一种自动语音识别方法和系统与流程
- 国知局
- 2024-06-21 11:38:39
本发明涉及语音识别,特别涉及一种自动语音识别方法和系统。
背景技术:
1、随着数据处理技术的进步以及移动互联网的快速普及,计算机技术被广泛地运用到了社会的各个领域,随之而来的则是海量数据的产生,其中,语音数据受到了人们越来越多的重视,通过自动语音识别技术使得这些语音数据得以更好地利用。自动语音识别(automatic speech recognition,asr),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列等。
2、如今主流的自动语音识别方法大都采用隐马尔科夫模型(hmm)作为声学模型,这是因为hmm模型的状态跳转模型很适合人类语音的短时平稳特性,可以对不断产生的观测值(语音信号)进行方便的统计建模。然而,现有的基于hmm模型的自动语音系统通常需要大量的语言资源,且需要经过多次解码过程,这便极易导致信息丢失,使得识别错误率较高。
3、此外,现有的自动语音识别系统除了包括声学模型外,还包括词汇模型、语言模型等,系统组件庞大,且组件相互之间有着较强的依赖关系,这便导致单个组件的错误会被积累,从而使得最终的输出结果的准确性较差。另外,现有的自动语音识别系统需要手动设计优化,适应能力较差;同时,每个组件还需单独进行训练和推理,消耗了大量的时间和计算资源,限制了自动语音识别系统的性能和效率。
技术实现思路
1、本发明的目的在于提供一种自动语音识别方法和系统,以至少解决现有自动语音识别系统错误率较高的问题。
2、为解决上述技术问题,本发明提供一种自动语音识别方法,包括:
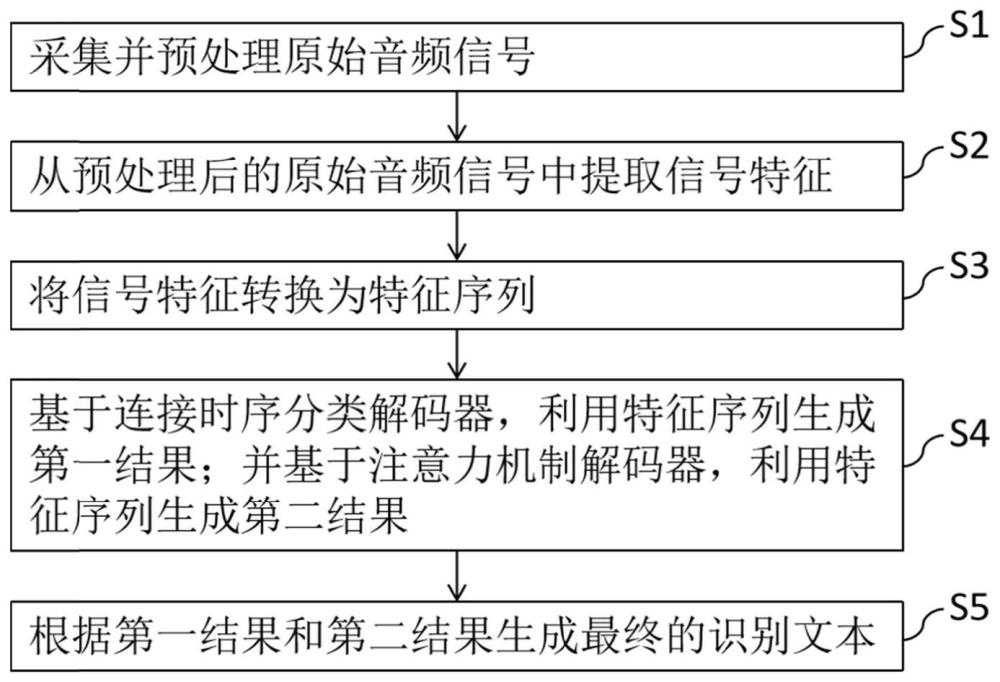
3、采集并预处理原始音频信号;
4、从预处理后的原始音频信号中提取信号特征;
5、将信号特征转换为特征序列;
6、基于连接时序分类解码器,利用特征序列生成第一结果;并基于注意力机制解码器,利用特征序列生成第二结果;
7、根据第一结果和第二结果生成最终的识别文本。
8、可选的,在所述的自动语音识别方法中,所述采集并预处理原始音频信号的方法包括:
9、采集原始音频信号,并将原始音频信号转换为离散的音频数字信号;
10、以预设周期对原始音频信号的幅度进行读取,并将读取的幅度值设为音频数字信号的幅度;
11、对音频数字信号进行滤波处理,以去除噪声;
12、对滤波后的音频数字信号进行归一化处理,以将音频数字信号的幅度缩放在[-1,1]的范围内。
13、可选的,在所述的自动语音识别方法中,所述从预处理后的原始音频信号中提取信号特征的方法包括:
14、对音频数字信号进行预加重,其中,预加重采用的公式为:
15、y(n)=x(n)-αx(n-1)
16、其中,y(n)表示预加重后的音频数字信号,x(n)表示输入的音频数字信号,α表示预加重系数;
17、对预加重后的音频数字信号进行分帧,其中,分帧采用的公式为:
18、hi(n)=w(n)×y((i-1)×a+n)
19、1≤n≤fl
20、1≤i≤j
21、其中,hi(n)表示第i帧音频帧信号,w(n)表示加窗函数,a表示帧移长度,n表示帧长,fl表示总帧长,j表示分帧处理后的总帧数;
22、利用快速傅里叶变换,将音频帧信号转换为频域信号,以得到音频帧信号对应的频谱图;
23、利用梅尔滤波器,从频域信号中获得信号特征。
24、可选的,在所述的自动语音识别方法中,所述加窗函数w(n)采用汉明窗;fl取20ms,a取10ms。
25、可选的,在所述的自动语音识别方法中,所述利用梅尔滤波器,从频域信号中获得信号特征的方法包括:
26、将频谱图分成若干个等宽的频率带,每一频率带采用一个梅尔滤波器进行加权,其中,梅尔滤波器的公式为:
27、
28、其中,hm(k)表示第m个梅尔滤波器在频率k处的响应,k表示频率序号,f(m)表示第m个梅尔滤波器的中心频率,m表示梅尔滤波器的总数,fs表示采样频率;
29、对每个梅尔滤波器的能力值取对数,其中,取对数采用的公式为:
30、
31、其中,s(m)表示第m个梅尔滤波器的能力值的对数值,xi(k)表示第i帧的频谱图,n表示音频帧信号的序列长度;1≤m≤m;
32、对对数值进行离散余弦变换,以得到一组梅尔频率倒谱系数,其中,离散余弦变换采用的公式为:
33、
34、其中,c(u)表示第u个梅尔频率倒谱系数,u=1,2,…,l,l表示梅尔频率倒谱系数的总数;
35、从一组梅尔频率倒谱系数中按预设方式提取若干个梅尔频率倒谱系数,以作为信号特征。
36、可选的,在所述的自动语音识别方法中,所述将信号特征转换为特征序列的方法包括:
37、构建共享编码器网络,所述共享编码器网络包括卷积神经网络和blstm网络;
38、利用卷积神经网络,从信号特征中提取高级特征;
39、利用blstm网络,从信号特征中捕获时间依赖性;
40、根据信号特征的时间依赖性,利用高级特征生成特征序列。
41、可选的,在所述的自动语音识别方法中,所述卷积神经网络包括6层卷积层和3层最大池化层;每2层卷积层后连接1层最大池化层;每层卷积层的卷积核为3×3;所述blstm网络包括两层blstm层;每层blstm层具有1024个神经元。
42、可选的,在所述的自动语音识别方法中,所述基于连接时序分类解码器,利用特征序列生成第一结果的方法包括:
43、构建连接时序分类解码器,所述连接时序分类解码器包括顺次连接的blstm层、全连接层和ctc解码器;
44、利用blstm层对特征序列进行双向递归神经网络处理,以提取序列中的时序信息,其中,blstm层的输出表示为:
45、h={h1,h2,…,ht}
46、ht=[fθ(xt);bθ(xt)]
47、x={x1,x2,…,xt}
48、其中,h表示blstm层的输出序列,x表示特征序列,t表示序列长度;ht表示时刻t的特征向量,包含该时刻的上下文信息;xt∈x,fθ和bθ分别表示blstm层的正向网络和反向网络,θ表示网络参数;
49、利用全连接层将blstm层的输出序列映射到ctc解码器中,其中,全连接层的输出表示为:
50、y={y1,y2,…,yt}
51、yt=whht+bh
52、其中,y表示全连接层的输出序列;wh和bh分别为全连接层的权重和偏置;
53、利用ctc解码器采用前向-后向算法将全连接层的输出序列进行解码,以得到第一结果,其中,ctc解码器的损失函数表示为:
54、
55、c={c1,c2,…,ct}
56、其中,c表示对全连接层的输出序列y进行对齐操作后取得的输出序列;b-1(y)表示输出序列y进行反转和去重后得到的序列集合。
57、可选的,在所述的自动语音识别方法中,所述基于注意力机制解码器,利用特征序列生成第二结果的方法包括:
58、构建注意力机制解码器,所述注意力机制解码器包括顺次连接的两层blstm层、全连接层和softmax层;
59、利用两层blstm层对特征序列进行双向递归神经网络处理,以提取序列中的时序信息,得到一组高级语义特征向量,其中,两层blstm层的输出表示为:
60、
61、
62、
63、其中,和分别表示第t帧向前和向后的lstm输出;ht表示第t帧时的高级语义特征向量,其通过将和拼接得到;
64、利用全连接层和softmax层对当前帧的高级语义特征向量和前一帧的注意力机制解码器的输出进行计算,以得到第二结果,其中,计算采用的公式为:
65、st=softmax(ws[dt;st-1])
66、
67、
68、其中,st表示第t帧注意力机制解码器的输出,ws表示softmax层的学习参数;dt表示当前帧的高级语义特征向量和前一帧的注意力机制解码器的输出进行对齐后得到的特征向量;βt,i表示注意力机制的权重;score表示用于计算对齐得分的函数。
69、为解决上述技术问题,本发明还提供一种自动语音识别系统,用于实现如上任一项所述的自动语音识别方法,所述自动语音识别系统包括:
70、音频输入模块,用于采集并预处理原始音频信号;
71、特征提取模块,用于从预处理后的原始音频信号中提取信号特征;
72、共享编码器网络,用于将所述信号特征转换为特征序列;
73、联合解码器网络,包括连接时序分类解码器和注意力机制解码器;所述连接时序分类解码器用于利用所述特征序列生成第一结果并输出;所述注意力机制解码器用于利用所述特征序列生成第二结果并输出;
74、文本输出模块,用于根据所述第一结果和所述第二结果生成最终的识别文本并输出。
75、本发明提供的自动语音识别方法和系统,包括:采集并预处理原始音频信号;从预处理后的原始音频信号中提取信号特征;将信号特征转换为特征序列;基于连接时序分类解码器,利用特征序列生成第一结果;并基于注意力机制解码器,利用特征序列生成第二结果;根据第一结果和第二结果生成最终的识别文本。通过连接时序分类解码器和注意力机制解码器,将声学模型、词汇模型和语言模型替换为单个神经网络,直接将语音映射到文本输出,省去了多个组件的优化和集成,从而避免了错误的累积,使得自动语音识别系统具有更高的准确性、更快的训练推理速度和更好的适应性,且更容易实现和部署,进而有效提高自动语音识别系统的性能和效率,解决了现有自动语音识别系统错误率较高的问题。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22637.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表