一种文本纠错模型训练方法、装置、存储介质及电子设备与流程
- 国知局
- 2024-06-21 11:36:41
本说明书涉及计算机,尤其涉及一种文本纠错模型训练方法、装置、存储介质及电子设备。
背景技术:
1、随着人工智能和机器学习的飞速发展,利用语音识别技术将语音转译成文本的应用已十分广泛,例如,在客服与用户的沟通场景中,可以将用户发送的语音转译为文本,便于客服人员进行回复,也便于后续对两者的对话内容进行分析理解。但由于不同人的发音差异,往往会导致语音识别后的文本包含大量的错误词汇,进而导致对对话内容理解的偏差。
2、为此,需要将根据语音转译后的文本输入到本文纠错模型中进行纠错。然而,文本纠错模型的模型训练过程为有监督学习,往往依赖大量的人工标注,短期内无法积累大量的有标数据,从而无法提升文本纠错模型的性能。
3、因此,如何生成大量的有标数据,对文本纠错模型进行训练,是一个亟待解决的问题。
技术实现思路
1、本说明书实施例提供一种文本纠错模型训练方法、装置、存储介质及电子设备,以部分解决上述现有技术存在的问题。
2、本说明书实施例采用下述技术方案:
3、本说明书提供的一种文本纠错模型训练方法,所述方法包括:
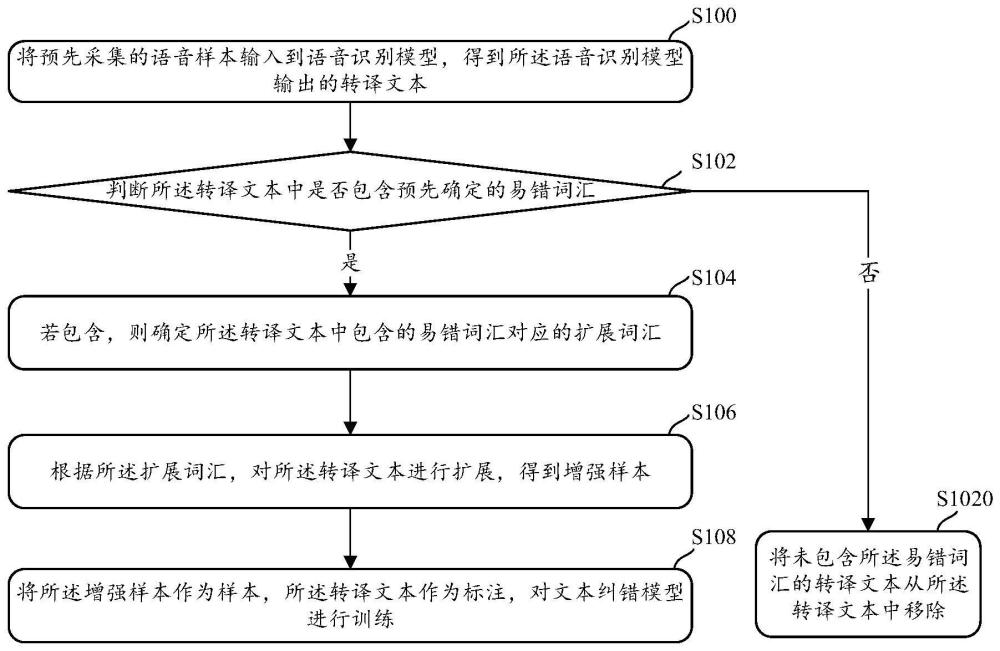
4、将预先采集的语音样本输入到语音识别模型,得到所述语音识别模型输出的转译文本;
5、判断所述转译文本中是否包含预先确定的易错词汇;
6、若包含,则确定所述转译文本中包含的易错词汇对应的扩展词汇;
7、根据所述扩展词汇,对所述转译文本进行扩展,得到增强样本;
8、将所述增强样本作为样本,所述转译文本作为标注,对文本纠错模型进行训练。
9、可选地,预先确定易错词汇,具体包括:
10、将预先确定的重点词汇输入到语音合成模型,得到所述重点词汇对应的重点词语音;
11、将所述重点词语音输入到所述语音识别模型,得到所述重点词汇对应的转译词汇;
12、针对每个所述重点词汇,判断该重点词汇与对应的转译词汇是否相同;
13、若不同,则将该重点词汇确定为易错词汇。
14、可选地,确定所述转译文本中包含的易错词汇对应的扩展词汇,具体包括:
15、确定所述转译文本中包含的易错词汇的原始音素;
16、根据所述原始音素,确定所述易错词汇对应的扩展音素;
17、根据所述易错词汇对应的扩展音素,确定所述易错词汇对应的扩展词汇。
18、可选地,根据所述扩展词汇,对所述转译文本进行扩展,得到增强样本,具体包括:
19、针对所述转译文本中包含的易错词汇对应的每个扩展词汇,使用该扩展词汇替代所述易错词汇,得到根据该扩展词汇扩展后的增强样本。
20、可选地,将所述增强样本作为样本,所述转译文本作为标注,对文本纠错模型进行训练,具体包括:
21、将所述增强样本作为样本,输入到文本纠错模型,得到已纠错文本,将所述转译文本作为标注,以所述已纠错文本和所述转译文本差异最小化为目标,对所述文本纠错模型的参数进行调整。
22、可选地,根据所述原始音素,确定所述易错词汇对应的扩展音素,具体包括:
23、针对每个原始音素,在预设的近音音素中查询该原始音素对应的近音音素;
24、将该原始音素和该原始音素对应的近音音素作为所述易错词汇的扩展音素。
25、可选地,根据所述易错词汇对应的扩展音素,确定所述易错词汇对应的扩展词汇,具体包括:
26、针对所述易错词汇的每个扩展音素,确定音素为该扩展音素且与所述易错词汇不同的词汇,作为所述易错词汇对应的扩展词汇。
27、本说明书提供的一种文本纠错模型训练装置,所述装置包括:
28、转译模块,用于将预先采集的语音样本输入到语音识别模型,得到所述语音识别模型输出的转译文本;
29、判断模块,用于判断所述转译文本中是否包含预先确定的易错词汇;
30、确定模块,用于若包含,则确定所述转译文本中包含的易错词汇对应的扩展词汇;
31、增强模块,用于根据所述扩展词汇,对所述转译文本进行扩展,得到增强样本;
32、训练模块,用于将所述增强样本作为样本,所述转译文本作为标注,对文本纠错模型进行训练。
33、本说明书提供的一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述的文本纠错模型训练方法。
34、本说明书提供的一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述的文本纠错模型训练方法。
35、本说明书实施例采用的上述至少一个技术方案能够达到以下有益效果:
36、本说明书实施例将预先采集的语音样本输入到语音识别模型,得到所述语音识别模型输出的转译文本,判断所述转译文本中是否包含预先确定的易错词汇,若包含,则确定所述转译文本中包含的易错词汇对应的扩展词汇,根据所述扩展词汇,对所述转译文本进行扩展,得到增强样本,将所述增强样本作为样本,所述转译文本作为标注,对文本纠错模型进行训练。通过这种方法,能快速构造出了大量的增强样本,并确定所述增强样本对应的标注,对所述文本纠错模型进行训练,提升所述文本纠错模型的纠错性能。
技术特征:1.一种文本纠错模型训练方法,所述方法包括:
2.如权利要求1所述的方法,预先确定易错词汇,具体包括:
3.如权利要求1所述的方法,确定所述转译文本中包含的易错词汇对应的扩展词汇,具体包括:
4.如权利要求1所述的方法,根据所述扩展词汇,对所述转译文本进行扩展,得到增强样本,具体包括:
5.如权利要求1所述的方法,将所述增强样本作为样本,所述转译文本作为标注,对文本纠错模型进行训练,具体包括:
6.如权利要求3所述的方法,根据所述原始音素,确定所述易错词汇对应的扩展音素,具体包括:
7.如权利要求6所述的方法,根据所述易错词汇对应的扩展音素,确定所述易错词汇对应的扩展词汇,具体包括:
8.一种文本纠错模型训练装置,所述装置包括:
9.一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述权利要求1-7任一项所述的方法。
10.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述权利要求1-7任一项所述的方法。
技术总结本说明书公开了一种文本纠错模型训练方法、装置、存储介质及电子设备。将预先采集的语音样本输入到语音识别模型,得到所述语音识别模型输出的转译文本,判断所述转译文本中是否包含预先确定的易错词汇,若包含,则确定所述转译文本中包含的易错词汇对应的扩展词汇,根据所述扩展词汇,对所述转译文本进行扩展,得到增强样本,将所述增强样本作为样本,所述转译文本作为标注,对文本纠错模型进行训练。通过这种方法,能快速构造出了大量的增强样本,并确定所述增强样本对应的标注,对所述文本纠错模型进行训练,提升所述文本纠错模型的纠错性能。技术研发人员:张蝶,周书恒,祝慧佳受保护的技术使用者:支付宝(杭州)信息技术有限公司技术研发日:技术公布日:2024/3/17本文地址:https://www.jishuxx.com/zhuanli/20240618/22395.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。