一种基于嵌入特征融合的防伪说话人识别方法及系统
- 国知局
- 2024-06-21 11:40:53
本发明涉及防伪检测,具体涉及一种基于嵌入特征融合的防伪说话人识别方法及系统。
背景技术:
1、基于说话人声纹特征的身份认证技术在各种智能设备、网络交易的安全访问控制中发挥着重要作用。但近年来新兴的伪造语音技术可以针对说话人识别系统发起恶意的攻击,非法获取目标用户的访问权限,实现对目标用户的智能设备、安全账户的操控,这给基于声纹特征的安全访问控制带来了巨大的威胁。因此如何构建高效的防伪说话人识别系统是一个重要且迫切的研究课题。
2、现有的基于嵌入特征融合的防伪说话人识别框架主要分为两个阶段,第一阶段是嵌入特征提取,首先采用说话人识别模型提取出注册和测试的说话人嵌入特征,然后采用语音防伪检测模型提取出测试语音的鉴伪嵌入特征。第二阶段是特征融合阶段,前面提取出的三个嵌入特征采用拼接的方式输入下游分类网络中,最终输出具备伪造感知能力的说话人识别得分。对嵌入特征进行拼接是一种较为简单的融合方式,如何对嵌入特征进行高效的融合以提高防伪说话人识别系统最终的打分性能是有待深入思考和解决的问题。
3、目前大多数工作都试图对说话人嵌入特征和音频鉴伪嵌入特征进行一定的处理,从而提高防伪说话人识别系统对测试语音的打分性能,但处理的过程都较为复杂,同时会带来比较大的计算量,进而影响到整体系统的实时性能。
技术实现思路
1、针对现有技术中的嵌入特征融合处理过程复杂问题,本技术提出了一种基于嵌入特征融合的防伪说话人识别方法及系统。
2、根据本发明的一方面,提出了一种基于嵌入特征融合的防伪说话人识别方法,包括:
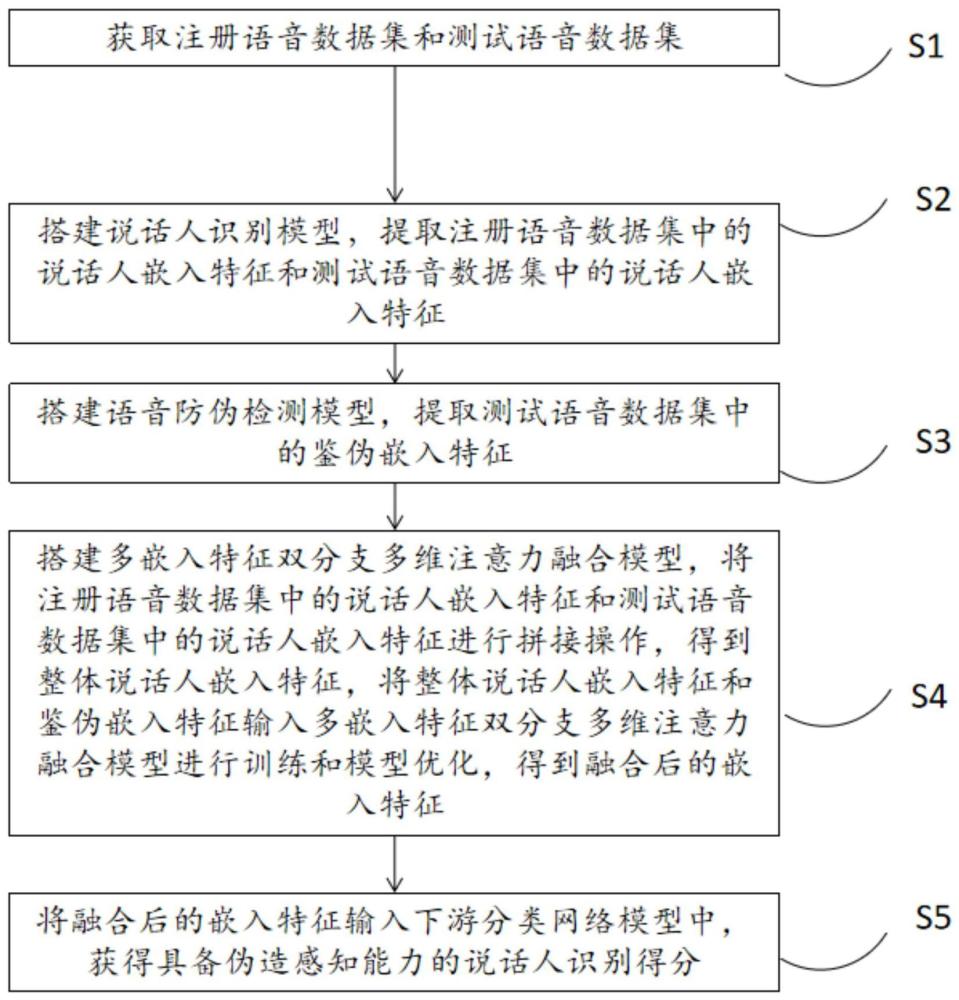
3、s1、获取注册语音数据集和测试语音数据集;
4、s2、搭建说话人识别模型,提取注册语音数据集中的说话人嵌入特征easv_enrol和测试语音数据集中的说话人嵌入特征easv_test;
5、s3、搭建语音防伪检测模型,提取测试语音数据集中的鉴伪嵌入特征ecm;
6、s4、搭建多嵌入特征双分支多维注意力融合模型,将注册语音数据集中的说话人嵌入特征easv_enrol和测试语音数据集中的说话人嵌入特征easv_test进行拼接操作,得到整体说话人嵌入特征easv,将整体说话人嵌入特征easv和鉴伪嵌入特征ecm输入多嵌入特征双分支多维注意力融合模型进行训练和模型优化,得到融合后的嵌入特征efusion;
7、s5、将融合后的嵌入特征efusion输入下游分类网络模型中,获得具备伪造感知能力的说话人识别得分。
8、优选的,s2中所述的说话人识别模型由输入层、卷积模块、特征融合层、输出层组成,提取注册语音数据集和测试语音数据集对应的声学特征,分别输入说话人识别模型。
9、进一步优选的,s2具体步骤包括,输入层为卷积核为1×1的卷积层,卷积模块为多组卷积核为3×3的卷积层和残差连接层,特征融合层为卷积核为1×1的卷积层,输出层为卷积核为1×1的卷积层,将所述声学特征输入说话人识别模型中,经过输入层后输入卷积模块,其输出被平均分为m组特征,第1个特征不进行操作输出y1,第2个特征通过卷积核为3×3的卷积层后输出y2,第3个特征与第二部分的输出结果经过残差连接层再通过卷积核为3×3的卷积层输出结果y3,以此类推,第m个特征与第m-1部分输出结果经过残差连接层再通过卷积核为3×3的卷积层输出结果ym,最后所有的输出的结果进行拼接,经过卷积核为1×1的特征融合层进行特征融合,再经过卷积核为1×1的卷积层进行降维,得到注册语音数据集中的说话人嵌入特征easv_enrol和测试语音集中说话人嵌入特征easv_test。
10、优选的,s3中所述语音防伪检测模型基于深度神经网络搭建,将测试语音数据集输入语音防伪检测模型,得到鉴伪嵌入特征ecm。
11、优选的,s4中所述多嵌入特征双分支多维注意力融合模型包括嵌入特征变换模块a1、注意力模块a2和特征融合模块a3,所述嵌入特征变换模块a1包括由线性层、归一化层、激活函数层、线性层组成的变换层,注意力模块a2包括两个线性层和激活函数层,特征融合模块a3包括激活函数层和特征融合层。
12、进一步优选的,s4中所述步骤具体包括,
13、s41,所述整体说话人嵌入特征easv和鉴伪嵌入特征ecm输入多嵌入特征双分支多维注意力融合模型,分别输入嵌入特征变换模块a1,经由线性层、归一化层、激活函数、线性层的处理变换为对应的嵌入特征和
14、s42,将整体说话人嵌入特征easv和鉴伪嵌入特征ecm进行拼接,输入注意力模块a2,得到一组注意力分数k;
15、s43,变换后的嵌入特征和分别输入特征融合模块a3后,依据注意力分数k,分配不同的权重,得到融合后的嵌入特征efusion。
16、优选的,s4所述的多嵌入特征双分支多维注意力融合模型采用带权重的交叉熵的损失函数进行训练,采用adam优化器进行优化。
17、进一步优选的,所述分类网络模型为三层带激活函数的线性层。
18、根据本发明的第二方面,提出了一种基于嵌入特征融合的防伪说话人识别系统,包括以下模块:
19、数据收集模块:用于获取注册语音数据集和测试语音数据集;
20、说话人嵌入特征提取模块:用于搭建说话人识别模型,提取注册语音数据集中的说话人嵌入特征easv_enrol和测试语音数据集中的说话人嵌入特征easv_test;
21、鉴伪嵌入特征提取模块:搭建语音防伪检测模型,提取测试语音数据集中的鉴伪嵌入特征ecm;
22、嵌入特征融合模块:搭建多嵌入特征双分支多维注意力融合模型,将注册语音数据集中的说话人嵌入特征easv_enrol和测试语音数据集中的说话人嵌入特征easv_test进行拼接操作,得到整体说话人嵌入特征easv,将整体说话人嵌入特征easv和鉴伪嵌入特征ecm输入多嵌入特征双分支多维注意力融合模型进行训练和模型优化,得到融合后的嵌入特征efusion;
23、分类识别打分模块:用于将融合后的嵌入特征efusion输入下游分类网络模型中,获得具备伪造感知能力的说话人识别得分。
24、第三方面,本发明实施例提供了一种计算机可读介质,其上存储有计算机程序,所述计算机程序在被处理器执行时实施如第一方面中任一实施方式所述的方法。
25、第四方面,本发明实施例提供了一种计算系统,包括处理器和存储器,所述处理器被配置为执行如第一方面中任一实施方式所述的方法。
26、与现有技术相比,本发明的有益成果在于:
27、(1)本发明将具有良好的区分性的说话人嵌入特征和音频鉴伪嵌入特征进行双分支多维注意力融合,使得最终得到的嵌入特征同时具备说话人识别的能力和伪造感知能力,进一步提高嵌入特征的鉴别能力,并且使得输入下游分类网络的嵌入特征维度降低。
28、(2)本发明所采用的嵌入特征双分支多维注意力融合方式高效快捷,该融合方式给整体框架带来的额外计算量处于较小的范围,克服了其他框架嵌入特征融合过程复杂且计算量较大的问题,并且灵活性高和可拓展性强。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22861.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。