一种方言连续语音的识别方法、装置、设备及存储介质
- 国知局
- 2024-06-21 11:40:49
本技术涉及连续语音识别,特别是涉及一种方言连续语音的识别方法、装置、设备及存储介质。
背景技术:
1、随着深度学习技术在语音识别领域的突破,连续语音识别技术已广泛应用于教育、娱乐、医疗、交通、军事等各行各业,应用的效果得到了业界的普遍认可。但由于连续语音识别技术属于数据驱动型的统计模式,系统训练数据所覆盖的数量与质量直接影响着系统的识别性能。因为行业领域的不同,同一个语种的连续语音识别任务,所要识别的数据具有非常明显的差异性,包括文本领域、信道、环境噪声、话者方言口音等等因素。这些差异性的客观存在,导致很难构建一个适用全领域、行业且适配各种噪声及方言口音的连续语音识别系统,需要构建特定领域且方言口音适配的识别模型。这就给语料收集带来严重挑战,特别是在js领域某些特定的指挥系统,语音指令具有很强的专业性,指挥人员带有严重的方言口音,需要专门录制相关人员大量的语音指令数据并进行标准处理,供识别系统进行迭代学习。但实际数据收集过程中,收集这些指挥人员的语音数据往往不太可能,只能能过专门录音的模式,但录音的情况下,往往与真实情况相关较大,且受时间与成本方面的考虑,参与录制的说话人较小,且产生的数据量往往不尽人意。
2、尽管当前无监督技术的应用,如基于encoder-decoder的端到端识别方案,encoder模块可基于监督数据进行学习,但对于decoder仍然需要几十、上百小时有监督数据的学习。假定已有一个已成熟的用于日常交流的中文识别系统,识别率可达95%以上,那么,其直接应用于js术语场景的语音指令系统,其识别率会显著下降,如果是带方言口音的情形,其系统可能无法正常工作。
3、上述语音识别系统因领域变化、专业术语、方言口音等因素造成的识别性能下降的情形,通常的做法是组织收集这个领域的数据,进行人工标注,形成语音句对,对已有的识别模型进行迭代升级,进行领域适配,使模型学习获得领域相关的术语及话者方言口音的识别能力。
4、然而,在相对特殊的js应用场景,因行业的保密性以及话者的特殊性,数据采集制作成了连续语音识别推广应用的一个瓶颈,主要表现在数据难收集,数据量非常限,无法满足模型领域适配的数据条件,另外专项的录音收集费用投入及持续周期也进一步影响了识别系统的推广应用。最终导致方言连续语音的数据采集困难、周期长,且成本高的问题。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种能够在语音样本数据量少的情况下,快速高效的识别出特殊方言的一种方言连续语音的识别方法、装置、设备及存储介质。
2、一种方言连续语音的识别方法,所述方法包括:
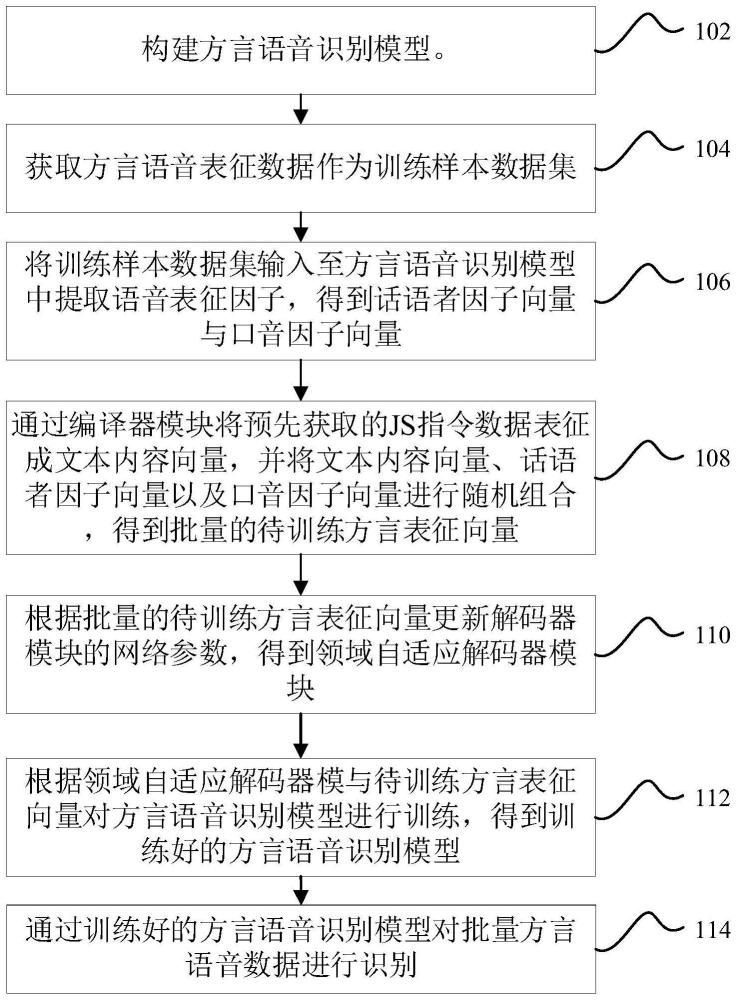
3、构建方言语音识别模型。方言语音识别模型包括编译器模块与解码器模块。
4、获取方言语音表征数据作为训练样本数据集,训练样本数据集包括:话语者数据集与口音数据集。
5、将训练样本数据集输入至方言语音识别模型中提取语音表征因子,得到话语者因子向量与口音因子向量。
6、通过编译器模块将预先获取的js指令数据表征成文本内容向量,并将文本内容向量、话语者因子向量以及口音因子向量进行随机组合,得到批量的待训练方言表征向量。
7、根据批量的待训练方言表征向量更新解码器模块的网络参数,得到领域自适应解码器模块。
8、根据领域自适应解码器模块与待训练方言表征向量对方言语音识别模型进行训练,得到训练好的方言语音识别模型。
9、通过训练好的方言语音识别模型对批量方言语音数据进行识别。
10、在其中一个实施例中,还包括:通过在音频序列类模型的输出层设置多任务分类标记模块,多任务分类标记模块对每一个批次的训练样本数据集进行任务分类,得到训练样本数据集的表征因子。将表征因子输入至所述音频序列类模型进行语音数据融合训练,得到连续方言语音数据,根据连续方言语音数据、多任务分类标记模块、编译器模块以及解码器模块构建方言语音识别模型。
11、在其中一个实施例中,还包括:根据应用场景录制用户的方言语音数据,利用方言语音数据获取批量的js指令数据。
12、在其中一个实施例中,还包括:将训练样本数据集入至方言语音识别模型中,并在多任务分类标记模块的上一层分别对话语者数据集与口音数据集进行语音表征因子的提取,得到话语者因子向量与口音因子向量。
13、在其中一个实施例中,还包括:通过编译器模块将预先获取的js指令数据表征成文本内容向量,并将相同数量的文本内容向量、话语者因子向量以及口音因子向量进行随机组合,得到多组随机方言表征向量。多组随机方言表征向量之间采用加法操作生成批量的待训练方言表征向量。
14、在其中一个实施例中,还包括:根据批量的待训练方言表征向量更新解码器模块的网络参数,根据已更新的网络参数训练解码器模块,得到领域自适应解码器模块。
15、一种方言连续语音的识别装置,所述装置包括:
16、模型构建模块,用于构建方言语音识别模型。方言语音识别模型包括编译器模块与解码器模块。
17、训练样本数据集获取模块,用于获取方言语音表征数据作为训练样本数据集,训练样本数据集包括:话语者数据集与口音数据集。
18、表征因子提取模块,用于将训练样本数据集输入至方言语音识别模型中提取语音表征因子,得到话语者因子向量与口音因子向量。
19、待训练方言表征向量获取模块,用于通过编译器模块将预先获取的js指令数据表征成文本内容向量,并将文本内容向量、话语者因子向量以及口音因子向量进行随机组合,得到批量的待训练方言表征向量。
20、解码器自适应模块,用于根据批量的待训练方言表征向量更新解码器模块的网络参数,得到领域自适应解码器模块。
21、训练模块,用于根据领域自适应解码器模块与待训练方言表征向量对方言语音识别模型进行训练,得到训练好的方言语音识别模型。
22、语音识别模块,用于通过训练好的方言语音识别模型对批量方言语音数据进行识别。
23、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
24、构建方言语音识别模型。方言语音识别模型包括编译器模块与解码器模块。
25、获取方言语音表征数据作为训练样本数据集,训练样本数据集包括:话语者数据集与口音数据集。
26、将训练样本数据集输入至方言语音识别模型中提取语音表征因子,得到话语者因子向量与口音因子向量。
27、通过编译器模块将预先获取的js指令数据表征成文本内容向量,并将文本内容向量、话语者因子向量以及口音因子向量进行随机组合,得到批量的待训练方言表征向量。
28、根据批量的待训练方言表征向量更新解码器模块的网络参数,得到领域自适应解码器模块。
29、根据领域自适应解码器模块与待训练方言表征向量对方言语音识别模型进行训练,得到训练好的方言语音识别模型。
30、通过训练好的方言语音识别模型对批量方言语音数据进行识别。
31、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
32、构建方言语音识别模型。方言语音识别模型包括编译器模块与解码器模块。
33、获取方言语音表征数据作为训练样本数据集,训练样本数据集包括:话语者数据集与口音数据集。
34、将训练样本数据集输入至方言语音识别模型中提取语音表征因子,得到话语者因子向量与口音因子向量。
35、通过编译器模块将预先获取的js指令数据表征成文本内容向量,并将文本内容向量、话语者因子向量以及口音因子向量进行随机组合,得到批量的待训练方言表征向量。
36、根据批量的待训练方言表征向量更新解码器模块的网络参数,得到领域自适应解码器模块。
37、根据领域自适应解码器模块与待训练方言表征向量对方言语音识别模型进行训练,得到训练好的方言语音识别模型。
38、通过训练好的方言语音识别模型对批量方言语音数据进行识别。
39、上述一种方言连续语音的识别方法、装置、设备及存储介质,通过构建方言语音识别模型,将训练样本数据集输入至方言语音识别模型中提取语音表征因子,得到话语者因子向量与口音因子向量,使得元数据录制简单、方便,周期短、成本低。然后,通过编译器模块将预先获取的js指令数据表征成文本内容向量,并将文本内容向量、话语者因子向量以及口音因子向量进行随机组合,得到批量的待训练方言表征向量,基于因子解耦并实现因子编码,能够规避无法采集领域数据的极端条件下,模型无法自适应学习的问题,还能够充分利用非平行语料的说话人及口音数据。进而,通过因子向量融合训练,得到领域自适应解码器模块,能够加快特殊语言、方言、加密语言等语音识别应用在各个领域的快速推广。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22856.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。