一种语音交互教学方法、装置及眼镜
- 国知局
- 2024-06-21 11:36:58
本发明涉及教育和可穿戴智能设备的,更具体地,涉及一种语音交互教学方法,以及能够实现上述方法的装置及眼镜。
背景技术:
1、随着科技的发展,语音交互技术受到越来越多的关注,在儿童和视障人士的教育领域也得到了广泛的应用。语音交互技术是指通过语音输入和语音输出的方式进行人机交互,通常是使用语音识别、语音合成、语音认证等技术,来实现对计算机的控制。
2、现有的语音交互教学方法,大多数以被动的,或称为接收式的方式参与教学互动,通常是要求使用者先输入语音指令,处理器接收到语音指令后,在系统或者云端中搜寻到对应结果,然后通过语音反馈给使用者。对于儿童来说,这种交互教学方式并不能起到很好的教学效果,这是因为,一方面,儿童的独立思考能力可能还不足以支撑其提出关键性问题,导致教学效果事倍功半,另一方面,儿童的注意力难以长时间保持集中,他们需要外界因素加以引导。换句话说,在学习过程中,大部分儿童是作为一个信息接收者的身份,如以被动的方式应用教学互动,则不能起到很好的引导效果。
3、因此,亟需提出一种能够主动式介入、引导儿童的语音交互教学方法,而且,发明人通过研究发现,对于大部分视障人士来说,该主动式交互教学方法也同样十分适用。
技术实现思路
1、本发明目的在于克服于现有的语音交互无法主动介入、主动引导的缺陷,提供一种语音交互教学方法,利用主动式教学,具体包括自主授课、智能问答、口语练习模块,辅以书籍阅读的功能,有利于提高儿童交互式学习的积极性和学习效果,并且对视障人士也同样适用。本发明还提供一种装置及眼镜,能够执行上述语音交互教学方法。
2、为解决上述技术问题,本发明采用的技术方案是:
3、本发明提供了一种语音交互教学方法,包括以下步骤:
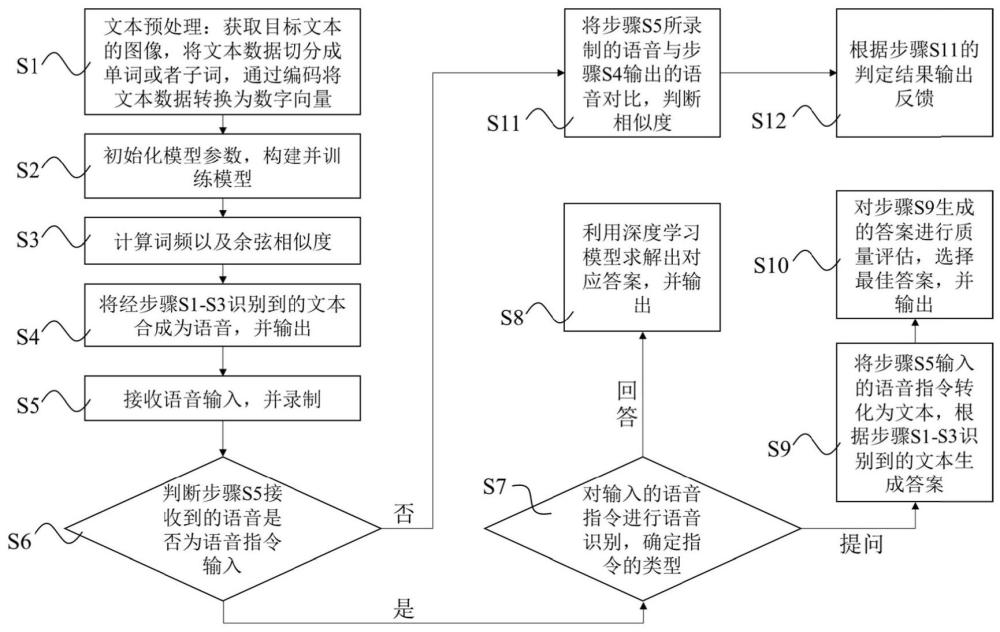
4、步骤s1、文本预处理:获取目标文本的图像,将文本数据切分成单词或者子词,通过编码将文本数据转换为数字向量;
5、步骤s2、初始化模型参数,构建并训练模型;
6、步骤s3、计算词频以及余弦相似度;
7、步骤s4、将经步骤s1-s3识别到的文本合成为语音,并输出,从而实现书籍阅读功能;
8、步骤s5、接收语音输入,并录制;
9、步骤s6、判断步骤s5接收到的语音是否为语音指令输入,若是,则执行步骤s7,否则执行步骤s11;
10、步骤s7、对输入的语音指令进行语音识别,确定指令的类型,若输入语音为回答类型,执行步骤s8,若输入语音为提问类型则执行步骤s9;
11、步骤s8、利用深度学习模型求解出对应答案,并输出;
12、步骤s9、将步骤s5输入的语音指令转化为文本,根据步骤s1-s3识别到的文本生成答案;
13、步骤s10、对步骤s9生成的答案进行质量评估,选择最佳答案,并输出;
14、步骤s11、将步骤s5所录制的语音与步骤s4输出的语音对比,判断相似度;
15、步骤s12、根据步骤s11的判定结果输出反馈。
16、进一步地,所述步骤s2还包括以下子步骤:
17、步骤s201、将经步骤s1预处理后的数据集划分为训练集、验证集和测试集三个子集,采用梯度累积的方式,分批次地对数据进行更新;
18、步骤s202、将预处理后的数据集输入到模型中进行训练,选择交叉熵损失函数来衡量所述预测概率与真实概率之间的差距;
19、步骤s203、模型训练:调整模型参数,直至找到最优的模型参数和超参数配置;
20、步骤s204、当模型训练完成后,将其应用于实际场景中,并对模型进行持续优化和更新。
21、进一步地,所述语音交互教学方法能够运用词袋模型处理,实现自主授课功能,具体通过以下步骤:
22、步骤a1、对文本进行预处理,将文本数据切分成单词或者子词,通过编码将文本数据转换为数字向量;
23、步骤a2、运用transformer深度学习模型对于数据集进行训练,能够从数据中理解文本的内容,并根据所述文本生成问题;
24、步骤a3、对输入的语音进行处理,包括分词、去除停用词、词干提取,得到词向量序列,将文本转化为计算机可以处理的格式;
25、步骤a4、将步骤a2所理解的内容与步骤a3接收到的输入信息进行相似度比对,运用词袋模型进行处理;
26、步骤a5、将步骤a4的比对结果进行语音输出。
27、进一步地,所述transformer深度学习模型包括:
28、输入嵌入层,将输入的离散化序列转换为连续的向量表示;
29、位置编码层,通过位置编码为序列中的每个位置添加信息;
30、自注意力机制层,允许模型在计算每个单词的表示时,将注意力权重分配给输入序列中的其他单词,以便更好地理解和处理文本;
31、残差连接与层归一化,在每个子层之后引入了残差连接,将输入的信号直接连接到输出,并对每个神经元的激活进行标准化,使其具有均值为0和方差为1的分布,达到对每个子层的输出进行归一化处理;
32、前馈神经网络层,在所述自注意力机制层之后,每个位置的表示会通过具有多层感知机结构的前馈神经网络进行映射和变换;
33、编码器,所述编码器通过逐步处理输入序列,逐渐构建出表示向量,从而将输入序列转换为表示向量;
34、解码器,从前一个时间步的输出反馈到当前时间步的输入,通过循环或者自注意力机制来捕捉上下文信息,基于所述编码器生成的表示向量和之前生成的部分输出序列生成目标序列。
35、进一步地,所述语音交互教学方法能够实现智能问答功能,具体通过以下步骤:
36、步骤b1、对输入的语音进行处理,包括分词、去除停用词、词干提取,得到词向量序列;
37、步骤b2、通过词频-逆文本频率指数加权方法,将步骤b1处理后的文本转换为计算机可以理解的向量或矩阵表示形式;
38、步骤b3、对输入的问题进行理解和分类,确定问题的类型和需要回答的内容;
39、步骤b4、应用序列到序列模型生成答案;
40、步骤b5、根据步骤b4生成的答案,使用bleu评估指标进行答案质量评估,并选择最佳答案;
41、步骤b6、将步骤b5生成的最佳答案格式化,语音输出。
42、进一步地,所述序列到序列模型由编码器和解码器组成,其中编码器将输入问题转化为一个固定长度的向量表示,解码器则将这个向量表示转化为对应的答案。
43、进一步地,所述语音交互教学方法能够实现发音练习功能,具体通过以下步骤:
44、步骤c1、使用大规模文本数据对模型进行预训练,学习词向量和句子表示;
45、步骤c2、在特定任务上进行微调;
46、步骤c3、句子级别重要性提取,使用注意力机制方法对编码后的句子向量进行加权处理;
47、步骤c4、词语级别重要性提取,使用bert或gpt模型对每个词语进行编码;
48、步骤c5、将文本数据转换为标准音频,并输出;
49、步骤c6、录制输入音频,将输入音频与步骤c5获得的标准音频进行相似度比对;
50、步骤c7、输出相似度比对结果。
51、进一步地,所述步骤c6中,利用神经网络比较两个音频的相似度采用以下子步骤:
52、步骤c61、收集具有标签的音频数据集;
53、步骤c62、对音频信号采样、量化、编码、滤波,提取出有用的音频特征;
54、步骤c63、使用卷积神经网络来提取音频的特征表示;
55、步骤c64、使用siamese网络来比较音频的相似度;
56、步骤c65、使用均方误差损失函数来度量网络输出和真实相似度标签之间的差异;
57、步骤c66、使用训练好的siamese网络模型来计算未知音频对的相似度;
58、步骤c67、根据相似度分数进行相似度评估,并根据具体需求设置合适的阈值,并判断两个音频是否足够相似。
59、其次,本发明还提供一种装置,该装置能够实现上述语音交互教学方法。所述装置包括若干模块:
60、图像采集模块,用于获取待识别图像;
61、文字识别模块,用于对图像进行文字识别,获得文字文本;
62、语音合成模块,用于将计算机自己产生的,或外部输入的文字信息转变为语音,并向环境发出声音;
63、语音识别模块,用于识别输入的语音,并将其转变为计算机能够识别的信息;
64、终端处理模块,用于将输入信息进行计算、匹配、预测,并提供对应的反馈。
65、再次,本发明还公开一种语音交互教学眼镜,包括镜框、与所述镜框铰接的镜腿,所述装置既可以设置在镜框中,也可以于镜腿内部设置,还可以同时设置在镜框与镜腿内。
66、本发明的有益效果是:
67、1.一方面,本发明提供了一种语音交互教学方法,能够实现自主授课、智能问答、口语练习等主动式教学功能,有利于提高儿童交互式学习的积极性和学习效果,并且对视障人士也同样适用;
68、2.另一方面,本发明还提供一种能够实现上述方法的装置,尤其是一种装配该装置的眼镜,儿童、学生或者视障人士佩戴后能够更加方便实现语音交互,交互感更强,在交互中获得教学。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22444.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。