一种跨语言端到端情感语音合成方法及系统
- 国知局
- 2024-06-21 11:40:31
本发明涉及智能数字信号处理领域,具体涉及一种跨语言端到端情感语音合成方法及系统。
背景技术:
1、语音合成是一种将文本转化为自然流畅的语音音频的技术。近年来,深度学习方法在数字信号处理领域发挥巨大效力,深度神经网络以较强的泛化和拟合能力支持着语音合成领域技术不断更新,取得显著进展。传统的语音合成系统往往显得单调乏味,情感语音合成则能够为合成语音赋予生动的情感色彩,使之更具人性化和自然感。这方面的研究同样主要依赖于深度学习技术,特别是循环神经网络(rnn)和变分自动编码器(vae)等模型的发展,通过在训练过程中引入情感相关的标签或特征,能够使合成语音表达喜怒哀惧等情感状态。
2、公开号为cn115359774a的中国发明申请公开了一种基于端到端的音色及情感迁移的跨语言语音合成方法。该发明采集用户的少量语音,在对语音进行预处理后得到语音数据,将语音数据投入到训练完成的学习网络架构中,通过学习网络架构中的说话人编码器,提取出携带说话人音色和情感特征的嵌入向量,然后通过学习网络架构中的合成器,合成目标语音的梅尔频谱,最后将目标语音的梅尔频谱输入声码器中,合成目标语音。该方法处理过程复杂,合成效果差。
3、该方法对语音包含的情感缺乏针对性的解耦过程,使得最终生成的语音情感效果一般,且过于依赖原始说话人数据的品质,使用该方法的灵活性不足。
技术实现思路
1、本发明的目的在于满足某种语言情感数据缺失的低资源条件下生成该语言情感语音的要求。
2、为达到上述目的,本发明通过下述技术方案实现。
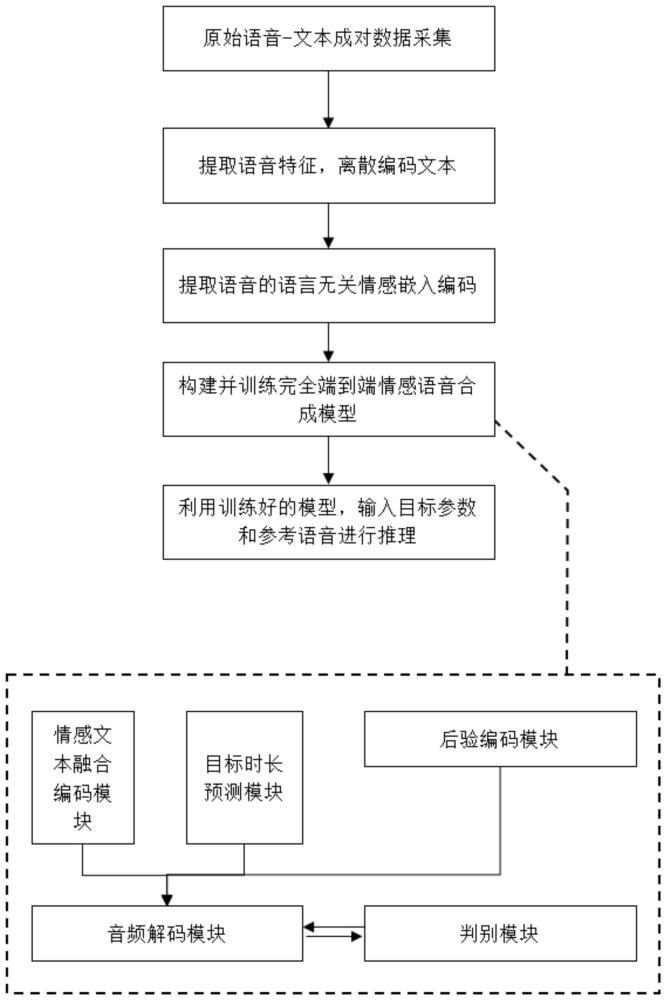
3、本发明提出一种跨语言端到端情感语音合成方法,包括:
4、采集大量不同说话人的成对的语音-音素级文本数据;
5、提取语音的频域特征和情感嵌入编码,对说话人id和文本数据进行离散化编码,并整理形成训练数据集;
6、构建完全端到端情感语音合成模型,并利用训练数据集训练该模型,直至模型收敛;
7、所述完全端到端情感语音合成模型,包括:情感文本融合编码模块、目标时长预测模块和音频解码模块;其中,
8、所述情感文本融合编码模块,用于通过编码器结构获取与说话人id、文本、情感均相关的中间嵌入表示;
9、所述目标时长预测模块,用于输出预测的音素时长;
10、所述音频解码模块,用于根据中间嵌入表示和音素时长,通过上采样网络运算获得生成波形;
11、将待合成说话人id、文本序列和情感嵌入编码输入到训练至收敛的完全端到端情感语音合成模型中,输出得到合成的情感语音音频结果。
12、作为上述技术方案的改进之一,所述完全端到端情感语音合成模型,还包括:后验编码模块和判别模块;
13、所述后验编码模块,用于在训练阶段对语音提取后验编码;其中,后验编码与先验编码被同一个高斯分布约束,所述先验编码包括中间嵌入表示和音素时长;
14、所述判别模块,与音频解码模块形成生成-对抗关系,用于以提高音频解码模块的生成能力。
15、作为上述技术方案的改进之一,提取的语音的频域特征包括:线性频谱和mel域谱;其中,
16、第k个短时段的线性频谱xk(ω)表示为:
17、
18、其中,x(n)为原始语音信号,h(·)为所选窗函数,ω表示频率,e为自然对数的底,j为虚数单位;
19、第k个短时段的第i维的mel域谱melk(ω,i)表示为:
20、melk(ω,i)=fbank(i,ωmax,ωmin,ω)pk(ω)
21、其中,pk(ω)为第k个短时段的短时功率谱,pk(ω)=|xk(ω)|2;fbank是通过预设的最大频率ωmax和最小频率ωmin构建的i维mel域滤波器组。
22、作为上述技术方案的改进之一,所述对文本数据进行离散化编码,包括:将文本数据中的所有不同音素依任意顺序映射到从1开始的正整数,将文本数据转换为一条包含若干正整数的序列。
23、作为上述技术方案的改进之一,所述语言无关情感嵌入编码,通过将每条语音输入预训练的情感判别系统中得到;
24、所述情感判别系统包括一个双路并行神经网络和说话人解耦网络共同组成的分类器;
25、所述双路并行神经网络包括transformer结构、卷积神经网络两条支路和一个总线上用于降维分类输出的线性投影层;
26、所述说话人解耦网络包括时延神经网络(tdnn,time delay neural network)结构。
27、作为上述技术方案的改进之一,所述整理形成训练数据集,包括:
28、对于每条语音,将原始信号、说话人id、提取的语音线性频谱、mel域谱、量化音素文本序列和语言无关情感嵌入编码打包为一个元组,并将原始信号、频谱、mel域谱、情感嵌入编码转换为浮点型高维张量,说话人id和量化音素文本序列转化为长整型张量;按照一定的容量比例,划分所有数据为训练集和测试集。
29、本发明还提出一种跨语言端到端情感语音合成系统,所述系统的处理过程包括:
30、采集大量不同说话人的成对的语音-音素级文本数据;
31、提取语音的频域特征和情感嵌入编码,对说话人id和文本数据进行离散化编码,并整理形成训练数据集;
32、构建完全端到端情感语音合成模型,并利用训练数据集训练该模型,直至模型收敛;
33、所述完全端到端情感语音合成模型,包括:情感文本融合编码模块、目标时长预测模块和音频解码模块;其中,
34、所述情感文本融合编码模块,用于通过编码器结构获取与说话人id、文本、情感均相关的中间嵌入表示;
35、所述目标时长预测模块,用于输出预测的音素时长;
36、所述音频解码模块,用于根据中间嵌入表示和音素时长,通过上采样网络运算获得生成波形;
37、将待合成说话人id、文本序列和情感嵌入编码输入到预先建立并训练至收敛的完全端到端情感语音合成模型中,输出得到合成的情感语音音频结果。
38、本发明与现有技术相比优点在于:
39、总体而言,该方法构建一套完全端到端的语音合成模型架构,从文本到语音直接建立映射关系,利用深度学习强大的表征学习能力,能够合成自然、流畅、贴近人类语感和听感的语音。该方法突破情感在语音中难以精准描述的瓶颈,将情感从语音中单独解耦并编码,克服数据低资源情况下的障碍,实现了跨语言的情感合成。具体地包括如下优点:
40、1、以预训练的情感判别系统作为编码器,判别系统的目标是分类任务,使得该编码器拥有较好的将情感表示从语音中解耦的能力,情感的编码更加准确、纯粹,从而生成效果更符合人类听觉;
41、2、数据采集和训练过程对音频和文本的语言没有限制,使得该合成系统可以跨语言工作,不受到单一语种编码时说话人母语口音残留等影响;
42、3、可以从参考语音进行推理,即不需要指出具体的情感类型或者描述,只需要给出一句想要接近的“例句”——参考语音,就可以仿制地让目标说话人合成出参考语音所具有的情感,增加了使用的灵活性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22830.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。