一种基于视频大数据的音频转视频的方法与流程
- 国知局
- 2024-06-21 11:30:09
本发明涉及视频处理,尤其涉及一种基于视频大数据的音频转视频的方法。
背景技术:
1、对于内容创作者而言,带有动态图像和声音的视频是最能表达其意图的方式。传统的视频创作,需要经过人工撰写文案,编辑脚本、收集素材、视频剪辑、配旁白、配背景音乐等步骤,不仅存在一定的技术门槛,还会耗费创作者的大量时间与精力。
技术实现思路
1、本发明的目的在于提供一种基于视频大数据的音频转视频的方法,从而解决现有技术中存在的前述问题。
2、为了实现上述目的,本发明采用的技术方案如下:
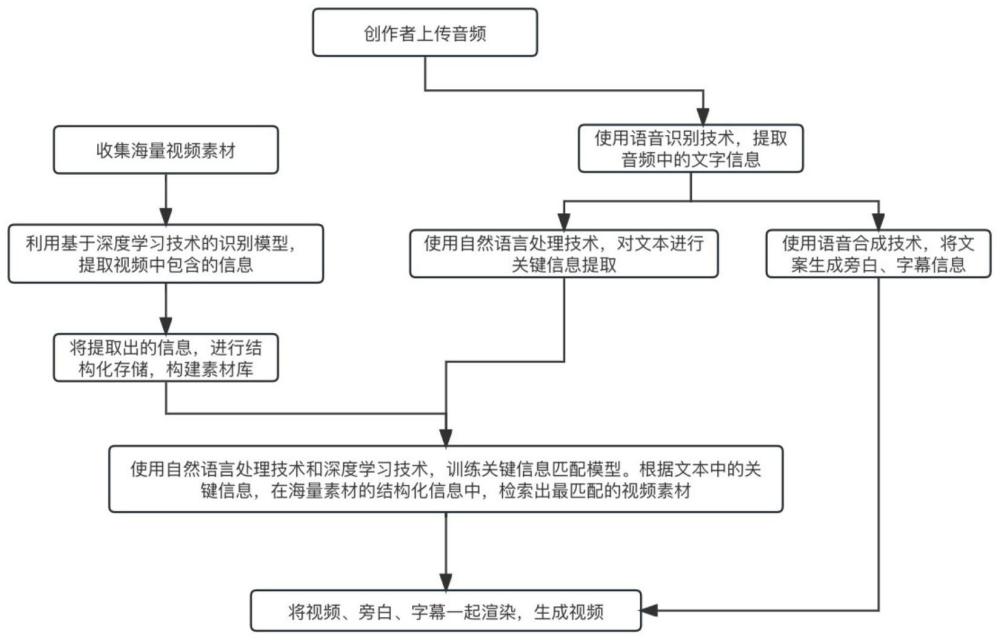
3、一种基于视频大数据的音频转视频的方法,包括如下步骤,
4、s1、素材库构建:
5、收集海量视频素材,利用基于深度学习技术的识别模型,提取视频素材中包含的信息,将提取出的信息进行结构化存储,构建素材库;
6、s2、音频信息提取:
7、利用基于深度学习的语音识别技术提取创作者上传的音频中的文字信息,利用自然语言处理技术对文字信息进行关键信息提取,并使用语音合成技术将文字信息合成旁白和字幕信息;
8、s3、素材匹配:
9、利用自然语言处理技术和深度学习技术,训练关键信息匹配模型;基于训练好的关键信息匹配模型,根据提取的关键信息在素材库中检索出最匹配的视频素材;
10、s4、视频合成:
11、将旁白和字幕信息与最匹配的视频素材进行整合渲染,生成完整的视频结果。
12、优选的,步骤s1具体包括如下内容,
13、s11、通过爬虫技术对互联网上的无版权视频素材进行抓取,并在存储对象中进行保存;
14、s12、基于深度学习技术训练识别模型,利用ffmpeg对存储的视频素材进行关键帧图像提取,利用训练好的识别模型识别关键帧图像中存在的信息,作为对视频素材的内容描述标签;
15、s13、将提取到的视频素材的信息进行结构化存储,构建素材库。
16、优选的,利用训练好的识别模型识别关键帧图像中存在的信息,包括人脸识别、对象识别和ocr识别;具体为,
17、使用haar级联、mtcnn人脸检测算法提取关键帧中的人物信息;
18、使用yolo物体检测算法,提取关键帧中的物体;
19、使用image captioning看图说话算法,提取关键帧的文字描述信息。
20、优选的,利用基于深度学习的语音识别技术提取创作者上传的音频中的文字信息,具体包括如下内容,
21、s211、对音频进行去噪、降噪、音频增强处理;
22、s212、使用mfcc梅尔频率倒谱系数方法从语音信号中提取特征;
23、s213、通过卷积神经网络cnn从特征序列中学习到语音信号与文本之间的映射关系,获取音频中的文字信息。
24、优选的,提取音频文字中的关键信息,包括关键词、命名实体、意图。
25、优选的,使用语音合成技术将文字信息合成旁白和字幕信息,具体包括如下内容,
26、s221、将音频中的文字信息使用one-hot编码转换为对应的数值表示;
27、s222、将数值表示映射到一个低维的稠密向量空间,即嵌入层;
28、s223、将嵌入层的输出作为rnn的输入,rnn通过循环连接来建模输入序列的时序关系;其中的隐藏状态会随着推理而更新,捕捉到上下文信息,从而将声学特征转换为语音波形。
29、优选的,步骤s3具体包括如下内容,
30、s31、通过word embedding将素材库中的视频信息向量化,并将音频中提取到的文字信息向量化;
31、s32、计算音频文字信息向量与每个视频信息向量间的欧氏距离,欧式距离的值越小,表示两个向量越相似,从而在素材库中匹配到最优的视频素材。
32、优选的,步骤s4具体为,使用ffmpeg将匹配到的视频素材进行拼接,再与旁白和字幕一起进行渲染,生成最终视频结果。
33、本发明的有益效果是:1、本发明无需创作者打字编写文案,只需将想法录音,就可以通过语音识别技术识别出其中的文字,通过自然语言处理技术,智能化的对文字进行分镜处理,同时提取文字中的关键信息,也无需创作者自己收集素材,降低了创作门槛,节省创作时间和精力。2、本发明可对海量视频进行分析,提取各维度的描述,构建素材信息库,再将创作者语音中的关键信息与海量视频中的描述信息进行搜索匹配,检索出最适合的视频片段,最终将语音和视频进行整体合成,快速输出视频内容。
技术特征:1.一种基于视频大数据的音频转视频的方法,其特征在于:包括如下步骤,
2.根据权利要求1所述的基于视频大数据的音频转视频的方法,其特征在于:步骤s1具体包括如下内容,
3.根据权利要求2所述的基于视频大数据的音频转视频的方法,其特征在于:利用训练好的识别模型识别关键帧图像中存在的信息,包括人脸识别、对象识别和ocr识别;具体为,
4.根据权利要求1所述的基于视频大数据的音频转视频的方法,其特征在于:利用基于深度学习的语音识别技术提取创作者上传的音频中的文字信息,具体包括如下内容,
5.根据权利要求1所述的基于视频大数据的音频转视频的方法,其特征在于:提取音频文字中的关键信息,包括关键词、命名实体、意图。
6.根据权利要求1所述的基于视频大数据的音频转视频的方法,其特征在于:使用语音合成技术将文字信息合成旁白和字幕信息,具体包括如下内容,
7.根据权利要求1所述的基于视频大数据的音频转视频的方法,其特征在于:步骤s3具体包括如下内容,
8.根据权利要求1所述的基于视频大数据的音频转视频的方法,其特征在于:步骤s4具体为,使用ffmpeg将匹配到的视频素材进行拼接,再与旁白和字幕一起进行渲染,生成最终视频结果。
技术总结本发明公开了一种基于视频大数据的音频转视频的方法,包括利用基于深度学习技术的识别模型,提取并结构化存储视频素材中包含的信息,构建素材库;利用基于深度学习的语音识别技术提取音频中的文字信息,利用自然语言处理技术对文字信息进行关键信息提取,并使用语音合成技术将文字信息合成旁白和字幕信息;利用自然语言处理技术和深度学习技术,训练关键信息匹配模型;基于训练好的关键信息匹配模型,根据提取的关键信息在素材库中检索出最匹配的视频素材;将旁白和字幕信息与最匹配的视频素材进行整合渲染,生成视频结果。优点是:无需创作者打字编写文案,只需将想法录音,就可以通过语音识别技术识别出其中的文字,创作门槛低,节省时间精力。技术研发人员:杜宇轩,张华伟受保护的技术使用者:新壹(北京)科技有限公司技术研发日:技术公布日:2024/2/25本文地址:https://www.jishuxx.com/zhuanli/20240618/21901.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表