将场景感知的上下文用于对话式人工智能系统和应用的制作方法
- 国知局
- 2024-06-21 11:36:05
背景技术:
1、车辆可以配备有对话系统,该对话系统允许乘客执行各种任务,例如控制车辆的一个或更多个操作(例如,锁定/解锁车门、锁定/解锁车窗、打开/关闭收音机等)、提供关于地标的信息(例如,提供关于建筑物、桥梁、水道等的信息)、计划活动(例如,进行预订等)、安排旅行计划(例如,交通和住宿的预订安排等)、购买物品(例如,从在线市场购买物品等)等。一些对话系统通过接收作为口头语言(例如,用户话语)的抄本生成的文本(例如,包括一个或更多个字母、单词、数字和/或符号的文本)来操作。在一些情况下,文本可以指示执行任务的请求,例如确定与地标相关联的信息。对话系统然后使用被配置为输出与请求相关联的数据的大型语言模型来处理文本。
2、然而,在一些情况下,对话系统可能难以确定与口头语言相关联的上下文。例如,如果用户正在请求关于位于环境内的地标的信息,则用户需要将地标识别为口头语言的一部分,以便对话系统向用户提供足够的反馈。例如,如果用户正在请求关于“农民餐馆”(例如,地标)的信息,口头语言可以包括“请提供关于农民餐馆的信息。”如果用户不提供该上下文,则对话系统可以继续向用户询问一个或更多个问题以确定上下文。例如,如果口头语言包括“请提供关于该餐馆的信息”,那么对话系统可以用一个问题来响应,例如“什么餐馆”。然后,用户可能需要提供额外的上下文,例如包括“农民的餐馆”的额外口头语言。这对于用户来说可能变得麻烦,因为用户可能需要在对话系统提供所请求的信息之前提供多个话语。
技术实现思路
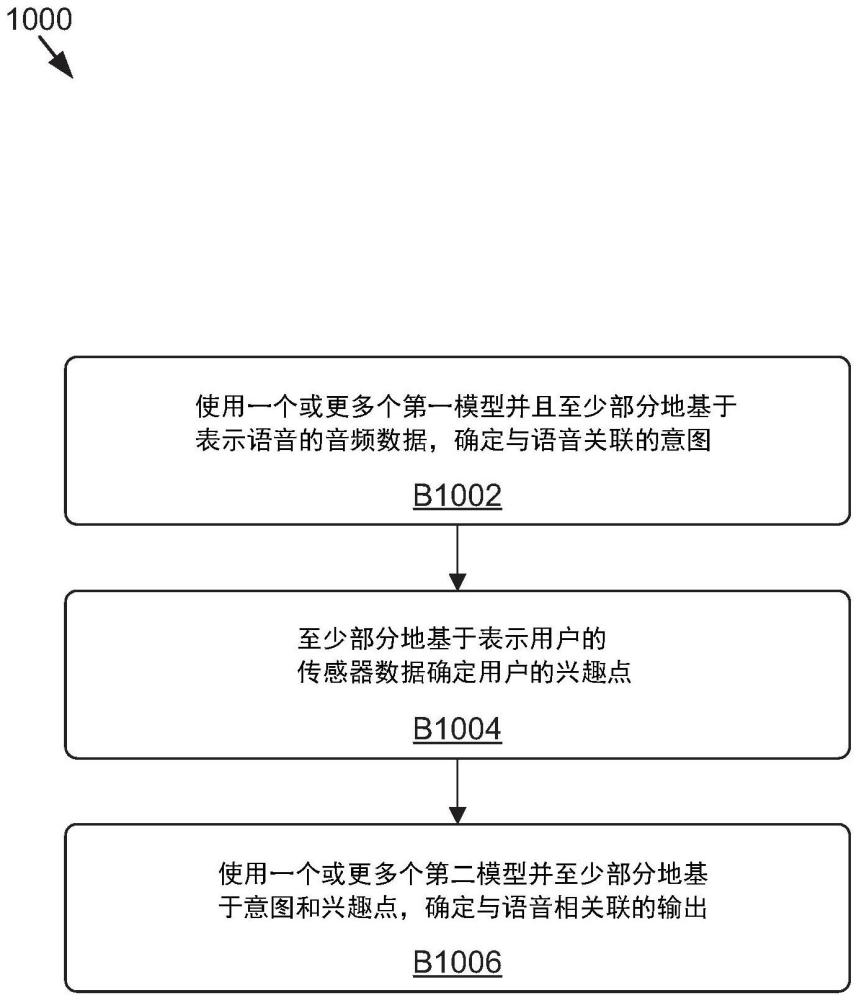
1、本公开的实施例涉及将场景感知的上下文用于对话系统和应用。公开了可以从用户接收表示语音的音频数据的系统和方法。所述系统和方法还可以使用由一个或更多个传感器生成的传感器数据和/或地图数据来识别与语音相关联的上下文。在一些示例中,系统和方法通过使用一个或更多个凝视识别和/或手势识别技术分析传感器数据和/或地图数据来确定上下文。例如,系统和方法可以使用凝视识别技术和/或手势识别技术来确定用户的兴趣点(poi),其中上下文与poi相关联。然后,系统和方法可以将与音频数据相关联的文本数据和表示上下文的上下文数据输入到一个或更多个语言模型中,该一个或更多个语言模型被配置为输出与音频数据相关的数据。例如,如果音频数据表示对关于地标的信息的请求并且上下文包括与使用poi识别的地标相关联的标识符,则语言模型可以输出表示该信息的数据。
2、与诸如上述那些的常规系统相比,当前系统输入语言模型在生成与语音相关联的输出时能够使用的额外上下文数据。例如,常规系统可以从用户接收音频数据,该音频数据表示对关于诸如桥之类的地标的信息的请求。然而,如果音频数据也不表示与地标相关联的信息,例如地标的标识符(例如,名称),则常规系统无法在不从用户接收额外信息的情况下确定所请求的信息。相反,当前系统能够使用多模态信息来确定与语音相关联的上下文。更具体地,当前系统可以使用一个或更多个传感器来识别环境内的地标,例如基于用户的凝视和/或手势(例如,用户的poi)。然后,当前系统能够使用该额外的上下文以及音频数据来确定所请求的信息。
技术特征:1.一种方法,包括:
2.根据权利要求1所述的方法,进一步包括:
3.根据权利要求2所述的方法,其中确定与所述意图相关联的所述上下文包括:至少基于所述poi确定与地标相关联的标识符,所述上下文至少包括与所述地标相关联的所述标识符。
4.根据权利要求1所述的方法,进一步包括:
5.根据权利要求1所述的方法,进一步包括:
6.根据权利要求1所述的方法,进一步包括:
7.根据权利要求1所述的方法,其中确定与所述用户相关联的所述poi包括:
8.根据权利要求1所述的方法,其中确定与所述用户相关联的所述poi包括:
9.根据权利要求1所述的方法,其中确定与所述用户相关联的所述poi包括:
10.根据权利要求1所述的方法,其中与所述语音相关联的所述输出包括以下中的至少一项:
11.一种系统,包括:
12.根据权利要求11所述的系统,其中所述一个或更多个处理单元还用于:
13.根据权利要求12所述的系统,其中所述一个或更多个处理单元还用于:
14.根据权利要求11所述的系统,其中所述一个或更多个处理单元还用于:
15.根据权利要求11所述的系统,其中所述一个或更多个处理单元用于通过以下方式确定关联的所述poi:
16.根据权利要求11所述的系统,其中所述一个或更多个处理单元还用于:
17.根据权利要求11所述的系统,其中所述系统被包括在以下的至少一个中:
18.一种处理器,包括:
19.根据权利要求18所述的处理器,其中确定所述poi包括:
20.根据权利要求18所述的处理器,其中所述处理器被包括在以下的至少一个中:
技术总结本公开涉及将场景感知的上下文用于对话式人工智能系统和应用。在各种示例中,本文描述了用于将场景感知的上下文用于对话系统和应用的技术。例如,公开了处理表示语音的音频数据以便确定与所述语音相关联的意图的系统和方法。还公开了处理表示至少一个用户的传感器数据以便确定与所述用户相关联的兴趣点的系统和方法。在一些示例中,兴趣点可以包括环境内的地标、人和/或任何其他对象。然后,所述系统和方法可以生成与所述兴趣点相关联的上下文。另外,所述系统和方法可以使用一个或更多个语言模型来处理所述意图和所述上下文。基于所述处理,所述语言模型可以输出与所述语音相关联的数据。技术研发人员:N·L·帕塔克,R·谢蒂,R·库马尔受保护的技术使用者:辉达公司技术研发日:技术公布日:2024/3/12本文地址:https://www.jishuxx.com/zhuanli/20240618/22301.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表