一种基于深度学习的多功能语音交互装置
- 国知局
- 2024-06-21 11:36:54
本发明涉及语音交互领域,特别是涉及一种基于深度学习的多功能语音交互装置。
背景技术:
1、公园是城市绿地系统的重要组成部分,其在城市中的重要性日益凸显。随着5g、物联网、大数据等新一代信息技术的快速发展,公园的管理和服务需求呈现多元化发展的趋势,传统公园已经越来越难以满足新的需求,并暴露出诸多问题,公园“智慧化”已成为必然的发展趋势,在新一代信息通信技术的发展下,公园正在公园服务管理、市民智能交互等方面实现数字化表达。作为服务于市民的城市公园,以人为本,提高市民游园乐趣和参与感是智慧公园发展的基础和重中之重,而作为游园市民可以直接接触的智能交互产品,则完全符合智慧公园以人为本的核心理念。
2、针对智慧公园中市民智能交互场景,调研后,目前交互产品存在智能化不足、主控算力不够、用户交互较差等诸多不足。因此有必要发明一款搭载前沿科技的智能交互装置供给市民娱乐和科普。
技术实现思路
1、本发明的目的是提供一种基于深度学习的多功能语音交互装置,可提高语音交互的灵活性,使语音交互更贴近实际交流场景。
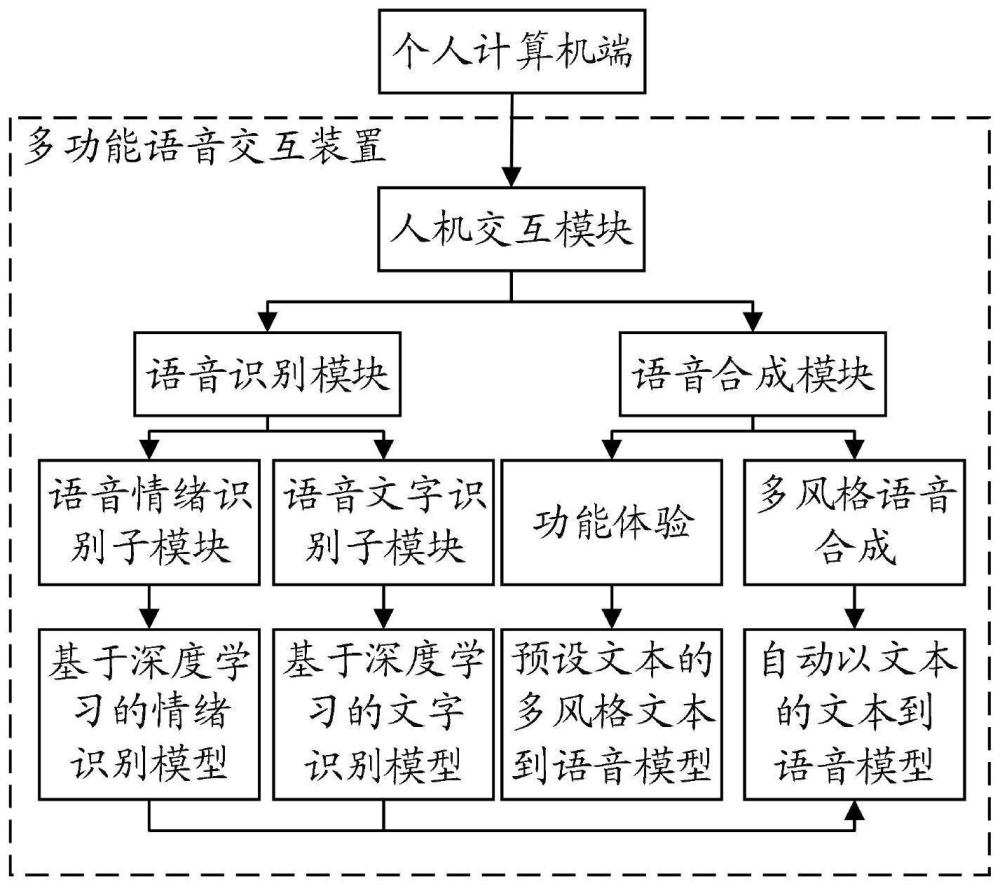
2、为实现上述目的,本发明提供了一种基于深度学习的多功能语音交互装置,包括:
3、人机交互模块,用于为用户提供人机交互界面,接收用户输入的语音及指令,并显示语音文本及情绪类别,播放多风格语音;
4、语音识别模块,与所述人机交互模块连接,用于基于深度学习模型,对用户输入的语音进行文字识别及情绪识别,得到语音文本及情绪类别;
5、语音合成模块,与所述人机交互模块连接,用于基于语音合成模型,根据用户输入的语音生成多风格语音。
6、可选地,所述人机交互模块、所述语音识别模块及所述语音合成模块均基于jetsonnano soc主控芯片构建。
7、可选地,所述人机交互模块包括hmi组态屏幕、麦克风及扬声器。
8、可选地,所述语音识别模块包括:
9、语音文字识别子模块,用于基于文字识别模型,对用户输入的语音进行文字识别;所述文字识别模型为预先在个人计算机端采用语音文字数据集对efficient conformer模型进行训练得到的;语音文字数据集中包括多个语音样本及各语音样本对应的文字;
10、语音情绪识别子模块,用于基于情绪识别模型,对用户输入的语音进行情绪识别,以确定所述用户的情绪类别;所述情绪识别模块为预先在个人计算机端采用语音情绪数据集对声纹识别模型进行训练得到的;所述语音情绪数据集中包括多个语音样本及各语音样本对应的情绪类别:所述声纹识别模型包括依次连接的第一全连接层、重塑层、双向lstm层、tanh激活层、丢弃层、第二全连接层、relu激活层及第三全连接层。
11、可选地,所述文字识别模型包括依次连接的cnn前端、多个lac编码器及多个lac解码器;
12、所述cnn前端包括依次连接的第一卷积神经网络、第二卷积神经网络及嵌入神经网络;
13、每个lac编码器包括依次连接的第一低秩前馈神经网络、第一多头注意力层、第三卷积神经网络及第二低秩前馈神经网络;
14、每个lac解码器包括依次连接的掩码多头注意力层、第一归一化层、第二多头注意力层、第二归一化层、第三低秩前馈神经网络及第三归一化层。
15、可选地,所述语音文字数据集为使用线性能量图对中文女音数据库aishell-1进行预处理,并采用ffmpeg工具进行增强噪声、增强语速、增强音量、偏移增强及频谱增强得到的。
16、可选地,所述语音合成模型为预先采用多说话人数据集对fastspeech2模型进行训练后,使用paddld工具转化为动态图模型得到的。
17、根据本发明提供的具体实施例,本发明公开了以下技术效果:本发明提供的基于深度学习的多功能语音交互装置融合了人机交互、语音识别及语音合成功能,提高了语音交互的灵活性,并且,将情绪识别加入语音识别中,可以根据语音同时识别出文字和情绪,使得语音交互更加贴近实际交流场景。
技术特征:1.一种基于深度学习的多功能语音交互装置,其特征在于,所述基于深度学习的多功能语音交互装置包括:
2.根据权利要求1所述的基于深度学习的多功能语音交互装置,其特征在于,所述人机交互模块、所述语音识别模块及所述语音合成模块均基于jetson nano soc主控芯片构建。
3.根据权利要求1所述的基于深度学习的多功能语音交互装置,其特征在于,所述人机交互模块包括hmi组态屏幕、麦克风及扬声器。
4.根据权利要求1所述的基于深度学习的多功能语音交互装置,其特征在于,所述语音识别模块包括:
5.根据权利要求4所述的基于深度学习的多功能语音交互装置,其特征在于,所述文字识别模型包括依次连接的cnn前端、多个lac编码器及多个lac解码器;
6.根据权利要求4所述的基于深度学习的多功能语音交互装置,其特征在于,所述语音文字数据集为使用线性能量图对中文女音数据库aishell-1进行预处理,并采用ffmpeg工具进行增强噪声、增强语速、增强音量、偏移增强及频谱增强得到的。
7.根据权利要求1所述的基于深度学习的多功能语音交互装置,其特征在于,所述语音合成模型为预先采用多说话人数据集对fastspeech2模型进行训练后,使用paddld工具转化为动态图模型得到的。
技术总结本发明提供了一种基于深度学习的多功能语音交互装置,属于语音交互领域,装置包括:人机交互模块,用于为用户提供人机交互界面,接收用户输入的语音及指令,并显示语音文本及情绪类别,播放多风格语音;语音识别模块,用于基于深度学习模型,对用户输入的语音进行文字识别及情绪识别,得到语音文本及情绪类别;语音合成模块,用于基于语音合成模型,根据用户输入的语音生成多风格语音。本发明提高了语音交互的灵活性,并将情绪识别加入语音识别中,可以根据语音同时识别出文字和情绪,使得语音交互更加贴近实际交流场景。技术研发人员:庞中华,商鹏飞,高胜男,翟维枫,于铧仁,郭海彬受保护的技术使用者:北方工业大学技术研发日:技术公布日:2024/3/17本文地址:https://www.jishuxx.com/zhuanli/20240618/22430.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。