用于检测和去除瞬态噪声的方法、音频设备和存储介质与流程
- 国知局
- 2024-06-21 11:39:51
本公开涉及一种用于对音频信号进行去噪的方法,具体涉及用于对包含语音的音频信号进行去噪的方法。
背景技术:
1、当使用现有的去噪算法对音频信号进行去噪(即,从音频信号中去除噪声)时,由于其不可预测性,瞬态噪声事件通常难以捕获,而这种算法通常对非瞬态噪声语音进行去噪是有效的。现代机器学习系统,如神经网络,通常需要给定的时间上下文窗口,根据限定,这不适用于突然和/或脉冲噪声事件。因此,瞬态噪声事件不会被捕获和过滤掉。此外,由于它们的频谱的相似性,一些已知的去噪算法往往会将语音与其他类似语音的信号混淆,这可以被认为是瞬态噪声事件,如打哈欠、咳嗽等。
2、除此之外,现有的去噪算法通常被训练成在特定的环境中工作,例如地铁、餐馆、办公室等,这意味着它们被优化为使用来自这些特定环境的声音集来工作。然而,每当出现脱离上下文的事件时,如婴儿在办公室哭泣,狗在酒吧吠叫等,他们往往会表现出较弱的性能。
3、作为这些问题的部分解决方案,可以引入延迟,给去噪算法额外的时间,以更好地处理含噪声的语音,并提高对瞬态噪声的性能。然而,在对话中引入延迟会改变双方实时对话的自然流程,从而影响对话质量。
技术实现思路
1、根据本公开,通过所公开的方法、音频设备和计算机可读存储介质来解决上述和其他问题,所公开的方法、音频设备和计算机可读存储介质提供了更具体的方法,该方法被优化为使用短时间上下文窗口工作,是上下文遮蔽(context-blind)的,并且因此更适合于解决对音频信号进行去噪中的瞬态噪声事件的问题。
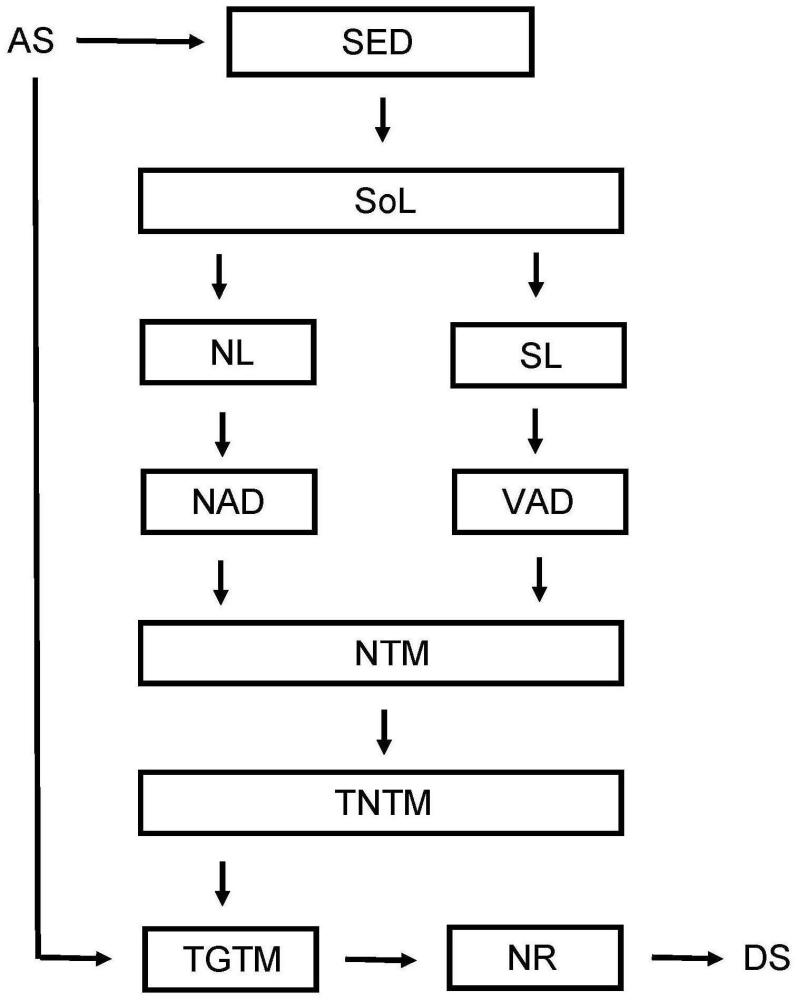
2、公开了一种用于检测和去除音频信号,具体是包含语音的音频信号中的瞬态噪声的方法。该方法包括以下步骤:
3、-使用sed(声音事件检测)模块确定与音频信号相关联的多个声音标签,其中,sed模块包括被配置为将音频信号划分为多个sed时间窗口的机器学习模型,
4、-确定与多个sed时间窗口中的每个sed时间窗口相关联的一个或多个声音标签,对于所述sed时间窗口相关的,其中,一个或多个声音标签选自预限定的一组声音标签,
5、-基于多个确定的声音标签,检测音频信号中的瞬态噪声,以及
6、-基于检测到的瞬态噪声,从音频信号中去除瞬态噪声,以生成去噪信号。
7、瞬态噪声会显著影响音频信号的质量,在严重的情况下,如果音频信号包含语音,则很难甚至不可能理解所说的内容。
8、瞬态噪声可以限定为在时间上随机发生并具有时变未知脉冲响应的声音事件。因此,瞬态噪声的特征不容易估计,因为发生的时间和脉冲响应都是不可预测的。幸运的是,检测瞬态噪声事件相对容易,因为它通常是持续时间短、幅度大的快速变化信号。
9、要去噪的音频信号可以是声音序列的任何电子表示,具体是包含语音的声音序列。音频信号可以通过多种方式获得。音频信号可以从远端站接收,例如音频设备或服务器设备。音频信号可以通过从音频设备上的本地存储器检索输入音频信号来获得,该本地存储器可以是该音频设备的存储器。音频信号可以是远端设备和近端设备之间的在线会议的一部分。音频信号可以是存储在音频设备上的测试信号。音频信号可以由记录输入麦克风信号的音频设备的一个或多个麦克风获得。输入麦克风信号可以是表示歌曲、电影音频或音频书的信号形式的媒体信号。输入麦克风信号可以是在电话呼叫或两方或多方之间的另一通信会话期间记录的语音信号。输入麦克风信号可以是实时获得的信号,例如,输入麦克风信号是正在进行的在线会议的一部分。输入麦克风信号可以是输入麦克风信号的较大数据集的一部分。音频信号可以是时域信号或频域信号。输入音频信号可以经由音频设备的处理器获得。因此,音频信号可以是各种不同的格式,例如频谱图、梅尔频率(mel-frequency)图、原始音频、γ音(gammatone)、梅尔频率倒谱系数(mfcc)等。
10、通常,自动声音事件检测的目的是识别音频信号中出现的不同类型声音的类型和定时。在音频信号中检测到的每个声音事件由某种时间指示和检测到的声音类型的某种规范来表示。在本发明中,时间指示由sed时间窗口限定,在sed时间窗口中检测声音事件,并且使用多个声音标签来指定声音类型,下面给出其示例。这些声音标签可以表示音频信号中需要的声音,通常是不同形式的语音,或者它们可以表示声音,其特征为噪声,并且应该优选地从音频信号中去除,以改善音频信号的质量,使所说的内容更清楚,等等。
11、例如,本发明的sed模块可以用深度卷积神经网络来实现,深度卷积神经网络例如由六个卷积块的堆栈组成,随后是用于声音事件分类的全局池化层、线性层和最终线性层。每个卷积块可以由具有可变数量的输入/输出和批量归一化的两个2d卷积层组成,并且平均池化被应用于单个卷积块。
12、首先在声音事件分类数据集上进行了训练,这种网络已经被证明能够有效地从输入对数梅尔(log-mel)频率图中提取隐藏特征。声音事件分类数据集可以包括来自youtube的具有累积持续时间为数千小时的、包括兆兆字节的数据的数百万个剪辑,并限定数百个不同的声音事件类别。这种数据集的示例是名为音频集的数据集。像音频集这样的数据集会随着时间的推移而不断发展,并且在任何时候都可能比几个月前大得多。
13、像任何其他算法一样,sed算法需要时间上下文窗口。然而,sed算法(使用神经网络实现)通常被训练成处理瞬态或短事件,而不是像大多数去噪算法那样处理长和均匀的背景噪声。因此,与现有的一般去噪算法不同,现有的一般去噪算法通常没有针对瞬态噪声事件进行优化,sed算法的目标是更多地针对音频信号的提示部分工作。
14、sed时间窗口的长度可以在1/10毫秒和几毫秒之间的范围内。
15、在实践中,sed模块可以为每个sed时间窗口计算多个概率,这些概率与不同的声音标签相关联。被确定为与该特定sed时间窗口相关联的声音标签可以是具有高于某个预限定阈值(例如5%、10%或15%)的概率的声音标签,或者可以是具有最高概率的声音标签(例如一个、两个或三个声音标签)。还可以使用这两种方法的组合来确定哪些声音标签应该与给定的sed时间窗口相关联。
16、在检测到音频信号中存在瞬态噪声后(即,被表征为噪声的短持续时间声音的表示),该方法从音频信号中去除这些表示或至少显著地减少它们。这尽可能在不影响希望保持在音频信号中的声音(通常是语音)的表示的情况下完成。这产生可以由包括扬声器的音频设备输出的去噪音频信号。
17、在一些实施方式中,预限定的一组声音标签包括一组噪声标签和一组语音标签。
18、除了区分不同类型的语音(男性语音、女性语音、儿童语音等),sed神经网络可以被训练来识别许多类型的瞬态噪声事件和脱离上下文的事件,例如铃声或蜂鸣器声、打喷嚏、咳嗽、婴儿哭闹、狗叫、牛哞哞叫、正在播放的弦乐或其他类型的音乐、汽车经过等。
19、在一些实施方式中,检测音频信号中的瞬态噪声的步骤包括以下步骤:
20、-如果一个或多个噪声标签已经与特定的sed时间窗口相关联,则通过为每个sed时间窗口注册来检测噪声活动。
21、在一些实施方式中,检测音频信号中的瞬态噪声的步骤包括以下步骤:
22、-如果一个或多个语音标签已经与特定的sed时间窗口相关联,则通过为每个sed时间窗口注册来检测语音活动。
23、在一些实施方式中,检测音频信号中的瞬态噪声的步骤包括以下步骤:
24、-通过为每个sed时间窗口注册是否应该设置噪声标记来生成噪声时间图,如果一个或多个噪声标签与特定sed时间窗口相关联并且没有语音标签与特定sed时间窗口相关联,则设置噪声标记。
25、为了不从音频信号中去除任何语音,在噪声时间图中只标记当音频信号中没有语音时出现的噪声。
26、在一些实施方式中,检测音频信号中的瞬态噪声的步骤包括以下步骤:
27、-使用正整数形式的预限定最大阈值从噪声时间图生成瞬态噪声时间图,其中,如果组成特定时间间隔的连续sed时间窗口的数量不超过最大阈值,则在由一个或多个连续sed时间窗口组成的噪声时间图中的时间间隔被标记为瞬态噪声,为时间窗口设置了噪声标记。
28、使用组成瞬态噪声事件的sed时间窗口的最大数量的阈值,确保只有短到足以被认为是“瞬态”的噪声事件在瞬态噪声时间图中被标记为“瞬态”。
29、可以程序性地生成噪声时间图,例如,每次标记sed时间窗口时,可以将sed时间窗口附加到噪声时间图上,这可以连续地执行。因此,对于每个新的标记sed时间窗口,连续更新噪声时间图。可替代地,噪声时间图可以是长度有限的缓冲器,例如,噪声时间图可以是长度为n个sed时间窗口的缓冲器,其中,n是最大阈值,然后每次附加sed时间窗口时,可以刷新缓冲器中最旧的当前标记。
30、在一些实施方式中,最大阈值小于100,例如小于20,例如10。
31、最大阈值的最佳值取决于几个因素,如信号采样率和相关联的傅立叶参数。这些傅立叶参数通常将根据输入音频信号的质量来设置。
32、在一些实施方式中,只有在噪声时间图中,连续组成特定时间间隔的连续sed时间窗口的数量等于或超过最小阈值的时间间隔才被标记为瞬态噪声,最小阈值是不超过最大阈值的正整数。
33、使用组成瞬态噪声事件的sed时间窗口的最小数量的阈值,降低了不是由实际瞬态噪声事件引起的瞬态噪声抑制的随机激活的风险。
34、在一些实施方式中,最小阈值为2或大于2,例如大于5,例如10。
35、与最大阈值一样,最小阈值的最佳值取决于几个因素,如信号采样率和相关联的傅立叶参数,并且应该在实现该方法的每个特定音频设备上单独设置。
36、在一些实施方式中,该方法包括以下步骤:
37、-生成瞬态增益时间图,其中,如果在瞬态噪声时间图中时间间隔被标记为瞬态噪声,则在瞬态增益时间图中抑制特定时间间隔,以及
38、-在将音频信号馈送到nr模块以生成去噪信号之前,通过将瞬态增益图应用于音频信号来从音频信号中去除瞬态噪声。
39、在将音频信号馈送到nr模块之前,在音频信号上应用基于瞬态噪声时间图的瞬态增益时间图有助于nr模块的功能。以这种方式,在音频信号被馈送到nr模块之前,从音频信号中去除了瞬态噪声的很大一部分。这意味着,与瞬态噪声仍然存在于音频信号中的情况相比,nr模块将更容易对该音频信号进行去噪。
40、在一些实施方式中,该方法包括以下步骤:
41、-使用nr(降噪)模块从音频信号中去除瞬态噪声,其中,基于检测到的瞬态噪声适配nr模块的一个或多个参数。
42、sed神经网络的短“反应时间”使其非常适用于辅助众所周知的去噪算法(在nr模块中实现)针对瞬态噪声事件。快速反应sed神经网络的另一个用途可以是暂时静音或降低麦克风的增益,以便消除或减少短暂的脱离上下文的噪声事件,这可能是令人不安的,并且可能被认为是不专业的,尤其是在官方会议等中。
43、在一些实施方式中,nr模块被配置为将音频信号划分为多个nr时间窗口,并且基于检测到的瞬态噪声,对于这些nr时间窗口中的每个nr时间窗口,从落在该特定nr时间窗口内的音频信号的部分中去除瞬态噪声。
44、nr模块从音频信号中去除瞬态噪声的能力可以借助于如下所述的sed模块而显著增加。
45、在一些实施方式中,该方法包括以下步骤:
46、-基于对应于与该特定nr时间窗口相关联的一个或多个sed时间窗口的噪声标签,为每个nr时间窗口适配用于nr模块的一个或多个参数。
47、如果nr时间窗口的长度不对应于sed时间窗口的长度,则可以通过平均或以其他方式加权对应于该特定nr时间窗口的sed时间窗口的值来获得用于使nr模块的参数适应给定nr时间窗口的值。
48、在一些实施方式中,sed时间窗口的长度短于或等于nr时间窗口的长度。
49、sed时间窗口可以设置为比nr时间窗口更小的长度,以更好地针对较短的瞬态声音事件。事实上,这是将sed模块与nr模块一起使用的重要原因,nr模块的去噪算法通常需要相对长的时间窗口来获得足够的上下文以能够正常工作。
50、在一些实施方式中,用于nr模块的参数包括用于选择nr模块中使用的权重子集的标志。
51、例如,如果检测到某种类型的瞬态噪声,参数中的相应标志将确保在nr模块内激活网络权重的适当子集,使其能够更好地适应给定类型的瞬态噪声。
52、在一些实施方式中,用于nr模块的参数包括傅立叶参数,例如时间窗口长度、跳变长度、重叠长度和/或窗口类型。
53、还公开了一种音频设备,例如一组耳机、扬声电话耳塞或助听器。音频设备包括:
54、-至少一个输入单元,被配置为接收声音信号,
55、-至少一个输出单元,被配置为发送声音信号,
56、-至少一个处理器,耦接至至少一个输入单元和至少一个输出单元,以及
57、-存储器,存储至少一个程序。
58、至少一个程序包括用于使至少一个处理器执行上述方法的指令。
59、上述方法可以应用于用于对音频信号,具体是包含语音的音频信号进行去噪的任何音频设备中。
60、音频设备可以被配置为由用户佩戴在用户的耳朵内、耳朵上、耳朵上方和/或耳朵处。用户可以佩戴两个音频设备,每个耳朵一个音频设备。这两个音频设备可以连接,例如无线连接和/或通过线连接,例如双耳助听器系统。
61、音频设备可以是可听的,例如头戴式耳机、头戴式受话器、耳机、耳塞、助听器、个人声音放大产品(psap)、非处方(otc)音频设备、听力保护设备、通用音频设备、定制音频设备或另一种头戴式音频设备。音频设备可以是扬声电话或音箱。音频设备可以包括处方设备和非处方设备。音频设备可以是智能设备,例如智能手机。
62、音频设备可以体现为各种壳体样式或形状因素中。这些形状因素中的一些是耳塞、入耳式耳机或耳挂式耳机。本领域技术人员知道不同种类的音频设备以及用于将音频设备布置在音频设备佩戴者的耳朵内、耳朵上、耳朵上方和/或耳朵处的不同选项。音频设备(或一对音频设备)可以是定制安装、标准安装、开放式安装和/或闭塞式安装。
63、音频设备的输入单元可以是一个或多个输入换能器。一个或多个输入换能器可以包括一个或多个麦克风。一个或多个输入换能器可以包括被配置用于检测骨骼振动的一个或多个振动传感器。一个或多个输入换能器可以被配置用于将声信号转换成电输入信号。该电输入信号可以是模拟输入信号或数字输入信号。一个或多个输入换能器可以耦接至一个或多个模数转换器,该模数转换器被配置用于将模拟输入信号转换成数字输入信号。
64、音频设备可以包括一个或多个无线通信单元。一个或多个无线通信单元可以包括一个或多个无线接收器、一个或多个无线发射器、一个或多个发射器—接收器对和/或一个或多个收发器。一个或多个无线通信单元中的至少一个无线通信单元可以耦接至一个或多个天线。无线通信单元可以被配置用于将由一个或多个天线中的至少一个天线接收的无线信号转换成电输入信号。音频设备可以被配置用于有线/无线音频通信,例如,使用户能够收听媒体,例如音乐或广播和/或使用户能够进行电话呼叫。音频设备可以被配置用于与一个或多个电子设备进行无线通信,例如另一音频设备、智能手机、平板电脑、计算机和/或智能手表。音频设备可以包括用于经由连接器例如通过使用电缆进行有线通信的连接器,例如与一个或多个麦克风进行有线通信。
65、音频设备的处理器可以被配置用于处理一个或多个电输入信号。该处理可以包括补偿用户的听力损失,即,根据用户的频率相关听力损伤对输入信号应用频率相关增益。该处理可以包括执行反馈消除、回声消除、波束成形、耳鸣减少/掩蔽、降噪、噪声消除、语音识别、低音调整、高音调整和/或用户输入的处理。处理器可以是处理器、集成电路、应用程序、功能模块等。处理器可以在信号处理芯片或印刷电路板(pcb)中实现。处理器可以被配置为基于对一个或多个电输入信号的处理来提供一个或多个电输出信号。
66、音频设备的输出单元可以是输出换能器。输出换能器可以是扬声器。输出换能器可以被配置用于将来自处理器的电输出信号转换成声输出信号。输出换能器可以经由磁性天线耦接至处理器。
67、音频设备的存储器可以包括易失性和非易失性形式的存储器。
68、还公开了一种存储至少一个程序的计算机可读存储介质,该程序包括指令,当由音频设备的处理器执行时,使音频设备能够执行上述方法。
69、术语计算机可读存储介质应理解为任何物理介质,可以接收和保留电子数据,包括由处理器执行的指令,并且使数据可用于检索。因此,该术语包括硬盘驱动器(hdd)、固态驱动器(ssd)、闪存设备(例如sd卡)、光学存储设备、软盘等。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22761.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。