基于前后鼻音的智能问答方法、装置、设备及存储介质与流程
- 国知局
- 2024-06-21 11:31:20
本发明涉及人工智能,尤其涉及一种基于前后鼻音的智能问答方法、装置、设备及计算机可读存储介质。
背景技术:
1、随着时代的发展,智慧语音助手逐渐扩展到人们日常生活工作的各个领域中,方便人们的生活,提高办公的效率。
2、普通话存在南北方地域差异,使得普通话也存在前后鼻音存在口音的情况,对于人机交互、智能问答产生较大的干扰。
技术实现思路
1、本发明提供一种基于前后鼻音的智能问答方法、装置、设备及存储介质,其主要目的在于通过增加语音识别准确率,实现提高智能问答效率。
2、为实现上述目的,本发明提供的一种基于前后鼻音的智能问答方法,包括:
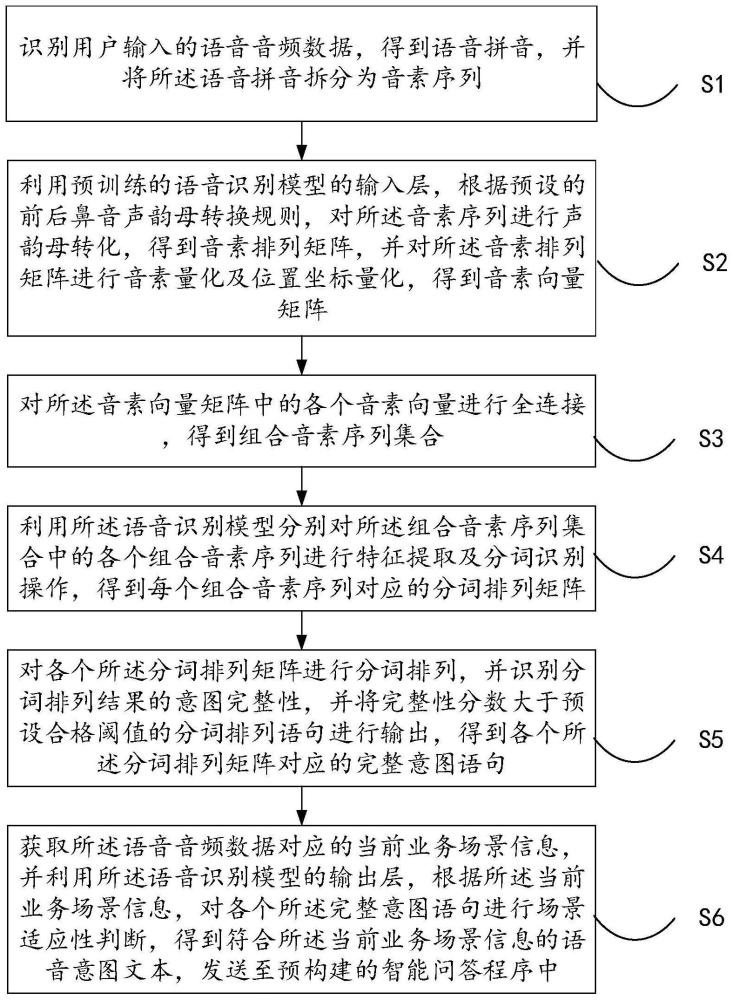
3、识别用户输入的语音音频数据,得到语音拼音,并将所述语音拼音拆分为音素序列;
4、利用预训练的语音识别模型的输入层,根据预设的前后鼻音声韵母转换规则,对所述音素序列进行声韵母转化,得到音素排列矩阵,并对所述音素排列矩阵进行音素量化及位置坐标量化,得到音素向量矩阵;
5、对所述音素向量矩阵中的各个音素向量进行全连接,得到组合音素序列集合;
6、利用所述语音识别模型分别对所述组合音素序列集合中的各个组合音素序列进行特征提取及分词识别操作,得到每个组合音素序列对应的分词排列矩阵;
7、对各个所述分词排列矩阵进行分词排列,并识别分词排列结果的意图完整性,并将完整性分数大于预设合格阈值的分词排列语句进行输出,得到各个所述分词排列矩阵对应的完整意图语句;
8、获取所述语音音频数据对应的当前业务场景信息,并利用所述语音识别模型的输出层,根据所述当前业务场景信息,对各个所述完整意图语句进行场景适应性判断,得到符合所述当前业务场景信息的语音意图文本,发送至预构建的智能问答程序中。
9、可选的,所述根据预设的前后鼻音声韵母转换规则,对所述音素序列进行声韵母转化,得到音素排列矩阵,包括:
10、将所述音素序列进行横向排列在预构建的表格中;
11、根据预设的前后鼻音声韵母转换规则,识别所述音素序列中的各个待替换音素,并根据音素对应关系,将所述前后鼻音声韵母转换规则中的可替换音素纵向填充至所述音素序列的各个待替换音素中,得到音素排列列表;
12、对所述音素排列列表进行最小外切矩阵截取操作及零值填充操作,得到音素排列矩阵。
13、可选的,所述对各个所述分词排列矩阵进行分词排列,并识别分词排列结果的意图完整性,并将完整性分数大于预设合格阈值的分词排列语句进行输出,得到各个所述分词排列矩阵对应的完整意图语句,包括:
14、将所述分词排列矩阵中的各个列中的元素分别作为全连接层各个层网络的神经节点,并进行全连接操作,得到分词排列语句集合;
15、对所述分词排列语句集合中的各个分词排序语句进行基于注意力机制的特征量化操作,并对特征量化结果进行特征提取操作,得到注意力增强特征序列;
16、对所述注意力增强特征序列进行完整性识别及意图识别,得到语句完整性分数及意图置信度分数,并对所述语句完整性分数及意图置信度分数进行加权计算,得到意图完整性分数;
17、将完整性分数大于预设合格阈值的分词排列语句进行输出,得到所述组合音素序列对应的完整意图语句。
18、可选的,所述对所述音素向量矩阵中的各个音素向量进行全连接,得到组合音素序列集合,包括:
19、将所述音素向量矩阵拆分为列集合,并将每一列中的元素作为神经节点构建神经层;
20、根据所述列集合中每一列的位置向量,将各个神经层顺序排序构建全连接层,执行全连接操作,得到组合音素序列集合。
21、可选的,所述利用所述语音识别模型分别对所述组合音素序列集合中的各个组合音素序列进行特征提取及分词识别操作之前,所述方法还包括:
22、获取含有完整性标签及意图类型标签的语句样本集合;
23、依次从所述语句样本集合中提取一个语句样本,利用预构建的语音识别模型对所述语句样本进行网络正向传播,得到意图预测结果,并通过预构建的中层网络输出接口,得到完整性预测结果;
24、通过预设的完整性-意图交叉损失值函数,计算所述完整性预测结果与所述完整性标签,及所述意图预测结果与所述意图类型标签的综合损失值;
25、最小化所述综合损失值,得到最小化时的网络模型参数,并通过前向反馈网络将所述网络模型参数进行逆向模型更新,得到更新语音识别模型;
26、判断所述综合损失值的收敛性;
27、当所述综合损失值未收敛时,返回上述依次从所述语句样本集合中提取一个语句样本,利用预构建的语音识别模型对所述语句样本进行网络正向传播的过程,对所述更新语音识别模型进行迭代更新;
28、当所述综合损失值收敛时,获取最后一次更新的更新语音识别模型作为训练完成的语音识别模型。
29、可选的,所述根据所述当前业务场景信息,对各个所述完整意图语句进行场景适应性判断,得到符合所述当前业务场景信息的语音意图文本,包括:
30、获取所述当前业务场景信息对应的常用意图类型;
31、判断各个所述完整意图语句对应的意图是否在所述常用意图类型中,将意图在所述常用意图类型中的完整意图语句进行输出。
32、可选的,所述得到符合所述当前业务场景信息的语音意图文本之后,所述方法还可以包括:
33、当用户对所述完整意图语句满意时,获取用户的身份信息,并对所述语音识别模型的模型梯度进行迁移下载,将所述模型梯度及所述身份信息进行对应存储。
34、为了解决上述问题,本发明还提供一种基于前后鼻音的智能问答装置,所述装置包括:
35、语音数据获取模块,用于识别用户输入的语音音频数据,得到语音拼音,并将所述语音拼音拆分为音素序列;
36、前后鼻音音素量化模块,用于利用预训练的语音识别模型的输入层,根据预设的前后鼻音声韵母转换规则,对所述音素序列进行声韵母转化,得到音素排列矩阵,并对所述音素排列矩阵进行音素量化及位置坐标量化,得到音素向量矩阵;
37、向量全连接组合模块,用于对所述音素向量矩阵中的各个音素向量进行全连接,得到组合音素序列集合;
38、意图完整的语句识别模块,用于利用所述语音识别模型分别对所述组合音素序列集合中的各个组合音素序列进行特征提取及分词识别操作,得到每个组合音素序列对应的分词排列矩阵,及对各个所述分词排列矩阵进行分词排列,并识别分词排列结果的意图完整性,并将完整性分数大于预设合格阈值的分词排列语句进行输出,得到各个所述分词排列矩阵对应的完整意图语句;
39、场景适应语句筛选模块,用于获取所述语音音频数据对应的当前业务场景信息,并利用所述语音识别模型的输出层,根据所述当前业务场景信息,对各个所述完整意图语句进行场景适应性判断,得到符合所述当前业务场景信息的语音意图文本,发送至预构建的智能问答程序中。
40、为了解决上述问题,本发明还提供一种电子设备,所述电子设备包括:
41、至少一个处理器;以及,
42、与所述至少一个处理器通信连接的存储器;其中,
43、所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述所述的基于前后鼻音的智能问答方法。
44、为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个计算机程序,所述至少一个计算机程序被电子设备中的处理器执行以实现上述所述的基于前后鼻音的智能问答方法。
45、本发明实施例获取用户的语音音频数据,先通过预设的前后鼻音声韵母转换规则,构建音素向量矩阵,在通过分词识别操作得到分词排序矩阵,本发明实施例通过两次全连接操作,将用户可能存在的前后鼻音变化全部考虑进去,得到分词排列结果;然后本发明实施例通过语句完整性及意图匹配当前业务场景信息,实现最优的语音意图文本输出,增加智能问答的效率。因此,本发明实施例提供的一种基于前后鼻音的智能问答方法、装置、设备及存储介质,能够在于通过增加语音识别准确率,实现提高智能问答效率。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22026.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表