脸模型参数的总维度为260维,包括1-80维的个体特征参数、80-144维的表情参数、145-224的纹理参数、225-227维的头部转角参数、228-254维的光照参数、254-257的头部移动参数以及258-260维的标定头部在画面中的位置参数。
10、在本发明提供的基于语音韵律的数字人头部驱动装置中,还可以具有这样的特征:其中,视频生成模块包括视频生成模块包括初步视频生成单元、口型矫正单元、模糊处理单元、视频合成单元和语音嵌入单元,初步视频生成单元包含预训练的pirender网络,用于根据面部表情参数向量序列、头部动作参数序列和人脸模型参数渲染得到初步视频,口型矫正单元包含预训练的wav2lip,用于根据初步视频和语音数据对初步视频中的口型进行矫正,得到矫正视频,模糊处理单元包含psfrgan网络,用于对矫正视频的各个帧进行去模糊,得到去模糊帧,视频合成单元用于将所有去模糊帧进行合并,得到合并视频,语音嵌入单元用于将语音数据嵌入合并视频,得到数字人视频。
11、发明的作用与效果
12、根据本发明所涉及的基于语音韵律的数字人头部驱动装置,因为,一方面,以全局韵律特征表征持续韵律信号,以基于基频特征和能量特征的局部韵律特征表征瞬时韵律信号,并将全局韵律特征和瞬时韵律信号融合为多个style向量,通过style向量逐步放缩面部表情特征从而构建韵律与面部动作的关系,得到面部表情参数向量序列;另一方面,考虑到头部动作的离散性和相对有限的动作模式,基于基频特征和能量特征对离散特征空间进行采样,得到头部动作参数序列,从而实现数字人头部动作和面部表情与语音数据的高度匹配。所以,本发明的基于语音韵律的数字人头部驱动装置能够生成真实自然且与驱动语音匹配的数字人视频。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21807.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表