基于深度学习音频分类的电影高光自动剪辑方法与流程
- 国知局
- 2024-06-21 11:31:01
本发明属于电影剪辑,具体涉及一种基于深度学习音频分类的电影高光自动剪辑方法。
背景技术:
1、数字化、信息化时代,人们生活节奏加快,逐渐习惯了高强度的信息接收方式。因此,观众观看影视作品的方式也发生了翻天覆地的改变:从电影院固定场次观看到随时随地观看;从按部就班、从头到尾欣赏到利用技术手段快速浏览,倍速观看、短视频观看等新型观看方式逐渐涌现出来。
2、随着移动智能终端的普及和移动互联网技术等不断发展,人们对移动设备的依赖性越来越强,同时兼顾碎片时间的合理利用,短视频依靠时长短、数据流量少、即用即走的优势持续吸引大量用户。故而,电影走向短视频高光剪辑是一段毕竟的道路。观看电影高光剪辑,一方面满足了观众的碎片化观影需求,另一方面也利于观众在观看完集锦后在选择感兴趣的电影整部观看,起到预告片的作用。
3、然而,电影剪辑需要耗费大量的人力时间精力。单部电影时长在1.5-3小时,挑选高光片段需要纵览整部电影,并反复观看部分片段,片段挑选时间可能会在整个电影时长的2-3倍,耗时巨大。
技术实现思路
1、鉴于以上存在的问题,本发明提供一种基于深度学习音频分类的电影高光自动剪辑方法,用于减少电影剪辑时的高光片段挑选的人力消耗。
2、为解决上述技术问题,本发明采用如下的技术方案:
3、一种基于深度学习音频分类的电影高光自动剪辑方法,包括以下步骤:
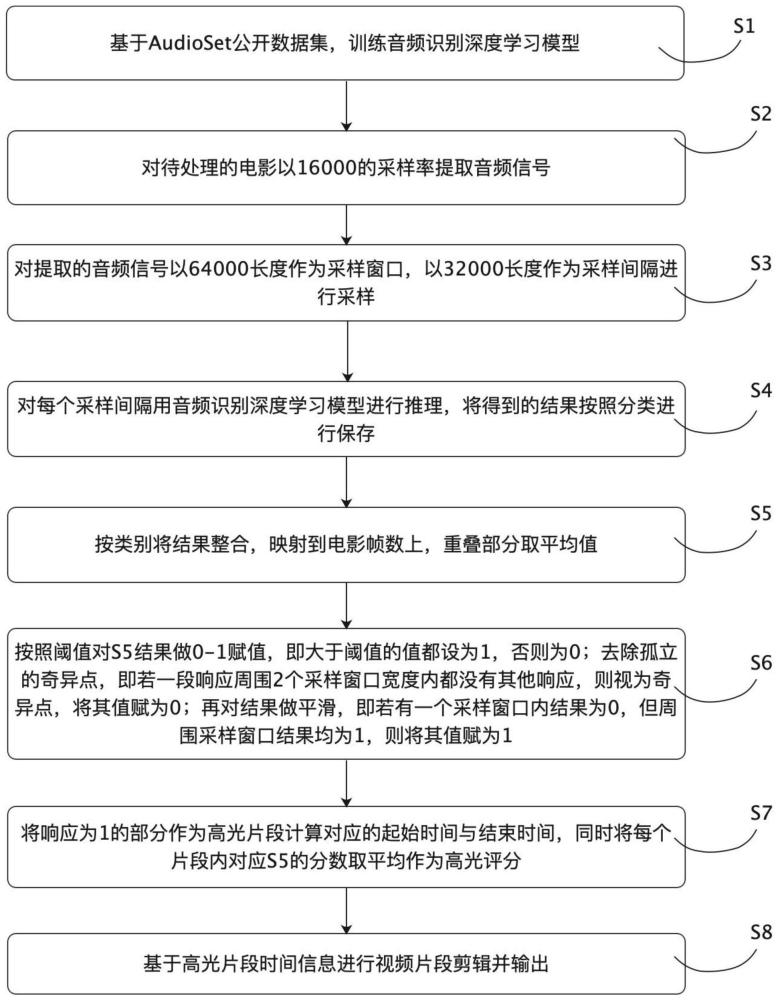
4、s1,基于audioset公开数据集,训练音频识别深度学习模型;
5、s2,对待处理的电影以16000的采样率提取音频信号;
6、s3,对提取的音频信号以64000长度作为采样窗口,以32000长度作为采样间隔进行采样;
7、s4,对每个采样间隔用音频识别深度学习模型进行推理,将得到的结果按照分类进行保存;
8、s5,按类别将结果整合,映射到电影帧数上,重叠部分取平均值;
9、s6,按照阈值对s5结果做0-1赋值,即大于阈值的值都设为1,否则为0;去除孤立的奇异点,即若一段响应周围2个采样窗口宽度内都没有其他响应,则视为奇异点,将其值赋为0;再对结果做平滑,即若有一个采样窗口内结果为0,但周围采样窗口结果均为1,则将其值赋为1;
10、s7,将响应为1的部分作为高光片段计算对应的起始时间与结束时间,同时将每个片段内对应s5的分数取平均作为高光评分;
11、s8,基于高光片段时间信息进行片段剪辑并输出。
12、一种可能的实施方式中,音频识别深度学习模型在推理时输入为t秒音频波形,需先预处理转换为每10ms使用25ms汉明窗计算的128维的对数梅尔滤波器组fbank特征序列作为输入,推理输出为该音频片段的每个分类的置信度
13、一种可能的实施方式中,s1中所述音频识别深度学习模型以16000音频采样率下的5秒音频片段经过fbank处理后生成频域特征作为输入,输出结果为527个分类的置信度,训练时的损失函数为交叉熵损失。
14、一种可能的实施方式中,输出结果为527个分类的置信度的大分类包括:(1)警报类;(2)动物声音类;(3)载具引擎类;(4)歌舞音乐类;(5)动作类;(6)战争类;(7)强烈情绪类;(8)灾难天气类。
15、采用本发明具有如下的有益效果:通过深度学习技术模型代替人力批量处理电影高光片段切割。基于训练的深度学习模型,使得用户仅需上传电影文件即可得到需要的高光片段用于欣赏或后续处理。
技术特征:1.一种基于深度学习音频分类的电影高光自动剪辑方法,其特征在于,包括以下步骤:
2.如权利要求1所述的基于深度学习音频分类的电影高光自动剪辑方法,其特征在于,音频识别深度学习模型在推理时输入为t秒音频波形,需先预处理转换为每10ms使用25ms汉明窗计算的128维的对数梅尔滤波器组fbank特征序列作为输入,推理输出为该音频片段的每个分类的置信度。
3.如权利要求1所述的基于深度学习音频分类的电影高光自动剪辑方法,其特征在于,s1中所述音频识别深度学习模型以16000音频采样率下的5秒音频片段经过fbank处理后生成频域特征作为输入,输出结果为527个分类的置信度,训练时的损失函数为交叉熵损失。
4.如权利要求3所述的基于深度学习音频分类的电影高光自动剪辑方法,其特征在于,输出结果为527个分类的大分类包括:(1)警报类;(2)动物声音类;(3)载具引擎类;(4)歌舞音乐类;(5)动作类;(6)战争类;(7)强烈情绪类;(8)灾难天气类。
技术总结本发明公开了一种基于深度学习音频分类的电影高光自动剪辑方法,包括以下步骤:S1,基于AudioSet公开数据集,训练音频识别深度学习模型;S2,对待处理的电影以16000的采样率提取音频信号;S3,对提取的音频信号以64000长度作为采样窗口,以32000长度作为采样间隔进行采样;S4,对每个采样间隔用音频识别深度学习模型进行推理,将得到的结果按照分类进行保存;S5,按类别将结果整合,映射到电影帧数上,重叠部分取平均值;S6,按照阈值对S5结果做0‑1赋值;S7,将响应为1的部分作为高光片段计算对应的起始时间与结束时间,同时将每个片段内对应S5的分数取平均作为高光评分;S8,基于高光片段时间信息进行片段剪辑并输出。技术研发人员:柯仕诚,何旭峰,田建国,顾月薪受保护的技术使用者:杭州当虹科技股份有限公司技术研发日:技术公布日:2024/2/29本文地址:https://www.jishuxx.com/zhuanli/20240618/21991.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。