用于场景-感知音频-视频表示的方法和系统与流程
- 国知局
- 2024-06-21 11:33:07
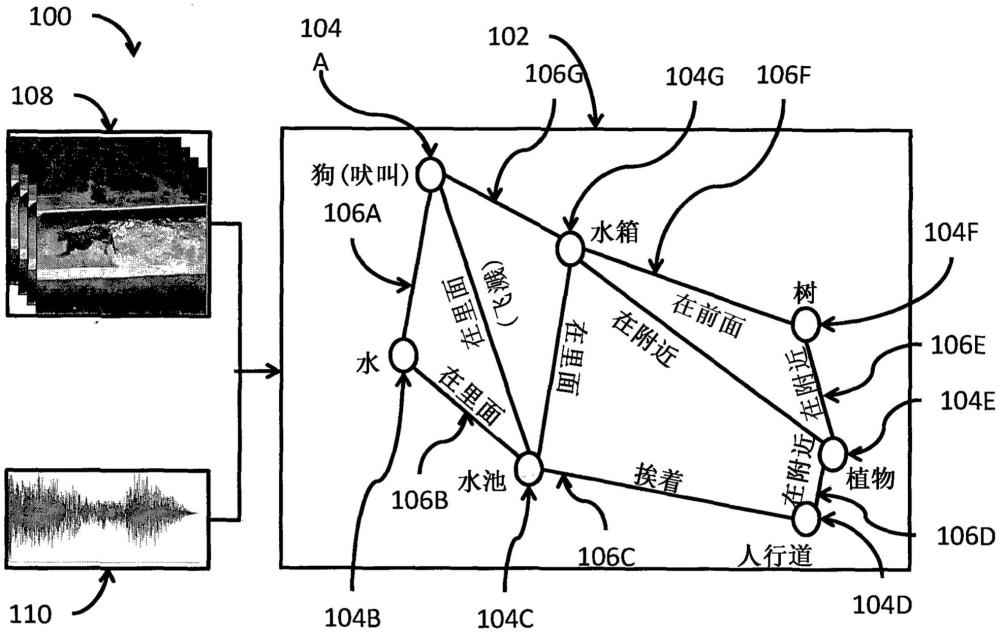
本公开总体涉及音频-视频场景-感知识别,并且更具体地涉及用于处理场景-感知音频-视频表示的方法和系统。
背景技术:
1、多年来,已经开发了捕获周围环境的场景的各种技术。例如,摄影和成像的概念在数百年前就已经发展起来,并逐渐过渡到数字领域。最初,数字图像被定义为由像素组成的二维(2d)表示,每个像素的强度或灰度等级都具有数值表示的有限离散量。然而,像素表示对于不同的图像相关应用并不总是方便的。为此,已经开发了周围环境的替代表示。
2、例如,距离场图像表示在各种图应用中都很有用,包括反锯齿、光线步进和纹理合成。例如,距离场已被广泛应用于数控(numerical control,nc)应用的模拟中。可伸缩向量图(scalable vector graphics,svg)是一种基于可扩展标记语言(extensible markuplanguage,xml)的二维图向量图像格式,支持交互和动画。发现基于svg的表示对于基于地图的应用是有利的。另外地或替代地,已经开发了各种特征提取和压缩技术,以用于更紧凑和高效的图像表示和存储。例如,已经开发了各种对象检测和分割应用来分析从像素提取的特征,而不是像素的强度。
3、在视频域中观察到针对不同应用寻找不同图像表示的类似趋势。然而,视频域呈现了更多的挑战,因为表示不仅要捕获对象在空间域中的空间变化,还要捕获对象在时间域中的演变。为此,已经开发了许多不同的表示来捕获和存储视频文件。例如,已经开发了各种有损和无损压缩技术来利用相邻视频文件中的相似性,已经开发出各种特征提取技术来提取空间和时域中的特征,已经开发出各种基于图的技术来表示视频中的不同对象在时间和空间中的关系。
4、为了进一步表示环境的场景,数字音频技术被用于声音的记录、操纵、大规模生产和分发,包括歌曲、器乐作品、播客、音效和其它声音的录制。各种技术依赖于适当的音频表示。例如,已经开发出用于数字音频的存储或传输的不同音频编码格式。音频编码格式的示例包括mp3、aac、vorbis、flac和opus。此外,类似于图像处理,已经提出了用于处理从音频文件中提取的特征的各种技术。这些基于特征的技术广泛应用于自动语音识别系统中。
5、当需要为音频模态和视频模态(modality)提供公共表示时,场景的表示就成为了更具挑战性的问题。虽然这些模态可以表示相同的场景,但是不同模态可能不会自然地彼此对齐。为此,现代技术通常通过添加预处理技术和后处理技术来分别处理这些模态。预处理技术的示例包括从视频文件导出线索以辅助音频处理,反之亦然。后处理技术的示例包括提供用于注释视频的音频字幕。
6、然而,这些技术都不适用于环境中的音频-视频场景的复杂而丰富的表示。因此,需要适用于其它应用和技术的音频-视频场景的新表示。此外,还需要一种被配置用于生成和处理这种新表示的系统和方法。
技术实现思路
1、因此,一些实施方式的目的是提供一种以高效和准确的方式处理场景的音频-视频表示的系统和方法。这种处理的示例包括生成音频-视频表示以及基于音频-视频表示执行应用特定任务。为此,在一个实施方式中,生成指示视频的场景的场景-感知音频-视频表示的基于图的表示。可以使用一个或更多个图像/视频捕获设备(诸如,一个或更多个摄像头)来捕获视频。一个或更多个摄像头可以连接到该系统,诸如用于生成场景-感知音频-视频表示的计算系统。
2、一些实施方式基于这样的实现,即,场景-感知音频-视频表示包括映射在由边连接的节点的图上的结构。图中的每个节点表示对象,例如,指示场景中的对象的视频特征。图中的每条边连接两个节点。图的每条边指示场景中的相应两个对象的交互。通过这种方式,图表示对象及其交互。
3、在一些实施方式中,可以基于场景中的对象的检测和分类来生成图表示。此外,可以基于预定可能对象集合和可能交互集合来选择图表示的节点(即,对象)和边(即,对象的交互)。节点和边的选择实施了对象和交互的唯一性。例如,对象可以被分类为人,而不是一组人,除非一组人属于可能对象集合。
4、一些实施方式基于这样的理解,即,场景包括两个对象的复杂交互,复杂交互包括空间交互和时间交互中的一者或组合。例如,所捕获的场景可以包括具有指示人、车辆或动物的不同对象的动态内容、空间域中的不同音频以及时域中的相应对象的演变。此外,场景还可以包括对象中存在的不同交互或关系。在实时示例场景中,场景可以对应于有对象(诸如处于不同动作中的人、处于运动中的车辆、处于休息中的车辆和奔跑的动物等)的繁忙街道。处于不同动作的人可以包括带着乐器的音乐家。在场景中,一些乐器可能会由相应的音乐家主动演奏,而一些乐器可能不被演奏。
5、另外地或另选地,一些实施方式的目标是生成具有复杂交互的图表示,该复杂交互包括对象的空间交互和时间交互。为此,在一些实施方式中,图表示由通过边全连接的节点组成。每个节点指示场景中的一个对象,并且每个全连接的边指示与场景的空间域和时域中的两个对象相对应的交互。
6、一些实施方式基于这样的理解,即,在交互中,一些对象可以同等贡献地发出声音。在某些情况下,对象可以在与另一个对象交互时发出声音,也可以单独对发出声音做出贡献。例如,音乐家可能在场景中一边唱歌一边弹吉他。在一些其它情况下,一些对象可能对声音生成没有同等的贡献。例如,音乐家可能在拉小提琴而不唱歌。在这种情况下,可以基于它们的交互类型来定义对发出声音没有同等贡献的那些对象。为此,在一些实施方式中,这样的对象的相应边可以包括定义交互类型的属性。在一些示例实施方式中,交互的类型可以由边的方向指示,并且由有向边连接的相应节点(即,对象)可以被区分为主对象和环境对象。例如,指示音乐家演奏的小提琴的节点对应于主对象,演奏小提琴的音乐家对应于环境对象。
7、在一些实现中,图中的节点和/或边可以与由对象或对象的交互发出的声音的音频特征相关联。例如,对象的节点(诸如,在水中戏水时吠叫的狗)可以与相应的音频特征相关联。同样,连接主对象和环境对象的边也可以与音频特征相关联。另外地或另选地,一些实施方式的另一个目的是提取特征,诸如包括场景的空间信息和时间信息的视频特征和音频特征。
8、一些实施方式基于这样的理解,即,对视频特征和音频特征的联合提取可以提高系统的整体性能。视频特征和音频特征的联合提取可以排除预处理步骤和后处理步骤,这可以提高整体性能。
9、为此,一些实施方式公开了一种音频-源分离框架,该框架将对象的单个音频与音频混合隔离。音频混合可以对应于包括不同音频信号的频率变化的混合音频声谱图。可以基于来自视频的对象的视觉以及对象的相应交互,将音频与音频混合隔离。
10、在一些实施方式中,音频-源分离框架可以包括神经网络。神经网络可以包括多个子网络,多个子网络被端到端训练以将音频特征与图的节点和/或边相关联。多个子网络可以包括基于注意力的子网络,基于注意力的子网络被训练成将不同注意力放在对象的不同交互上。
11、经训练的基于注意力的子网络可用于推导场景中的对象的视觉特征。视觉特征对应于引导音频-源分离框架的潜在听觉元素,以用于将对象的音频与音频混合隔离。例如,诸如场景中的小提琴之类的乐器的视觉特征可以引导音频-源分离框架将小提琴声音与音频混合隔离。
12、在一些实施方式中,视觉特征可以从图表示提取为一个或更多个子图。一个或更多个子图可以提供向音频特征提供正交性的嵌入向量(即,低维度向量表示)。此外,场景可以包括用于每个对象的各种声音。为此,与不同对象和/或边相关联的音频特征彼此正交。音频特征的正交性实施了各个不同音频与各种声音的分离。在一些实施方式中,与边相关联的音频特征可以由二进制掩码表示。二进制掩码通过从音频混合中分离对象的相应音频特征来分离期望的对象音频。
13、一些实施方式基于这样的理解,即,场景-感知音频-视频表示可以用作其它过程或应用的输入。例如,计算系统可以将所生成的场景-感知音频-视频表示提供给服务器,以用于执行相应应用的任务,诸如动作识别和异常检测、声音定位和增强等。可以使用各种机器学习方法在场景-感知音频-视频表示上训练计算系统。为此,音频-视频表示的结构可以用作用于训练用于执行任务的神经网络的监督学习。另外地或另选地,一些实施方式的另一个目的是使用所生成的场景-感知音频-视频表示来训练神经网络。
14、以这种方式,根据不同实施方式的图可以捕获场景的丰富而复杂的音频-视频表示。此外,图可以具有可微性质,允许通过经训练的神经网络生成图并使用所生成的图来训练其它神经网络。
15、因此,一些实施方式公开了一种非暂时性存储器,其被配置为将场景的音频-视频表示存储为通过边连接的节点的图。图中的节点指示场景中的对象的视频特征。图中的连接两个节点的边指示场景中的相应两个对象的交互。在图中,至少一个或更多个边与由相应两个对象的交互发出的声音的音频特征相关联。
16、因此,一些其它实施方式公开了一种用于生成场景的音频-视频表示的系统。该系统包括输入接口、处理器和输出接口。输入接口被配置为接受场景的音频帧和视频帧。处理器被配置为执行神经网络,该神经网络被训练为将所接受的音频帧和视频帧转换为场景的音频-视频表示的图。该图包括通过边连接的节点,其中,该图中的节点指示场景中的对象的视频特征,其中,图中的连接两个节点的边指示场景中的相应两个对象的交互,并且其中,图中的至少一个或更多个边与由两个相应对象的交互发出的声音的音频特征相关联。输出接口被配置为将场景的音频-视频表示的图存储在存储器中。
17、因此,一些其它实施方式公开了一种系统,该系统包括存储器和处理器,该存储器被配置为将场景的音频-视频表示存储为通过边连接的节点的图,其中,图中的节点指示场景中的对象的视频特征,其中,图中的连接两个节点的边指示场景中的相应两个对象的交互,并且其中,图中的至少一个或更多个边与由两个相应对象的交互发出的声音的音频特征相关联,并且所述处理器可操作地连接到存储器以使用场景的音频-视频表示的图来执行任务。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22192.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表