一种唇音同步视频生成方法、装置、设备及介质
- 国知局
- 2024-06-21 11:31:00
本发明涉及唇音同步视频生成,具体涉及一种唇音同步视频生成方法、装置、设备及介质。
背景技术:
1、近年来,随着虚拟现实、元宇宙等领域的迅速发展,语音驱动唇形(wave to lip,wav2lip)技术在计算机视觉与音频处理融合领域成为一个备受关注的研究热点,已经有了巨大进步,现在基本可以达到生成非限定人物完整讲话视频的水平。语音驱动唇形技术是一种基于语音信号和视频图像的跨模态生成技术,它可以将语音信号转化为人物的唇形运动,并将其应用于视频生成中。用语音驱动唇形技术构建的虚拟数字人也已开始在各行各业形成生产力,例如银行客服、互联网直播等场景。
2、目前,wav2lip模型已成为该领域中广泛采用的算法之一,它利用深度学习技术能够根据语音生成唇形图像,并且实现了有效的唇音同步。然而,在实际应用中,该模型仍存在一些缺陷:1)当数据集样本特性不良时,唇音同步模型可能无法收敛或者收敛时间很长,而在需要大量视频样本的语音驱动唇形研究领域,手动修正样本非常困难,因此该算法对数据集要求较高;2)为了提高唇音同步模型的泛化能力,wav2lip的数据集包含了人脸特征跨度很大的不同人物样本,但这也导致生成的唇形视频可能出现低质量的嘴唇和错误的牙齿信息,因此,如何生成高质量的唇形视频仍然是一项挑战。
3、有鉴于此,提出本申请。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种唇音同步视频生成方法、装置、设备及介质,能够有效解决现有技术中的wav2lip模型当数据集样本特性不良时,唇音同步模型可能无法收敛或者收敛时间很长,而在需要大量视频样本的语音驱动唇形研究领域,手动修正样本非常困难,因此该算法对数据集要求较高;以及可能出现低质量的嘴唇和错误的牙齿信息的问题。
2、本发明公开了一种唇音同步视频生成方法,包括:
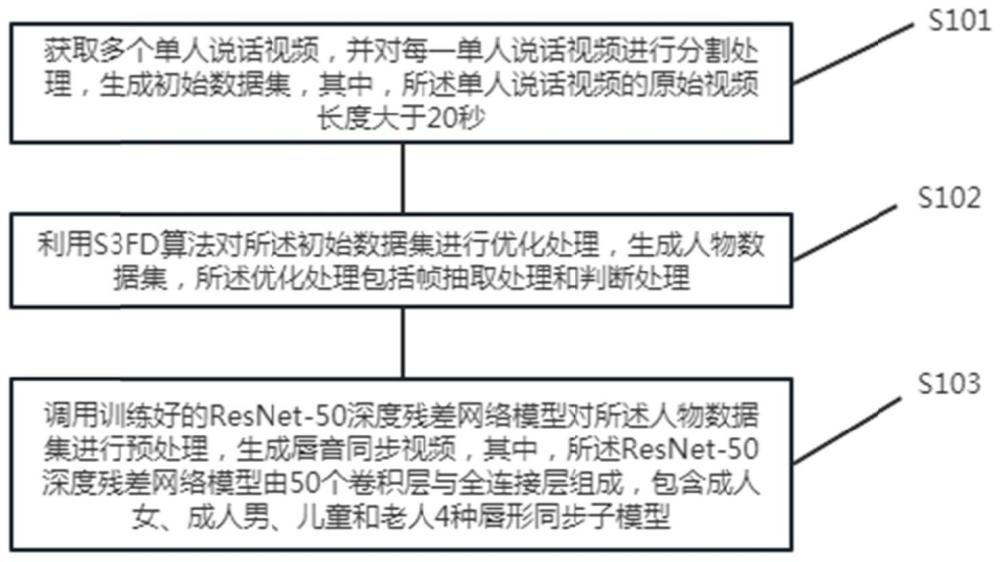
3、获取多个单人说话视频,并对每一单人说话视频进行分割处理,生成初始数据集,其中,所述单人说话视频的原始视频长度大于20秒;
4、利用s3fd算法对所述初始数据集进行优化处理,生成人物数据集,所述优化处理包括帧抽取处理和判断处理;
5、调用训练好的resnet-50深度残差网络模型对所述人物数据集进行预处理,生成唇音同步视频,其中,所述resnet-50深度残差网络模型由50个卷积层与全连接层组成,包含成人女、成人男、儿童和老人4种唇形同步子模型。
6、本发明公还开了一种唇音同步视频生成装置,包括:
7、数据集获取单元,用于获取多个单人说话视频,并对每一单人说话视频进行分割处理,生成初始数据集,其中,所述单人说话视频的原始视频长度大于20秒;
8、数据集优化单元,用于利用s3fd算法对所述初始数据集进行优化处理,生成人物数据集,所述优化处理包括帧抽取处理和判断处理;
9、唇音同步视频生成单元,用于调用训练好的resnet-50深度残差网络模型对所述人物数据集进行预处理,生成唇音同步视频,其中,所述resnet-50深度残差网络模型由50个卷积层与全连接层组成,包含成人女、成人男、儿童和老人4种唇形同步子模型。
10、本发明公还开了一种唇音同步视频生成设备,包括处理器、存储器以及存储在存储器中且被配置由处理器执行的计算机程序,处理器执行计算机程序时实现如上任意一项所述的一种唇音同步视频生成方法。
11、本发明公还开了一种可读存储介质,存储有计算机程序,计算机程序能够被该存储介质所在设备的处理器执行,以实现如上任意一项所述的一种唇音同步视频生成方法。
12、综上所述,本实施例提供的一种唇音同步视频生成方法、装置、设备及介质,采用尺度不变人脸检测器(single shot scale-invariant face detector,s3fd)算法清除数据集的噪声数据,显著减少唇音同步模型的收敛时间,也对唇形同步准确性有一定改善;同时,还提出使用残差网络(residual network,resnet)算法识别数据集中人物的性别和年龄,生成分类人物的唇音同步子模型,在确保整体模型泛化能力的前提下,提高了生成的唇形图像质量。从而解决现有技术中的wav2lip模型当数据集样本特性不良时,唇音同步模型可能无法收敛或者收敛时间很长,而在需要大量视频样本的语音驱动唇形研究领域,手动修正样本非常困难,因此该算法对数据集要求较高;以及可能出现低质量的嘴唇和错误的牙齿信息的问题。
技术特征:1.一种唇音同步视频生成方法,其特征在于,包括:
2.根据权利要求1所述的一种唇音同步视频生成方法,其特征在于,利用s3fd算法对所述初始数据集进行优化处理,生成人物数据集,具体为:
3.根据权利要求2所述的一种唇音同步视频生成方法,其特征在于,在调用训练好的resnet-50深度残差网络模型对所述人物数据集进行预处理之前,还包括:
4.根据权利要求3所述的一种唇音同步视频生成方法,其特征在于,调用训练好的resnet-50深度残差网络模型对所述人物数据集进行预处理,生成唇音同步视频,具体为:
5.一种唇音同步视频生成装置,其特征在于,包括:
6.根据权利要求5所述的一种唇音同步视频生成装置,其特征在于,所述数据集优化单元具体用于:
7.根据权利要求5所述的一种唇音同步视频生成装置,其特征在于,所述唇音同步视频生成单元具体用于:
8.一种唇音同步视频生成设备,其特征在于,包括处理器、存储器以及存储在存储器中且被配置由处理器执行的计算机程序,处理器执行计算机程序时实现如权利要求1至4任意一项所述的一种唇音同步视频生成方法。
9.一种可读存储介质,其特征在于,存储有计算机程序,计算机程序能够被该存储介质所在设备的处理器执行,以实现如权利要求1至4任意一项所述的一种唇音同步视频生成方法。
技术总结本发明提供了一种唇音同步视频生成方法、装置、设备及介质,涉及唇音同步视频生成技术领域,主要贡献包括两个方面:第一采用尺度不变人脸检测器(single shot scale‑invariant face detector,S3FD)算法清除数据集的噪声数据,显著减少唇音同步模型的收敛时间,也对唇形同步准确性有一定改善;第二,提出使用残差网络(residual network,resNet)算法识别数据集中人物的性别和年龄,生成分类人物的唇音同步子模型,在确保整体模型泛化能力的前提下,提高了生成的唇形图像质量。技术研发人员:刘莉,李林,戴彬受保护的技术使用者:厦门理工学院技术研发日:技术公布日:2024/2/29本文地址:https://www.jishuxx.com/zhuanli/20240618/21989.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表