回声抑制方法、回声抑制模型训练方法及相关设备与流程
- 国知局
- 2024-06-21 11:40:01
本技术涉及语音信号处理,更具体的说,是涉及一种回声抑制方法、回声抑制模型训练方法及相关设备。
背景技术:
1、在扬声器与麦克风耦合的系统中,由扬声器到麦克风之间的回声如果不及时消除,会对系统产生较大的影响。例如,在通信领域,如果近端说话人和远端说话人的声音同时传向远端,经过网络传输产生时延,则远端说话人会听到自己的回声,造成沟通困难。在智能硬件领域,例如对智能电视、音响等能够播放声音的智能交互系统进行语音控制,若播放的声音和说话人一同传入识别系统,造成识别系统的错误识别。
2、在一些场景下,回声信号可能同时包含线性部分和非线性部分。现有回声消除技术一般通过更新自适应线性滤波器,将其与扬声器播放的参考信号卷积,得到估计的线性回声,并从麦克风接收到的信号中减去,得到输出信号。输出信号中还包含残留回声(主要包括非线性回声,以及部分线性回声)。进一步通过神经网络模型来估计非线性部分的回声,将非线性部分回声从上述输出信号中减去,从而抑制残留回声。
3、现有方案使用神经网络估计非线性回声的过程,一般是估计目标信号与去除线性回声后的输出信号在频域的幅度谱的比值(可以称之为实数掩码mask),进而基于估计出的比值从输出信号中还原出目标信号,达到抑制残留回声的目的。但是,现有神经网络估计实数掩码的过程仅考虑了幅度的影响,在一些恶略场景下(示例如信回比较低的信号),麦克风接收的信号的相位也包含了噪声,仅估计幅度谱的mask而不考虑相位包含的噪声,导致还原后的语音信号仍包含带噪相位,听感会收到极大的影响,甚至会出现“机械声”等抑制问题,严重降低了语音信号的质量。
技术实现思路
1、鉴于上述问题,提出了本技术以便提供一种回声抑制方法、回声抑制模型训练方法及相关设备,以在回声抑制过程中同时对语音信号的幅度和相位进行优化,提升回声抑制后的语音信号的质量。具体方案如下:
2、第一方面,提供了一种回声抑制方法,包括:
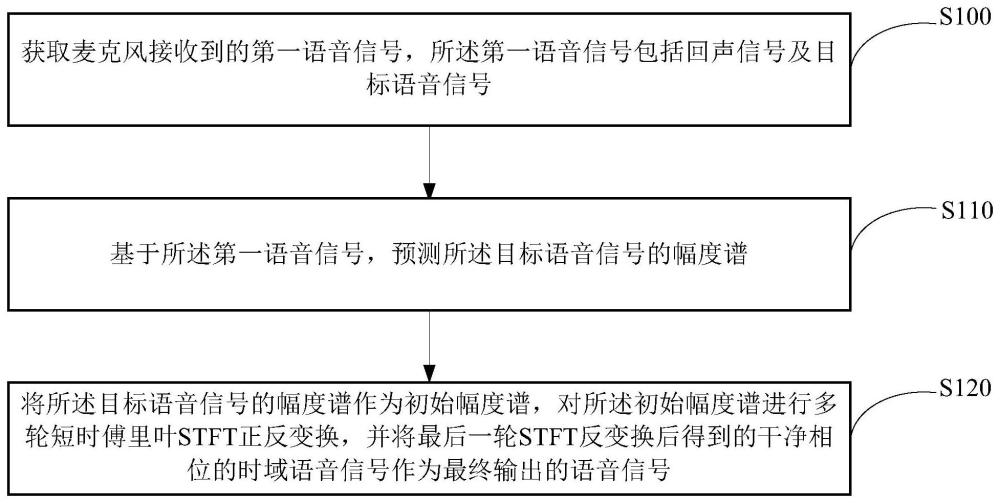
3、获取麦克风接收到的第一语音信号,所述第一语音信号包括回声信号及目标语音信号;
4、基于所述第一语音信号,预测所述目标语音信号的幅度谱;
5、将所述目标语音信号的幅度谱作为初始幅度谱,对所述初始幅度谱进行多轮短时傅里叶stft正反变换,并将最后一轮stft反变换后得到的干净相位的时域语音信号作为最终输出的语音信号。
6、优选地,基于所述第一语音信号,预测所述目标语音信号的幅度谱的过程,包括:
7、获取对所述第一语音信号进行线性回声消除后的第二语音信号;
8、基于所述第一语音信号和所述第二语音信号,预测实数掩码mask,所述mask表示所述目标语音信号和所述第二语音信号在频域的幅度谱的比值;
9、将所述mask乘以所述第二语音信号在频域的幅度谱,得到所述目标语音信号的幅度谱。
10、优选地,基于所述第一语音信号和所述第二语音信号,预测实数掩码mask的过程,包括:
11、将所述第一语音信号和所述第二语音信号输入预训练的回声抑制模型,得到所述实数掩码mask,其中,所述回声抑制模型被配置为参考输入的所述第一语音信号和所述第二语音信号预测所述实数掩码mask的内部状态表示。
12、优选地,所述回声抑制模型的训练过程,包括:
13、获取训练样本及样本标签,所述训练样本包括:包含回声信号和目标语音信号的第一语音训练信号,以及对所述第一语音训练信号进行线性回声消除后的第二语音信号,所述样本标签包括:所述目标语音信号和所述第二语音训练信号在频域的幅度谱的比值;
14、将所述训练样本送入所述回声抑制模型,得到模型预测的实数掩码mask;
15、基于所述预测的实数掩码mask和所述样本标签计算损失函数的值,并按照所述损失函数的值更新回声抑制模型的参数。
16、优选地,基于所述预测的实数掩码mask和所述样本标签计算损失函数的值的过程,包括:
17、以所述预测的实数掩码mask作为目标预测值,按照设定类型的损失函数计算所述目标预测值和所述样本标签之间的损失值。
18、优选地,基于所述预测的实数掩码mask和所述样本标签计算损失函数的值的过程,包括:
19、基于所述预测的实数掩码mask计算所述目标语音信号的幅度谱,并作为初始幅度谱,对所述初始幅度谱进行多轮stft正反变换,基于最后一轮stft反变换得到的干净相位的时域语音信号计算更新后的实数掩码maskk;
20、按照设定类型的损失函数计算所述更新后的实数掩码maskk和所述样本标签之间的损失值。
21、优选地,所述基于最后一轮stft反变换得到的干净相位的时域语音信号计算更新后的实数掩码maskk的过程,包括:
22、将所述第二语音训练信号在频域的幅度谱减去所述目标语音信号的幅度谱和所述噪声信号的幅度谱,结果作为残留回声信号的幅度谱re;
23、按照下述公式计算更新后的实数掩码maskk:
24、
25、其中,xk表示最后一轮stft反变换得到的干净相位的时域语音信号在频域的幅度谱,n表示所述噪声信号的幅度谱。
26、优选地,所述第一语音训练信号还包括噪声信号;
27、获取训练样本及样本标签的过程,包括:
28、将近端扬声器播放的参考信号与房间冲激响应进行卷积,得到线性部分的回声信号,获取由所述近端扬声器和所述麦克风组成的耦合系统的非线性部分的回声信号,由所述非线性部分的回声信号和所述线性部分的回声信号组成完整的回声信号;
29、将目标声源和所述房间冲激响应进行卷积,得到目标语音信号,将噪声声源和所述房间冲激响应进行卷积,得到噪声信号;
30、由所述目标语音信号、所述完整的回声信号和所述噪声信号组合得到所述第一语音训练信号;
31、对所述第一语音训练信号进行线性回声消除,得到所述第二语音训练信号,由所述第一语音训练信号和所述第二语音训练信号作为训练样本;
32、对所述目标语音信号和所述第二语音训练信号分别进行短时傅里叶stft变换,并取频域的幅度谱,计算所述目标语音信号和所述第二语音训练信号在频域的幅度谱的比值,作为样本标签。
33、第二方面,提供了一种回声抑制模型的训练方法,包括:
34、获取训练样本及样本标签,所述训练样本包括:包含回声信号和目标语音信号的第一语音训练信号,以及对所述第一语音训练信号进行线性回声消除后的第二语音信号,所述样本标签包括:所述目标语音信号和所述第二语音训练信号在频域的幅度谱的比值;
35、将所述训练样本送入所述回声抑制模型,得到模型预测的实数掩码mask0;
36、基于所述预测的实数掩码mask0计算所述目标语音信号的幅度谱,并作为初始幅度谱,对所述初始幅度谱进行多轮stft正反变换,基于最后一轮stft反变换得到的干净相位的时域语音信号计算更新后的实数掩码maskk;
37、按照设定类型的损失函数计算所述更新后的实数掩码maskk和所述样本标签之间的损失值,并按照所述损失值更新回声抑制模型的参数。
38、第三方面,提供了一种回声抑制方法,包括:
39、获取麦克风接收到的第一语音信号及对所述第一语音信号进行线性回声消除后的第二语音信号,所述第一语音信号包括回声信号及目标语音信号;
40、将所述第一语音信号和所述第二语音信号输入回声抑制模型,得到预测的实数掩码mask,所述实数掩码mask表示所述目标语音信号和所述第二语音信号在频域的幅度谱的比值,所述回声抑制模型为通过前述回声抑制模型的训练方法行训练得到;
41、将所述预测的实数掩码mask乘以所述第二语音信号在频域的幅度谱,得到所述目标语音信号的幅度谱;
42、对所述目标语音信号的幅度谱做短时傅里叶反变换istft,得到最终输出的语音信号。
43、第四方面,提供了一种回声抑制装置,包括:
44、信号获取单元,用于获取麦克风接收到的第一语音信号,所述第一语音信号包括回声信号及目标语音信号;
45、幅度谱预测单元,用于基于所述第一语音信号,预测所述目标语音信号的幅度谱;
46、后处理单元,用于将所述目标语音信号的幅度谱作为初始幅度谱,对所述初始幅度谱进行多轮短时傅里叶stft正反变换,并将最后一轮stft反变换后得到的干净相位的时域语音信号作为最终输出的语音信号。
47、第五方面,提供了一种回声抑制模型的训练装置,包括:
48、训练数据获取单元,用于获取训练样本及样本标签,所述训练样本包括:包含回声信号和目标语音信号的第一语音训练信号,以及对所述第一语音训练信号进行线性回声消除后的第二语音信号,所述样本标签包括:所述目标语音信号和所述第二语音训练信号在频域的幅度谱的比值;
49、第一计算单元,用于将所述训练样本送入所述回声抑制模型,得到模型预测的实数掩码mask;
50、第二计算单元,用于基于所述预测的实数掩码mask计算所述目标语音信号的幅度谱,并作为初始幅度谱,对所述初始幅度谱进行多轮stft正反变换,基于最后一轮stft反变换得到的干净相位的时域语音信号计算更新后的实数掩码maskk;
51、更新单元,用于按照设定类型的损失函数计算所述更新后的实数掩码maskk和所述样本标签之间的损失值,并按照所述损失值更新回声抑制模型的参数。
52、第六方面,提供了一种回声抑制装置,包括:
53、信号获取单元,用于获取麦克风接收到的第一语音信号及对所述第一语音信号进行线性回声消除后的第二语音信号,所述第一语音信号包括回声信号及目标语音信号;
54、模型计算单元,用于将所述第一语音信号和所述第二语音信号输入回声抑制模型,得到预测的实数掩码mask,所述实数掩码mask表示所述目标语音信号和所述第二语音信号在频域的幅度谱的比值,所述回声抑制模型为通过前述回声抑制模型的训练装置进行训练得到;
55、幅度谱计算单元,用于将所述预测的实数掩码mask乘以所述第二语音信号在频域的幅度谱,得到所述目标语音信号的幅度谱;
56、短时傅里叶反变换单元,用于对所述目标语音信号的幅度谱做短时傅里叶反变换istft,得到最终输出的语音信号。
57、第七方面,提供了一种回声抑制设备,包括:存储器和处理器;
58、所述存储器,用于存储程序;
59、所述处理器,用于执行所述程序,实现如前所述的回声抑制方法的各个步骤。
60、第八方面,提供了一种回声抑制模型的训练设备,包括存储器和处理器;
61、所述处理器,用于执行所述程序,实现如前所述的回声抑制模型的训练方法的各个步骤。
62、第九方面,提供了一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如前所述的回声抑制方法的各个步骤。
63、第十方面,提供了一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如前所述的回声抑制模型的训练方法的各个步骤。
64、借由上述技术方案,本技术基于麦克风接收到的第一语音信号来估计目标语音信号的幅度谱,在此基础上,本技术进一步基于短时傅里叶stft变换的冗余性,对目标信号的相位进行不断优化,也即将估计出的目标语音信号的幅度谱作为初始幅度谱,对该初始幅度谱进行多轮短时傅里叶stft正反变换,通过多轮stft正反变换,可以迭代得到相位更加干净的时域语音信号,从而提升了回声抑制后的语音信号的质量。
65、需要说明的是,上述对初始幅度谱进行多轮stft正反变换的过程,可以是作为后处理操作,也即对预测出的目标语音信号的幅度谱进行后处理,得到最终输出的语音信号。除此之外,还可以是直接对回声抑制模型训练阶段的损失函数值进行修改,也即在回声抑制模型训练阶段,在模型预测出的实数掩码后计算目标语音信号的幅度谱,作为初始幅度谱,经过上述多轮stft正反变换得到干净相位的时域语音信号,并基于此计算更新后的实数掩码,按照更新后的实数掩码和样本标签来计算损失值,使得训练后的回声抑制模型可以更加准确的预测实数掩码,进而基于预测的实数掩码还原出质量更高的目标语音信号。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22776.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表