用于窗帘控制的智能语音识别电开关的制作方法
- 国知局
- 2024-06-21 11:35:49
本发明属于开关领域,具体涉及一种用于窗帘控制的智能语音识别电开关。
背景技术:
1、用于窗帘控制智能开关,一般分为3类,第一类是在开关的本地一侧设置有高性能的处理芯片,能够实现ai的算法。第二类是在智能开关本地配置简单的录音识别与控制电路。第三类是在智能开关本地配置简单的录音识别与控制电路并且通过网络与在线服务器连接,而第二类、第三类在市面上比较多见,而第一类很少见,几乎是在研究中才有。
2、而这几类都存在一定的技术缺陷或实际问题。
3、比如第一类,如果在开关本地侧设置ai芯片,这成本比较高,设置ai芯片的需求,是基于在语音识别过程中,单靠本地的性能低的mcu来识别,一般容易出现判断错误,语音识别精准度不够高,所以就需要一些处理能力比较强的芯片来实现软件控制甚至数据处理识别,也就是说需要根据用户的音频数据,通过软件方式,甚至通过人工智能方式基于训练模型来对用户的语音命令进行识别,这样的识别才比较精准。不过,如果在电开关的一侧设置ai芯片的配置成本特别高,甚至远超一般移动终端成本高。所以说第一类因为成本比较高,虽然性能比较好,但是几乎很少推广。
4、而对于第二类,第二类这种开关只在设备的本地设置简单的芯片,这简单的芯片是数据能力比较低的单片机,这种控制因为无法通过语音数据的复杂处理,不能实现要求高的算法,比如人工智能算法等高精度的识别算法,所以说识别准确率比较低。
5、市场上也有另外一种产品,就是前面提到的第三类,在本地与能够实现人工智能算法的远端服务器通过网络通信来交互进行识别。这第三类就是在本地获取用户的语音音频之后再发送到远端服务器。通过服务器进行识别之后,再把结果返回给本地进而进行,这种方式相当于通过在线服务器扩展了本地的运算能力。这种产品应用也比较多,但是这第三种产品在实际应用中仍然会遇到一些问题,第一,如果用户比较多时,用户同时对远端服务器发出了请求,这远端服务器运算资源能力有限导致用户的请求返回结果延迟度比较高,对于远端服务器运算要求也比较高,第二,每次用户在进行语音识别时,均需要与服务器交互,在在无网络的情况下就没有办法使用。整体来看,因为需要与服务器进行高频率远端交互导致应用效果不好,为了解决上面的这些问题,尤其是第三类产品的问题,提出了本技术。
技术实现思路
1、本发明的目的在于提供一种用于窗帘控制的智能语音识别电开关,以解决上述背景技术中提出的问题。
2、为了解决上述技术问题,本发明提供如下技术方案:
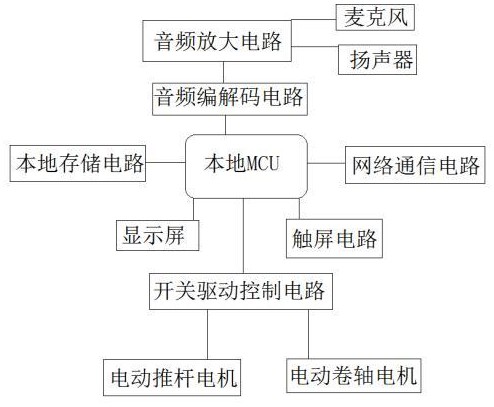
3、本发明提供一种用于窗帘控制的智能语音识别电开关,包括电连接的本地mcu、本地存储电路和网络通信电路,本地mcu还与音频编解码电路电连接,音频编解码电路与音频放大电路电连接,音频放大电路与麦克风、扬声器均电连接,麦克风用于接收用户发出语音指令对应音频,将语音音频转换为指令电信号;音频放大电路用于对指令电信号进行放大;音频编解码电路用于将放大之后的用户的指令电信号转换为用户音频数据并发送给本地mcu;本地mcu用于根据用户音频数据识别用户的控制指令;在初始的配置阶段,本地mcu还用于网络通信电路与在线服务器交互,在线服务器根据用户音频数据识别用户的控制指令,并且,通过在线服务器分析用户的控制指令对应的音频电信号特征,建立用户的音频电信号特征与用户的控制指令之间的映射表,本地mcu还用于将用户的音频电信号特征与用户的控制指令之间的映射表存储在本地存储电路;
4、在非初始的配置阶段,本地mcu还用于根据用户音频数据识别用户音频电信号特征并定义为待识别音频电信号特征,本地mcu还用于根据“用户的音频电信号特征与用户的控制指令之间的映射表”确定待识别音频电信号特征对应的用户的控制指令。
5、进一步,本地mcu还与开关驱动控制电路电连接,开关驱动控制电路与电动推杆电机、电动卷轴电机电连接;本地mcu用于根据用户音频数据识别用户的控制指令并且根据用户的控制指令向开关驱动控制电路发出控制命令,电动推杆电机、电动卷轴电机用于执行开关驱动控制电路发出的控制命令。
6、进一步,本地mcu还用于根据用户音频数据识别用户的控制指令并且根据用户的控制指令生成回复指令并返回到音频编解码电路,音频编解码电路还用于将回复指令转换为回复音频电信号,音频放大电路还用于对回复音频电信号进行放大;扬声器用于播放放大之后的回复音频电信号。
7、进一步,还包括显示屏,显示屏用于根据本地mcu控制命令输出字符或图案。
8、进一步,还包括触屏电路,触屏电路用于采集用户的触屏控制命令并且发送到本地mcu。
9、进一步,在线服务器分析用户的控制指令对应的音频电信号特征具体指,对用户的控制指令对应的音频电信号进行时域分析,建立多维度的特征向量,以该多维度的特征向量作为用户的控制指令对应的音频电信号特征。
10、进一步,对用户的控制指令对应的音频电信号进行时域分析,建立多维度的特征向量,具体包括,首先获取用户的控制指令对应的音频电信号,然后将用户的控制指令对应的音频电信号处理为时间序列,然后采集该时间序列在一定周期内的积分量、变化量、二阶导函数量,将该时间序列在一定周期内的积分量、变化量、二阶导函数量分别作为多维度的特征向量的一个分量即建立了多维度的特征向量。
11、进一步,建立用户的音频电信号特征与用户的控制指令之间的映射表具体指在线服务器通过神经网络模型先识别控制指令,然后将所识别的控制指令以目标存储变量表征,确定音频电信号特征时域分析之后的多维度的特征向量,以该多维度的特征向量指向该目标存储变量即建立用户的音频电信号特征与用户的控制指令之间的映射表。
12、进一步,在线服务器通过神经网络模型先识别控制指令具体指,先对用户音频数据进行去噪、降速、增强处理,以提高语音识别的准确度;将处理后的音频数据转换为特征向量,特征向量需要捕捉到音频数据中的音调、音色、音强;构建循环神经网络,使用语音数据集对神经网络模型进行训练,使其能够识别用户音频数据;训练过程中需要使用梯度下降和正则化来提高模型的泛化能力;在测试集上评估模型的性能,并根据评估结果进行调整和优化,调整网络结构、优化参数,模型训练完成后,将模型应用于识别控制指令。
13、有益效果:本技术仅仅需要初始的配置阶段依据在线服务器神经网络模型识别用户的控制指令,然后建立用户的音频电信号特征与用户的控制指令之间的映射表,这种映射表是基于精准的识别建立的,映射表存储在本地存储电路;在非初始的配置阶段也即使用阶段,在本地存储电路查找“用户的音频电信号特征与用户的控制指令之间的映射表”,即可确定待识别音频电信号特征对应的用户的控制指令,不需要再与服务器交互,解决了现有的问题“如果用户比较多时,用户同时对远端服务器发出了请求,这远端服务器运算资源能力有限导致用户的请求返回结果延迟度比较高,对于远端服务器运算要求也比较高;每次用户在进行语音识别时,均需要与服务器交互,在在无网络的情况下就没有办法使用”还确保了识别准确率。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22300.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。