语音唤醒方法及相关设备与流程
- 国知局
- 2024-06-21 11:37:02
本技术涉及终端,尤其涉及一种语音唤醒方法及相关设备。
背景技术:
1、电子设备可支持语音交互功能,用户可通过语音来控制智能电子设备,例如,当用户发出“播放音乐”的语音指令时,手机可以播放音乐。一般情况下,电子设备可包括语音助手模块,当语音助手模块处于唤醒状态时,电子设备能够响应用户的语音指令;而当语音助手模块处于休眠状态时,电子设备是无法响应用户的语音指令的,因此,对于休眠状态的电子设备,需要先唤醒电子设备。
2、可能的实现中,用户可通过唤醒词唤醒电子设备,唤醒词可以为某个特定词汇,例如,产品的昵称。但用户每次在使用语音前都需要先说唤醒词,使用唤醒词唤醒电子设备,该方法不是很便捷。
技术实现思路
1、本技术实施例提供一种语音唤醒方法及相关设备,应用于终端技术领域,可以为用户提供一种免唤醒词唤醒语音助手的方法,丰富唤醒语音助手的场景,简化用户操作,提升用户的语音交互体验。
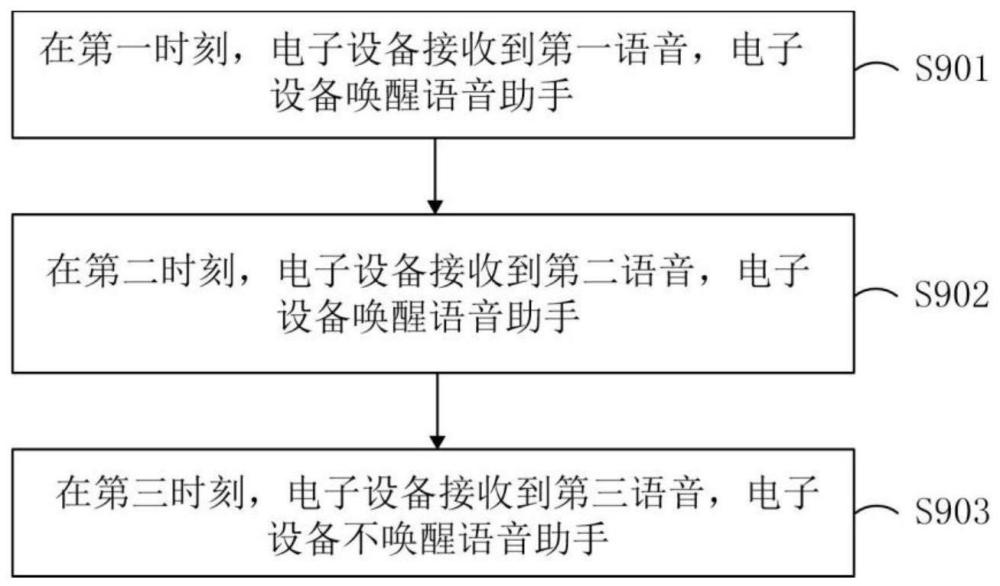
2、第一方面,本技术实施例提出一种语音唤醒方法。该方法包括:在第一时刻,电子设备接收到第一语音,电子设备唤醒语音助手;在第二时刻,电子设备接收到第二语音,电子设备唤醒语音助手;第二语音中的关键词与第一语音中的关键词不同;第一时刻早于第二时刻;在第三时刻,电子设备接收到第三语音,电子设备不唤醒语音助手;第三语音中的关键词与第一语音中的关键词不同,第三语音中的关键词与第二语音中的关键词不同;第二时刻早于第三时刻。这样,可丰富电子设备的语音交互功能的唤醒场景,简化用户操作;以及,降低误唤醒的语音助手的概率。
3、在一种可能的实现方式中,第一语音中的关键词满足下述任一项或多项词性组合:动词与名词组合、名词与形容词组合、或名词与疑问词组合;第二语音中的关键词满足下述任一项或多项词性组合:动词与名词组合、名词与形容词组合、或名词与疑问词组合;第三语音中的关键词不满足下述任一项或多项词性组合:动词与名词组合、名词与形容词组合、或名词与疑问词组合。这样,电子设备可根据语音中是否包括固定词性的词性组合判断语音是否包括命令词,可有效减少语音助手误唤醒的场景,提升语音唤醒的准确性。
4、在一种可能的实现方式中,电子设备接收到第一语音,电子设备唤醒语音助手,包括:电子设备得到第一语音;电子设备将第一语音转换为第一文本;电子设备提取第一文本的文本特征;电子设备的语义理解模型基于文本特征确定第一语音中的关键词能够唤醒语音助手;其中,文本特征包括第一文本的字数、第一文本的内容和/或第一文本的词向量;电子设备唤醒语音助手。这样,电子设备还可根据语义理解模型判定语音中是否包括命令词,可有效减少语音助手误唤醒的场景,提升语音唤醒的准确性。
5、在一种可能的实现方式中,在第一时刻,第一语音的发声源与电子设备的距离为第一距离;在第二时刻,第二语音的发声源与电子设备的距离为第一距离;在第三时刻,第三语音的发声源与电子设备的距离为第一距离;方法还包括:在第四时刻,电子设备接收到第二语音,电子设备不唤醒语音助手;第三时刻晚于第四时刻;在第四时刻,第二语音的发声源与电子设备的距离为第二距离,第二距离大于第一距离。这样,当发声源与电子设备的距离较远时,电子设备可不唤醒语音助手,进而可有效减少语音助手误唤醒的场景,提升语音唤醒的准确性。
6、在一种可能的实现方式中,在电子设备接收到第一语音之后,还包括:当第一语音的音频特征满足第一预设条件时,电子设备计算第一语音的发声源的声源角度;其中,音频特征包括相位和/或音频能量;声源角度为:第一语音的发声源到电子设备的中心点的线段与电子设备的中心点到第一麦克风的线段的夹角;第一麦克风为电子设备中远离前置摄像头的一侧的麦克风;当声源角度小于或等于预设角度时,电子设备执行判定第一语音中的关键词能否唤醒语音助手的流程。这样,电子设备可根据声源角度确定发声源相对于顶部麦克风或底部麦克风的位置,进而减少发声源靠近顶部麦克风导致的语音助手误唤醒的场景
7、在一种可能的实现方式中,电子设备还包括第二麦克风,第二麦克风为电子设备中靠近前置摄像头的一侧的麦克风;声源角度θ满足下述公式:
8、θ=acosd(τau×c/d)
9、其中,τau为第一麦克风得到第一语音的时间与第二麦克风得到第一语音的时间之间的差值,c为声速,d为第一麦克风到第二麦克风的距离,acosd为反余弦符号。这样,电子设备可根据声源角度公式计算得到声源角度,以便于电子设备判定发声源的位置。
10、在一种可能的实现方式中,第一预设条件包括下述一项或多项:第一相位与第二相位之间的相位差大于相位阈值;其中,第一相位为第一麦克风得到的第一语音的相位,第二相位为第二麦克风得到的第一语音的相位;和/或,第一音频能量与第二音频能量之间的能量差大于能量阈值;其中,第一音频能量为第一麦克风得到的第一语音的音频能量,第二音频能量为第二麦克风得到的第一语音的音频能量。这样,电子设备可基于第一预设条件确定第一语音信息是否为近讲语音,可有效减少远讲语音误唤醒语音助手的场景。
11、在一种可能的实现方式中,在电子设备接收到第一语音之前,包括:当置信度满足第二预设条件时,电子设备开启麦克风和语音增强算法;其中,置信度用于反映用户与电子设备进行语音交互的概率,置信度与电子设备的惯性测量单元imu数据、摄像头采集的图像和/或超声波模组测量的距离有关;电子设备的麦克风采集第一原始语音;电子设备接收到第一语音,包括:电子设备基于语音增强算法对第一原始语音进行处理,得到第一语音。这样,电子设备可通过置信度判定用户是否有语音交互意图,从而提升唤醒语音助手的准确性。
12、在一种可能的实现方式中,置信度满足第二预设条件,包括:第一置信度大于第一置信度的第一阈值;和/或,第二置信度大于第二置信度的第一阈值;和/或,第三置信度大于第三置信度的第一阈值;和/或,第一置信度大于第一置信度的第二阈值,和第二置信度大于第二置信度的第二阈值;和/或,第一置信度大于第一置信度的第二阈值,和第三置信度大于第三置信度的第二阈值;和/或,第二置信度大于第二置信度的第二阈值,和第三置信度大于第三置信度的第二阈值;其中,第一置信度是电子设备基于imu数据得到的;第二置信度是电子设备基于人脸在图像中的占比得到的;第三置信度是电子设备基于用户与超声波模组的距离得到的;第一置信度的第一阈值大于第一置信度的第二阈值;第二置信度的第一阈值大于第二置信度的第二阈值;第三置信度的第一阈值大于第三置信度的第二阈值。这样,电子设备可通过置信度判定用户是否有语音交互意图,从而提升唤醒语音助手的准确性。
13、第二方面,本技术实施例提供一种终端设备,终端设备也可以称为终端(terminal)、用户设备(user equipment,ue)、移动台(mobile station,ms)、移动终端(mobile terminal,mt)等。终端设备可以是手机(mobile phone)、智能电视、穿戴式设备、平板电脑(pad)、带无线收发功能的电脑、虚拟现实(virtual reality,vr)终端设备、增强现实(augmented reality,ar)终端设备、工业控制(industrial control)中的无线终端、无人驾驶(self-driving)中的无线终端、远程手术(remote medical surgery)中的无线终端、智能电网(smart grid)中的无线终端、运输安全(transportation safety)中的无线终端、智慧城市(smart city)中的无线终端、智慧家庭(smart home)中的无线终端等等。
14、该终端设备包括:包括:处理器和存储器;存储器存储计算机执行指令;处理器执行存储器存储的计算机执行指令,使得终端设备执行如第一方面的方法。
15、第三方面,本技术实施例提供一种计算机可读存储介质,计算机可读存储介质存储有计算机程序。计算机程序被处理器执行时实现如第一方面的方法。
16、第四方面,本技术实施例提供一种计算机程序产品,计算机程序产品包括计算机程序,当计算机程序被运行时,使得计算机执行如第一方面的方法。
17、第五方面,本技术实施例提供了一种芯片,芯片包括处理器,处理器用于调用存储器中的计算机程序,以执行如第一方面所述的方法。
18、应当理解的是,本技术的第二方面至第五方面与本技术的第一方面的技术方案相对应,各方面及对应的可行实施方式所取得的有益效果相似,不再赘述。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22456.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。