使用上下文信息和用户情绪的话音或语音识别的制作方法
- 国知局
- 2024-06-21 11:36:09
背景技术:
1、现代计算设备(包括蜂窝、膝上型设备、平板设备和台式计算机)使用语音识别和/或话音或语音识别来进行各种功能。语音识别提取说出的词,而话音或语音识别(称为说话者识别)标识正在说话的话音而不是说出的词。因此,语音识别确定“某人说的内容”,而话音或语音识别确定“谁说的”。语音识别便于向计算设备提供口头命令,从而消除了触摸或直接使用键盘或触摸屏的需要。话音或语音识别提供了类似的便利,但也可以用作身份验证工具。此外,标识说话者可以通过使用为该说话者定制的更恰适的话音或语音识别模型来改进语音识别。虽然当代软件/硬件已经改进了对语音识别和话音或语音识别的细微差别的暗码解译,但此类系统的准确性通常受到环境噪声和其他因素(诸如用户话音的自然日常变化)的影响。即使是试图滤除环境噪声的系统也难以计及不同位置或不同位置类型中发生的环境噪声变化,或者经常发生的用户话音变化。
技术实现思路
0、概述
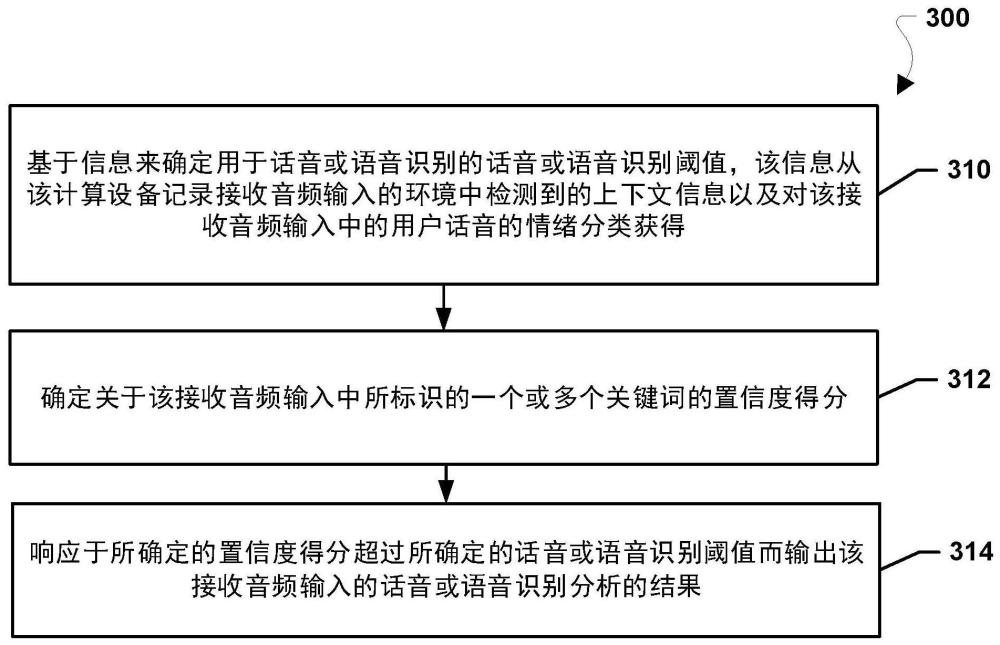
1、各个方面包括实现由计算设备的处理器执行的话音和/或语音识别的方法的方法和计算设备。各个方面包括:基于信息来确定用于话音或语音识别的话音或语音识别阈值,该信息从在该计算设备捕获接收音频输入的环境中检测到的上下文信息以及对该接收音频输入中的用户话音的情绪分类获得;确定关于该接收音频输入中所标识出的一个或多个关键词的置信度得分;以及响应于所确定的置信度得分超过所确定的话音或语音识别阈值而输出该接收音频输入的话音或语音识别分析的结果。
2、一些方面可包括:分析该接收音频输入以获得在该计算设备记录该接收音频输入的该环境中所测得该上下文信息。
3、一些方面可包括:分析该接收音频输入以确定对该接收音频输入中的该用户话音的情绪分类。
4、一些方面可包括:从远程计算设备接收情绪分类模型,其中分析该接收音频输入以确定对该接收音频输入中的该用户话音的情绪分类可以包括使用所接收的情绪分类模型来分析该接收音频输入。
5、一些方面可包括:基于该接收音频输入中的词或短语的话音或语音识别的检测率或误报率中的至少一者来确定该接收音频输入的识别水平,其中确定该话音或语音识别阈值可以包括基于该接收音频输入的所确定的识别水平来确定该话音或语音识别阈值。
6、一些方面可包括:从该接收音频输入中提取背景噪声,其中确定用于该话音或语音识别的该话音或语音识别阈值可以包括基于所提取的背景噪声来确定该话音或语音识别阈值。
7、一些方面可包括:向远程计算设备发送关于所确定的置信度得分是否超过所确定的话音或语音识别阈值的反馈。
8、一些方面可包括:从远程计算设备接收阈值模型更新,其中确定用于话音或语音识别的该话音或语音识别阈值使用所接收的阈值模型更新。一些方面可进一步包括:采用适用于由该远程计算设备在生成所接收的阈值模型更新时使用的格式向该远程计算设备发送关于由该计算设备接收的音频输入的反馈。
9、进一步方面包括包含处理器的计算设备,该处理器配置有用于执行以上概述的各方法中任一者的操作的处理器可执行指令。进一步方面包括其上存储有处理器可执行软件指令的非瞬态处理器可读存储介质,这些处理器可执行软件指令被配置成使处理器执行以上概述的任何方法的操作。进一步方面包括一种处理设备,其供在计算设备中使用且被配置成执行以上概述的各方法中任一者的操作。
技术特征:1.一种由计算设备的处理器执行的话音或语音识别的方法,包括:
2.如权利要求1所述的方法,进一步包括:
3.如权利要求1所述的方法,进一步包括:
4.如权利要求3所述的方法,进一步包括:
5.如权利要求1所述的方法,进一步包括:
6.如权利要求1所述的方法,进一步包括:
7.如权利要求1所述的方法,进一步包括:
8.如权利要求1所述的方法,进一步包括:
9.如权利要求8所述的方法,进一步包括:
10.一种计算设备,包括:
11.如权利要求10所述的计算设备,其中所述处理器被进一步配置有处理器可执行指令以:
12.如权利要求10所述的计算设备,其中所述处理器被进一步配置有处理器可执行指令以:
13.如权利要求12所述的计算设备,进一步包括:
14.如权利要求10所述的计算设备,其中所述处理器被进一步配置有处理器可执行指令以:
15.如权利要求10所述的计算设备,其中所述处理器被进一步配置有处理器可执行指令以:
16.如权利要求10所述的计算设备,进一步包括:
17.如权利要求10所述的计算设备,进一步包括:
18.如权利要求17所述的计算设备,其中所述处理器被进一步配置有处理器可执行指令以:
19.一种计算设备,包括:
20.如权利要求19所述的计算设备,进一步包括:
21.如权利要求19所述的计算设备,进一步包括:
22.如权利要求21所述的计算设备,进一步包括:
23.如权利要求19所述的计算设备,进一步包括:
24.如权利要求19所述的计算设备,进一步包括:
25.一种其上存储有处理器可执行指令的非瞬态处理器可读介质,所述处理器可执行指令被配置成使计算设备的处理器执行操作,所述操作包括:
26.如权利要求25所述的非瞬态处理器可读介质,其中所述处理器可执行指令被进一步配置成使所述计算设备的处理器执行包括以下操作的操作:
27.如权利要求25所述的非瞬态处理器可读介质,其中所述处理器可执行指令被进一步配置成使所述计算设备的处理器执行包括以下操作的操作:
28.如权利要求27所述的非瞬态处理器可读介质,其中所述处理器可执行指令被进一步配置成使所述计算设备的处理器执行包括以下操作的操作:
29.如权利要求25所述的非瞬态处理器可读介质,其中所述处理器可执行指令被进一步配置成使所述计算设备的处理器执行包括以下操作的操作:
30.如权利要求25所述的非瞬态处理器可读介质,其中所述处理器可执行指令被进一步配置成使所述计算设备的处理器执行包括以下操作的操作:
技术总结提供了一种由计算设备的处理器执行的在各种环境和/或用户情绪状态中的话音或语音识别的方法。该方法包括:基于信息来确定用于话音或语音识别的话音或语音识别阈值,该信息从在该计算设备捕获接收音频输入的环境中检测到的上下文信息以及对该接收音频输入中的用户话音的情绪分类获得(310);确定关于该接收音频输入中所标识的一个或多个关键词的置信度得分(312);以及响应于所确定的置信度得分超过所确定的话音或语音识别阈值而输出该接收音频输入的话音或语音识别分析的结果(314)。技术研发人员:魏军,董晓霞,潘启蒙,K·金,T·糖受保护的技术使用者:高通股份有限公司技术研发日:技术公布日:2024/3/12本文地址:https://www.jishuxx.com/zhuanli/20240618/22316.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表