一种虚拟数字人的交互方法及装置
- 国知局
- 2024-06-21 11:30:58
本发明涉及人工智能领域,尤其涉及一种虚拟数字人的交互方法及装置。
背景技术:
1、随着人工智能的发展,虚拟数字人的概念应运而生。虚拟数字人是指以人的仿真的2d或3d形象出现在计算机或移动设备的屏幕中的数字化外形的虚拟人物。这些虚拟数字人在许多领域中得到广泛应用,包括游戏、虚拟现实、人机交互等。
2、然而,虽然虚拟数字人的渲染方法层出不穷,但在与用户交互方面却存在真实感不足的问题。用户往往无法真正体验到与虚拟数字人的自然、接近真人的互动,导致他们对虚拟数字人的存在感到虚假和不真实。因此,提高虚拟数字人的真实感成为当前亟待解决的问题之一。
3、在虚拟数字人的交互场景中,有如下问题:1、虚拟数字人对场景内的麦克风能收到的任何人声都会做出反应,有时并不是和虚拟数字人说的话语也会被虚拟数字人接收并回复,这会导致用户体验较差;2、虚拟数字人的语音生成一般都是依据整段文字同时生成,文字长度的增加会导致语音生成的速度变慢,增加虚拟数字人的响应时间,使得用户接收到虚拟数字人的回复延迟增加。
技术实现思路
1、本发明的目的在于针对目前虚拟数字人交互方法的不足,提出一种虚拟数字人的交互方法及装置。
2、本发明是通过以下技术方案来实现的:本发明一方面公开了一种虚拟数字人的交互方法,该方法包括以下步骤:
3、s1、初始化语义不完整标志位;
4、s2、进行虚拟数字人交互循环,具体为:
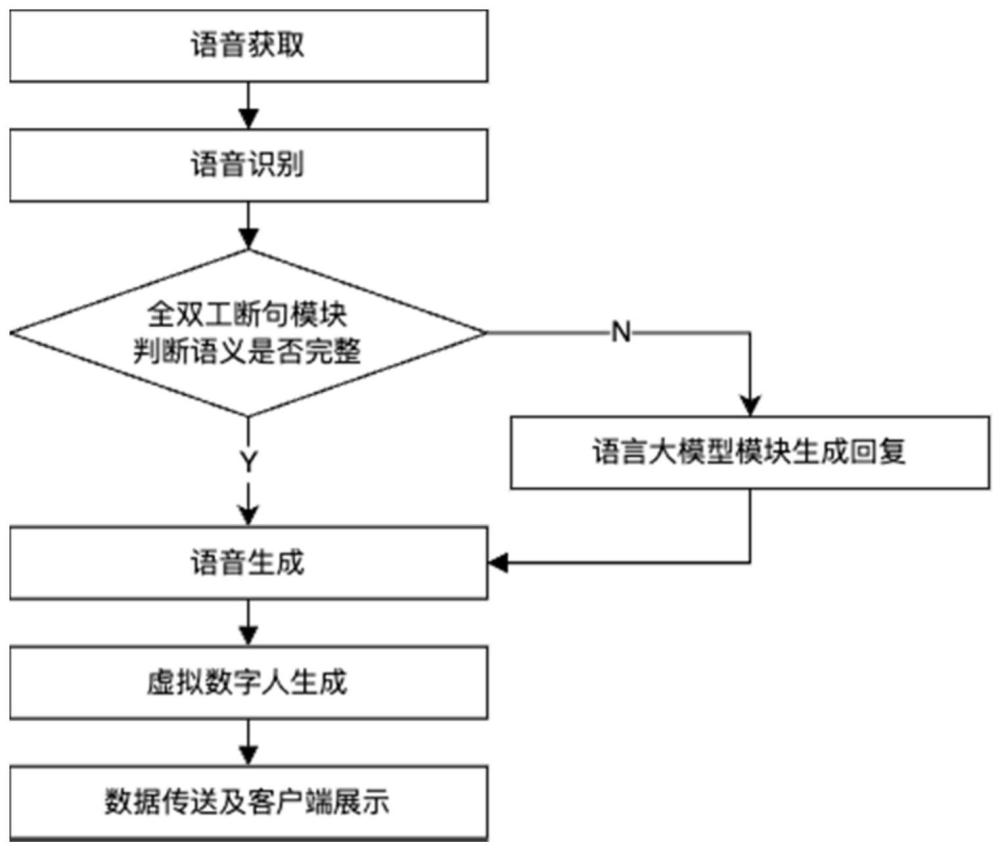
5、s2.1声音采集和图像采集,通过人眼注视屏幕检测算法判断此时采集的声音是否为有效用户声音,并对有效用户声音进行降噪;
6、s2.2、使用语音活动检测算法,检测降噪后的有效用户声音是否为人声,直至检测到的人声与之前累积的人声拼接后时长大于等于识别阈值;
7、s2.3、对大于识别阈值的人声片段进行识别,若能够识别则将人声保存为文本,若无法识别则丢弃语音并结束循环;
8、s2.4、根据语义不完整标志位进行预处理,并判断保存的文本语义是否完整,对有完整语义的语音进行流式回复生成,对标点进行截断并将语义不完整标志位设置为false;对无完整语义的语音生成针对语义完整的问句,进行标点截断并将语义不完整标志位设置为ture;
9、s2.5、对标点截断后的文本进行语音生成并加入虚拟数字人的待生成列表,根据待生成列表进行连续帧图片生成,生成正在说话的虚拟人头部身体连续帧图片或是沉默的虚拟人头部身体连续帧图片;
10、s2.6、将生成的图像和语音传输到客户端进行展示并转到步骤s2.1重新进行声音采集和图像采集。
11、进一步地,所述初始化语义不完整标志位为:将语义不完整标志位设置为false。
12、进一步地,所述识别阈值为0.6秒。
13、进一步地,所述s2.4中,根据语义不完整标志位进行预处理具体为:
14、将s2.3保存的文本作为第一文本;若语义不完整标志为true,则将第一文本与前一次的第三文本进行合并,作为第二文本;若语义不完整标志位为false,则将第一文本作为第二文本;
15、进一步地,所述s2.4中,判断保存的文本语义是否完整具体为:
16、使用全双工断句模块判断第二文本的语义是否完整,若不完整,即无法获知用户表达的意思,则生成针对语义完整的问句保存到第五文本,同时使用标点符号截断算法对第五文本进行截断,得到多个第六文本,并将第二文本保存至第三文本,将语义不完整标志置为true;
17、若完整,则将语义不完整标志置为false,表示语义已经完整,并将第二文本保存到第四文本,使用语言大模型对第四文本进行流式回复生成,得到第五文本,当遇到标点符号都进行截断,得到截断后的第六文本。
18、进一步地,所述s2.5中,对标点截断后的文本进行语音生成并加入虚拟数字人的待生成列表具体为:利用声学模型fastspeech和声码器hifigan对第六文本快速进行语音生成,得到虚拟数字人说话语音,每次生成结束后都立即将生成后的说话语音输入到虚拟数字人生成模块的由待生成列表队列。
19、进一步地,所述s2.5中根据待生成列表进行连续帧图片生成具体为:在待生成列表中获取输入的虚拟数字人说话语音,若列表不为空,则将语音的每一帧通过wav2vec2.0模型映射到音素向量上,并结合其它参数作为神经辐射场的输入,进行连续帧图片生成,得到虚拟数字人正在说话的头部、身体的连续帧图片;若列表为空,则将静音帧音素向量输入到神经辐射场中,得到虚拟数字人闭嘴不说话的头部、身体的连续帧图片。
20、进一步地,所述s2.6中,将生成的图像和语音传输到客户端进行展示具体为:将s2.5生成的每一帧图像,每次都通过json格式打包整合,其中虚拟数字人说话的第一帧图像,json中应有键存储第六文本、虚拟数字人说话语音、虚拟数字人说话语音时长、图像内容;若图片不是虚拟数字人说话的第一帧图像,或者是虚拟数字人待机沉默状态的图像,则json中只有图片内容及其键,其它内容的键不存在,将打包后的json格式数据通过socket方式传输到客户端;
21、客户端接收到传输的数据时,进行json包解码,根据虚拟数字人说话语音键的存在判断是否是虚拟数字人说话的第一帧,若是,则通过pyqt6的qlabel及qpixmap组件将图片内容进行图像播放,并对回复用户文本通过qlabel进行时长为虚拟数字人说话语音时长的显示,并对虚拟数字人说话语音通过pygame包的mixer组件进行时长为虚拟数字人说话语音时长的播放,当已经到达虚拟数字人说话语音时长时,清空显示的回复用户文本;若不是第一帧,则将图像内容进行图像播放。
22、根据说明书的另一方面,提供了一种用于实现虚拟数字人的交互方法的装置,该装置包括:语音采集模块、图像采集模块、语音识别模块、全双工断句模块、语言大模型模块、语音生成模块、虚拟数字人生成模块和客户端展示模块;所述语音采集模块用于采集用户说话的音频,所述图像采集模块用于采集用户的人脸图像,所述语音识别模块用于将用户说话的音频转换为文字,所述全双工断句模块用于判断用户的语义是否完整,所述语言大模型模块用于回复用户提出的问题,得到流式生成的答案,语音生成模块用于生成虚拟数字人说话的语音,虚拟数字人生成模块用于生成虚拟数字人的实时头部身体图像,客户端展示模块用于显示虚拟数字人图像并播放虚拟数字人语音。
23、根据说明书的另一方面,提供了一种计算机可读存储介质,其上存储有程序,所述程序被处理器执行时,实现一种虚拟数字人的交互方法。
24、本发明的有益效果如下:
25、1.使用人眼注视屏幕检测算法检测用户是否注视屏幕中的虚拟数字人,当用户没有看向虚拟数字人时,虚拟数字人不会对任何声音进行响应,可降低噪音的误识别率;
26、2.全双工断句模块判断语义完整,可以降低虚拟数字人背后的语言大模型对于不完整句子的错误理解率,保证用户语句的语义完整,让虚拟数字人可以更好地回答用户提出的问题;
27、3.使用语言大模型进行流式回复时,使用标点符号截断的方法,可以使得单次生成的语音的输入句子较短,可提高语音的生成速度,减少虚拟数字人的响应时间;
28、4.使用数据实时传输的方式将虚拟数字人生成的连续帧图片传送到客户端展示前端,可以降低虚拟数字人的响应延迟。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21984.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。