一种麦克风语音增强方法和装置与流程
- 国知局
- 2024-06-21 11:42:37
本申请涉及语音识别,尤其涉及一种麦克风语音增强方法和装置。
背景技术:
1、随着无线通讯的发展,全球移动电话用户越来越多,嘈杂的环境会影响人们在语音沟通中的效果,在当前的主流通讯软件中,通常采用不同语音增强算法实现对通话过程中含噪音频进行处理,传统方法可以实现对稳态噪声的处理,优点是运算复杂度低,深度学习方法通常用来去除瞬态噪声,效果较传统方法要好,但是运算复杂度高。
2、手机等通讯设备的麦克风采集到的语音信号普遍信噪比不够高,特别是在街道汽车等高噪声环境中,需要提高音量才能使对方听清。所以需要通过语音增强的方法来提升输入语音的信噪比,改善通讯质量。
技术实现思路
1、有鉴于此,本申请提供一种麦克风语音增强方法和装置,用于解决手机等通讯设备的麦克风采集到的语音信号普遍信噪比不够高,导致通讯质量过低的问题。
2、具体地,本申请是通过如下技术方案实现的:
3、根据本申请实施例的第一方面,提供一种麦克风语音增强方法,其特征在于,应用于语音处理模块,所述方法包括:
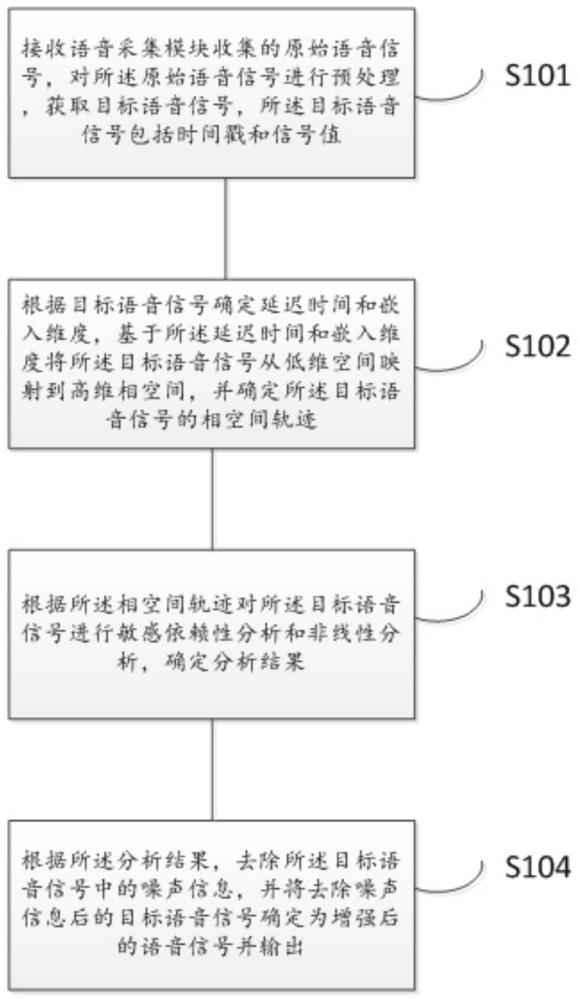
4、接收语音采集模块收集的原始语音信号,对所述原始语音信号进行预处理,获取目标语音信号,所述目标语音信号包括时间戳和信号值;
5、根据目标语音信号确定延迟时间和嵌入维度,基于所述延迟时间和嵌入维度将所述目标语音信号从低维空间映射到高维相空间,并确定所述目标语音信号的相空间轨迹;
6、根据所述相空间轨迹对所述目标语音信号进行敏感依赖性分析和非线性分析,确定分析结果;
7、根据所述分析结果,去除所述目标语音信号中的噪声信息,并将去除噪声信息后的目标语音信号确定为增强后的语音信号并输出。
8、可选的,所述根据目标语音信号确定延迟时间和嵌入维度包括:
9、通过所述目标语音信号中各个时间戳以及在所述时间戳对应的信号值确定所述目标语音信号的自相关函数以及对应的函数图;
10、确定所述函数图确定所述自相关函数的峰值,将所述峰值对应的时间间隔确定为延迟时间;并将所述函数图上衰减到接近零之前的峰值对应的维度作为嵌入维度。
11、可选的,所述进行敏感依赖性分析,确定分析结果包括:
12、从所述目标语音信号中选择能够反映语音信号特征的敏感分析指标,如语音信号的频率、幅度、时长;
13、计算所述目标语音信号的目标值并选取不确定因素;
14、计算所述不确定因素变动时对分析指标的影响程度:通过模拟或实验的方式,改变不确定因素的取值,并观察分析指标的变化情况,以确定分析结果。
15、可选的,所述进行非线性分析,确定分析结果包括:
16、通过所述函数图确定所述目标语音信号的非线性特性的判断结果,根据所述判断结果确定非线性模型,并根据所述非线性模型确定分析结果。
17、可选的,所述根据所述分析结果,去除所述目标语音信号中的噪声信息包括:
18、根据所述分析结果,对噪声不敏感或能够表征语音本质的特征进行提取,利用分类器将噪声信息与纯净语音信息进行区分,并根据分类结果对所述目标语音信号中的噪声信息进行抑制或替换。
19、根据本申请实施例的第二方面,提供一种麦克风语音增强装置,其特征在于,应用于语音处理模块,所述装置包括:
20、接收单元,用于接收语音采集模块收集的原始语音信号,对所述原始语音信号进行预处理,获取目标语音信号,所述目标语音信号包括时间戳和信号值;
21、映射单元,用于根据目标语音信号确定延迟时间和嵌入维度,基于所述延迟时间和嵌入维度将所述目标语音信号从低维空间映射到高维相空间,并确定所述目标语音信号的相空间轨迹;
22、分析单元,用于根据所述相空间轨迹对所述目标语音信号进行敏感依赖性分析和非线性分析,确定分析结果;
23、去噪单元,用于根据所述分析结果,去除所述目标语音信号中的噪声信息,并将去除噪声信息后的目标语音信号确定为增强后的语音信号并输出。
24、可选的,所述映射单元根据目标语音信号确定延迟时间和嵌入维度包括:
25、通过所述目标语音信号中各个时间戳以及在所述时间戳对应的信号值确定所述目标语音信号的自相关函数以及对应的函数图;
26、确定所述函数图确定所述自相关函数的峰值,将所述峰值对应的时间间隔确定为延迟时间;并将所述函数图上衰减到接近零之前的峰值对应的维度作为嵌入维度。
27、可选的,所述分析单元进行敏感依赖性分析,确定分析结果包括:
28、从所述目标语音信号中选择能够反映语音信号特征的敏感分析指标,如语音信号的频率、幅度、时长;
29、计算所述目标语音信号的目标值并选取不确定因素;
30、计算所述不确定因素变动时对分析指标的影响程度:通过模拟或实验的方式,改变不确定因素的取值,并观察分析指标的变化情况,以确定分析结果。
31、可选的,所述分析单元进行非线性分析,确定分析结果包括:
32、通过所述函数图确定所述目标语音信号的非线性特性的判断结果,根据所述判断结果确定非线性模型,并根据所述非线性模型确定分析结果。
33、可选的,所述去噪单元根据所述分析结果,去除所述目标语音信号中的噪声信息包括:
34、根据所述分析结果,对噪声不敏感或能够表征语音本质的特征进行提取,利用分类器将噪声信息与纯净语音信息进行区分,并根据分类结果对所述目标语音信号中的噪声信息进行抑制或替换。
35、由以上技术方案可以看出,本申请中,获取语音信号之后,通过对该语音信号进行预处理,以获得目标语音信号,并通过目标语音信号确定自相关函数和函数图,确定延迟时间和嵌入维度,以确定目标语音信号的相空间轨迹;通过该相空间轨迹进行语音分析,最终根据分析结果去除噪声信息并输出。这对麦克风采集的语音信息进行了语音增强,解决了手机等通讯设备的麦克风采集到的语音信号普遍信噪比不够高的问题,改善了通讯质量。
技术特征:1.一种麦克风语音增强方法,其特征在于,应用于语音处理模块,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述根据目标语音信号确定延迟时间和嵌入维度包括:
3.根据权利要求1所述的方法,其特征在于,所述进行敏感依赖性分析,确定分析结果包括:
4.根据权利要求1所述的方法,其特征在于,所述进行非线性分析,确定分析结果包括:
5.根据权利要求1所述的方法,其特征在于,所述根据所述分析结果,去除所述目标语音信号中的噪声信息包括:
6.一种麦克风语音增强装置,其特征在于,应用于语音处理模块,所述装置包括:
7.根据权利要求6所述的装置,其特征在于,所述映射单元根据目标语音信号确定延迟时间和嵌入维度包括:
8.根据权利要求6所述的装置,其特征在于,所述分析单元进行敏感依赖性分析,确定分析结果包括:
9.根据权利要求6所述的装置,其特征在于,所述分析单元进行非线性分析,确定分析结果包括:
10.根据权利要求6所述的装置,其特征在于,所述去噪单元根据所述分析结果,去除所述目标语音信号中的噪声信息包括:
技术总结本发明适用于语音识别技术领域,提供了一种麦克风语音增强方法和装置。在本实施例中,获取语音信号之后,通过对该语音信号进行预处理,以获得目标语音信号,并通过目标语音信号确定自相关函数和函数图,确定延迟时间和嵌入维度,以确定目标语音信号的相空间轨迹;通过该相空间轨迹进行语音分析,最终根据分析结果去除噪声信息并输出。这对麦克风采集的语音信息进行了语音增强,解决了手机等通讯设备的麦克风采集到的语音信号普遍信噪比不够高的问题,改善了通讯质量。技术研发人员:赖清海受保护的技术使用者:深圳市研音科技有限公司技术研发日:技术公布日:2024/4/17本文地址:https://www.jishuxx.com/zhuanli/20240618/23064.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表