用于去除不期望的听觉粗糙度的装置和方法与流程
- 国知局
- 2024-06-21 11:38:53
本发明涉及一种用于去除不期望的听觉粗糙度的装置和方法。
背景技术:
1、在非常低的比特率下的感知音频编解码中,有时会在包含清晰音调分量的音频信号中引入调制伪音。这些调制伪音通常被感知为听觉粗糙度(auditory roughness)。这可以是由于量化误差或由于音频带宽扩展造成的,其中音频带宽扩展导致复制频谱带的边缘处的不规则谐波结构。特别地,在对音调分量进行编码时不投入相当多的比特的情况下,难以克服由于量化误差而引起的粗糙度伪音。
2、在低比特率音频编解码中,使用音频信号的高效表示,与原始的、未压缩的16比特采样pcm音频信号相比,音频信号的高效表示需要少得多的数字信息。对于现代变换编码器(如xhe-aac和mpeg-h),通过使用mdct将原始输入音频信号变换为时频域表示来部分地获得效率,其中,每个音频帧可以用由心理声学模型监督并受到可用比特预算约束的可变精度来表示。通过在编码过程期间应用这两种控制机制,结果将是其中量化噪声跨时间帧和频谱带变化的音频比特流。
3、在理想情况下,在编码器侧,量化噪声被整形为使得由于听觉掩蔽而导致其变得听不见。然而,对于非常低的比特率,量化噪声将在某个时间点变得可听见,特别是如果音频信号中存在具有长持续时间的音调分量。原因是:对这些音调分量进行量化可能引起跨音频帧的幅度变化,这可以导致可听见的幅度调制。对于43hz的典型变换编码器音频帧速率,这些调制将以该速率的最多一半的速率被添加到信号中。这低于引起粗糙度感知但在引起(慢)r-粗糙度的范围内的调制速率。此外,由于用于将时域音频帧变换到频域的短期加窗,完美的、固定的音调分量将在一系列相邻频率区间内表示,其中,该一系列相邻频率区间中的一些很容易被量化为零,尤其是在非常低的比特率下。
4、通过附加的半参数化技术(如与xhe-aac一起使用的频谱带复制(sbr)[1]、或与mpeg-h一起使用的智能间隙填充(igf)[2]),可以将比特率降低到对于纯变换编码器的良好音频质量所需的范围以下。使用低频频谱的移位副本和频谱包络整形来重建高频分量。分别利用sbr或igf,可以保持良好的音频质量。
5、然而,由于音调频率分量与已经存在的时间调制一起被复制,因此sbr和igf可能会放大粗糙度伪音。
6、此外,这些技术可能会引入新的粗糙度伪音,特别是在复制频谱带之间的过渡区域中:在许多音频帧中,原始信号中存在的规则谐波网格可能存在偏差。最近的研究表明,使用心理声学模型来自适应地决定最佳复制映射可以提高音频质量[5]。
7、用于抑制音调信号中的噪声的后滤波方法部分地去除信号中的粗糙度。所述方法依赖于基频的测量并通过应用调谐到基频的梳状滤波器来去除噪声,或者依赖于预测编解码,例如长期预测器(ltp)。所有这些方法仅适用于单音高信号,并且无法对展现出许多音高的复调或非谐波内容进行降噪。此外,该方法无法区分存在于原始信号中的噪声或由于编码-解码过程而引入的噪声。
8、因此,非常期望能够提供用于听觉粗糙度去除的改进构思。
技术实现思路
1、本发明的目的在于提供用于听觉粗糙度去除的改进构思。通过根据权利要求1的装置、通过根据权利要求27的音频编码器、通过根据权利要求38的方法、通过根据权利要求39的方法、以及通过根据权利要求40的计算机程序来实现本发明的目的。
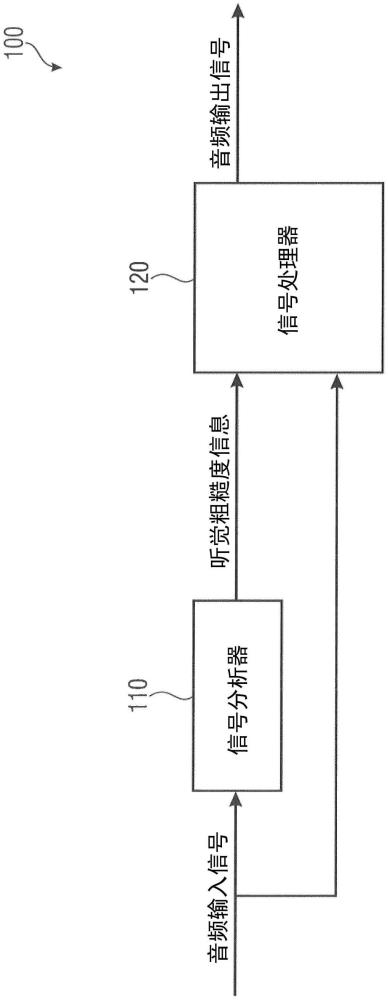
2、一种根据实施例的用于处理音频输入信号以获得音频输出信号的装置。该装置包括信号分析器,其被配置用于确定关于音频输入信号的一个或多个频谱带的听觉粗糙度的信息。此外,该装置包括信号处理器,其被配置用于根据关于一个或多个频谱带的听觉粗糙度的信息来处理音频输入信号。
3、此外,一种根据实施例的用于对初始音频信号进行编码以获得编码音频信号和辅助信息的音频编码器。该音频编码器包括用于对初始音频信号进行编码以获得编码音频信号的编码模块。此外,该音频编码器包括辅助信息生成器,其用于根据初始音频信号并进一步根据编码音频信号来生成并输出辅助信息。辅助信息包括指示,该指示对多个频谱带中的一个或多个频谱带进行指示,其中针对该一个或多个频谱带将在解码器侧确定关于听觉粗糙度的信息。
4、此外,提供了一种根据实施例的用于处理音频输入信号以获得音频输出信号的方法。该方法包括:
5、-确定关于音频输入信号的一个或多个频谱带的听觉粗糙度的信息;以及
6、-根据关于一个或多个频谱带的听觉粗糙度的信息来处理音频输入信号。
7、此外,一种用于对初始音频信号进行编码以获得编码音频信号和辅助信息的方法。该方法包括:
8、-对初始音频信号进行编码以获得编码音频信号;以及
9、-根据初始音频信号并进一步根据编码音频信号来生成并输出辅助信息。
10、辅助信息包括指示,该指示对多个频谱带中的一个或多个频谱带进行指示,其中针对该一个或多个频谱带将在解码器侧确定关于听觉粗糙度的信息。
11、此外,提供了计算机程序,其中每个计算机程序被配置为当在计算机或信号处理器上执行时实现上述方法之一。
12、除此之外,本发明还基于如下发现:特别是在对音调分量进行编码时不投入相当多的比特的情况下,难以缓解由于量化误差而引起的粗糙度伪音。实施例提供了新颖且具有创造性的概念来去除在解码器侧的由编码器发送的少量引导信息所控制的这些粗糙度伪音。
13、一些实施例基于如下发现:在逐帧的基础上,很难看到跨连续帧发生的幅度调制,人类听觉系统仍然将它们感知为粗糙度伪音,因为它跨比音频编解码中使用的典型帧长度长的时间跨度来评估音频信号。在一些实施例中,可以例如利用更长的帧长度来分析解码音频信号,使得音调分量中存在的幅度调制伪音在幅度频谱中作为在主音调分量旁边出现的侧频谱带或者甚至侧峰值而变得更加可见。
14、考虑到这种侧峰值的出现,原则上将可以检测这些侧峰值并将它们从频谱中去除。初始实验已经表明,这确实是可以完成的,并且作为结果,极大地减少了粗糙度伪音。
15、然而,盲目地去除这种侧峰值可能导致对音频信号引入不期望的可听变化。例如,考虑包括本身非常粗糙的信号部分的原始音频信号。在这种情况下,不应去除粗糙度。确实发现,盲目应用侧峰值去除确实会导致音频信号部分中出现清晰可听见的“管状”伪音,这些伪音具有非常类似噪声或密集填充的频谱。
16、为了克服上述问题,似乎需要选择性地进行侧峰值去除,即仅在音频信号的其中编码和解码过程导致粗糙度伪音的那些部分中进行侧峰值去除。由于该决策与这种伪音的感知相关,因此这种决策可以由心理声学模型驱动,该心理声学模型将原始信号和解码信号进行比较以确定在哪些时频区域中引入了粗糙度伪音。
17、为了去除上述粗糙度伪音,提供了一种使用对幅度调制敏感的心理声学模型的方法。该模型基于dau等人的[3]模型,但包括已经在[4]中描述并稍后将详细介绍的多个修改。心理声学模型做出的关于是否应去除粗糙度伪音的决策可能例如需要访问原始信号,并且因此需要在音频编码/解码链的编码器侧完成。这意味着辅助信息需要从编码器发送给解码器。尽管这将增加比特率,但事实证明增量非常小,并且可以很容易地从变换编码器的比特预算中获取。
18、实施例去除了解码器处的由比特流中从编码器发送的少量引导信息所控制的粗糙度伪影。
19、实施例提供了用于去除听觉粗糙度的构思。
20、一些实施例基于音调分量的调制创建与主音调相邻的频谱侧峰值的概念来减少或去除解码器侧的粗糙度伪音。例如,当频谱分析基于长时间窗口时,可以更好地观察到这些侧峰值。在一些特定实施例中,分析窗口可以例如被延伸超过典型编码帧的长度。
21、原则上,可以从频谱中去除频谱侧峰值,并且以这种方式,也将去除粗糙度伪音。算法可以例如基于与更强的主音调分量的频谱接近度来选择需要去除的侧峰值。当盲目地将这种粗糙度去除应用于音频信号时,它也将去除原始音频信号中存在的粗糙度。
22、在实施例中,心理声学模型分析低比特率编解码器在什么频谱时间间隔中引入粗糙度。然后在比特流的辅助部分中用信号通知应从其去除粗糙度的频谱时间间隔,并且将其发送给解码器。
23、根据实施例,由比特流馈送的解码器的后处理器可以例如包括用于控制粗糙度去除的少量引导信息。
24、在另一实施例中,可以例如在解码器侧估计引导信息。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22660.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表