基于语音情感识别的家宽装维满意度推理方法及系统与流程
- 国知局
- 2024-06-21 11:30:28
本发明涉及人工智能,具体地说是基于语音情感识别的家宽装维满意度推理方法及系统。
背景技术:
1、随着经济、科技的发展,运营商都将用户满意度纳入了业务指标进行考察。针对家宽装维场景,为了提升客户对工单处理的满意度,减少后期投诉数量,已采用现场调查问卷、事后调查短信、电话回访的方式分析用户满意度,能够在一定程度上做到事中管控、事后评估。但数据采集情况具有极大不确定性,无法获取全量用户反馈数据。为此,运营商也引入ai技术,在多种场景下实现了投诉预测及投诉定界,致力于发掘重点投诉场景下的潜在问题,力争做到事前预测,提前处理,最大化减少投诉数量。然而,投诉预测定界在事中管控环节无法发挥效用,且主要应用于某一类别、范围,单场景、单用户针对性较弱。
2、如何基于代维人员在装维过程的语音情感,分析装维过程中代维人员的服务态度以及用户满意度,是需要解决的技术问题。
技术实现思路
1、本发明的技术任务是针对以上不足,提供基于语音情感识别的家宽装维满意度推理方法及系统,来解决如何基于代维人员在装维过程的语音情感,分析装维过程中代维人员的服务态度以及用户满意度的技术问题。
2、第一方面,本发明一种基于语音情感识别的家宽装维满意度推理方法,包括如下步骤:
3、对代维人员的装维过程进行实时录像,得到语音信号;
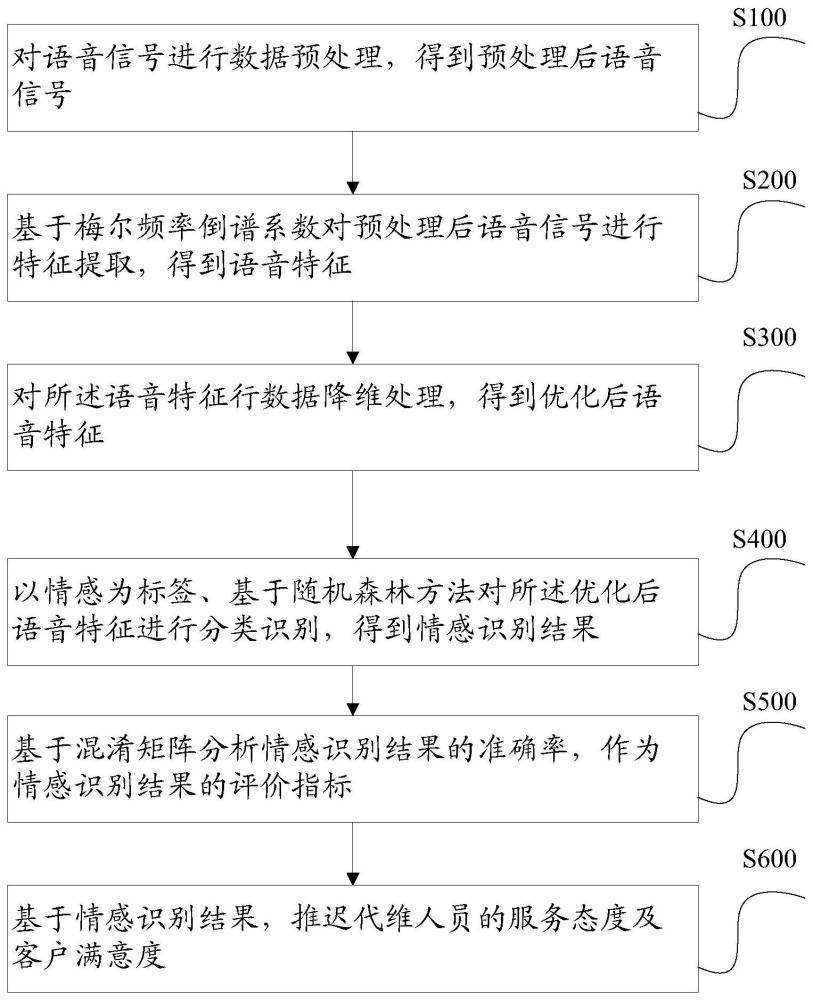
4、对语音信号进行数据预处理,得到预处理后语音信号;
5、基于梅尔频率倒谱系数对预处理后语音信号进行特征提取,得到语音特征;
6、对所述语音特征行数据降维处理,得到优化后语音特征;
7、以情感为标签、基于随机森林方法对所述优化后语音特征进行分类识别,得到情感识别结果;
8、基于混淆矩阵分析情感识别结果的准确率,作为情感识别结果的评价指标;
9、基于情感识别结果,推测代维人员的服务态度及客户满意度。
10、作为优选,对语音信号进行数据预处理,包括如下步骤:
11、预加重处理:对语音信号进行平均功率和频谱计算时,对语音信号进行预加重以减少口鼻辐射的影响;
12、分帧处理:将连续的语音信号分为具有一定长度的片段,得到多段语音信号帧,并利用帧移保存语音信号帧之间相关数据;
13、加窗处理:对每个语音信号帧加窗函数,所述窗函数包括矩形窗、汉宁窗和海明窗;
14、端点检测:通过语音端点检测方法识别出语音信号帧中的有声部分和静音部分,从而确定有声部分的起始时刻和终止时刻;
15、特征归一化:通过z归一化方法对语音信号帧中有声部分进行特征归一化;
16、降噪处理:通过降噪处理消除或降低语音信号中的噪声。
17、作为优选,基于梅尔频率倒谱系数对预处理后语音信号进行特征提取,包括如下步骤:
18、通过快速傅里叶变换对预处理后的各语音信号进行倒谱计算,得到绝对值或平方值后,通过mel滤波器组对进行快速傅里叶变换的各语音信号进行滤波,在语音信号的幅度谱上加mel滤波器组,得到mel滤波器的输出结果;
19、对mel滤波器的全部输出结果取对数,并进行离散余弦变换,得到原始的静态mfcc参数;
20、对原始的静态mfcc参数进行一阶差分,再对得到的静态mfcc参数进行二阶差分,获得动态的一阶mfcc参数和二阶mfcc参数,最后给出相应的输出特征。
21、作为优选,通过主成分分析方法对所述语音特征行数据降维处理,得到优化后语音特征。
22、作为优选,以情感为标签、基于随机森林方法对所述优化后语音特征进行分类识别,包括如下步骤:
23、以历史语音信号对应的优化后语音特征为样本数据,对样本数据进行有放回抽取,得到多个样本集合,并从候选特征中随机选取m个特征,作为当前节点下决策可备用的特征;
24、将多个样本集合作为训练样本,构建决策树;
25、在生成样本集合与确定特征后,采用cart算法进行运算,不需要修剪旁枝;
26、在确定了所需要的决策树数量之后,通过随机森林的方式对其输出进行投票,选出得票数最高的类别作为随机森林的决策。
27、第二方面,本发明一种基于语音情感识别的家宽装维满意度推理系统,用于通过如第一方面任一项所述的基于语音情感识别的家宽装维满意度推理方法进行满意度预测,所述系统包括:
28、语音信号采集模块,所述语义信号采集模块用于对代维人员的装维过程进行实时录像,得到语音信号;
29、语音信号预处理模块,所述语音信号预处理模块用于对语音信号进行数据预处理,得到预处理后语音信号;
30、语音特征提取模块,所述语音特征提取模块用于基于梅尔频率倒谱系数对预处理后语音信号进行特征提取,得到语音特征;
31、语音特征优化模块,所述语音特征优化模块用于对所述语音特征行数据降维处理,得到优化后语音特征;
32、语音识别模块,所述语音识别模块用于以情感为标签、基于随机森林方法对所述优化后语音特征进行分类识别,得到情感识别结果;
33、结果优化模块,所述结果优化模块用于基于混淆矩阵分析情感识别结果的准确率,作为情感识别结果的评价指标。
34、评价模块,所述评价模块用于基于情感识别结果,推测代维人员的服务态度及客户满意度。
35、作为优选,所述语音信号预处理模块用于执行如下对语音信号进行数据预处理:
36、预加重处理:对语音信号进行平均功率和频谱计算时,对语音信号进行预加重以减少口鼻辐射的影响;
37、分帧处理:将连续的语音信号分为具有一定长度的片段,得到多段语音信号帧,并利用帧移保存语音信号帧之间相关数据;
38、加窗处理:对每个语音信号帧加窗函数,所述窗函数包括矩形窗、汉宁窗和海明窗;
39、端点检测:通过语音端点检测方法识别出语音信号帧中的有声部分和静音部分,从而确定有声部分的起始时刻和终止时刻;
40、特征归一化:通过z归一化方法对语音信号帧中有声部分进行特征归一化;
41、降噪处理:通过降噪处理消除或降低语音信号中的噪声。
42、作为优选,所述语音特征提取模块用于执行如下基于梅尔频率倒谱系数对预处理后语音信号进行特征提取:
43、通过快速傅里叶变换对预处理后的各语音信号进行倒谱计算,得到绝对值或平方值后,通过mel滤波器组对进行快速傅里叶变换的各语音信号进行滤波,在语音信号的幅度谱上加mel滤波器组,得到mel滤波器的输出结果;
44、对mel滤波器的全部输出结果取对数,并进行离散余弦变换,得到原始的静态mfcc参数;
45、对原始的静态mfcc参数进行一阶差分,再对得到的静态mfcc参数进行二阶差分,获得动态的一阶mfcc参数和二阶mfcc参数,最后给出相应的输出特征。
46、作为优选,所述语音特征优化模块用于通过主成分分析方法对所述语音特征行数据降维处理,得到优化后语音特征。
47、作为优选,所述语音识别模块用于执行如下进行分类识别:
48、以历史语音信号对应的优化后语音特征为样本数据,对样本数据进行有放回抽取,得到多个样本集合,并从候选特征中随机选取m个特征,作为当前节点下决策可备用的特征;
49、将多个样本集合作为训练样本,构建决策树;
50、在生成样本集合与确定特征后,采用cart算法进行运算,不需要修剪旁枝;
51、在确定了所需要的决策树数量之后,通过随机森林的方式对其输出进行投票,选出得票数最高的类别作为随机森林的决策。
52、本发明的基于语音情感识别的家宽装维满意度推理方法及系统具有以下优点:
53、1、通过家宽维修线程进行音频录制,通过语音信号的分析推测用户满意度,不需要分析工单,也不需通过现场二维码、短信和电话调查进行满意度调查,提升了用户体验,并节省了人力;
54、2、通过实时识别用户与代维人员的语音情感,分析装维过程中代维人员服务态度及用户满意度,挖掘用户投诉概率高的事件节点,相较传统满意度提升手段,本方法可针对单场景单用户,分析更精准,更具针对性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21938.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表