一种基于大模型的智能交互方法、系统、设备及存储介质与流程
- 国知局
- 2024-06-21 11:43:04
本发明涉及人工智能,具体提供一种基于大模型的智能交互方法、系统、设备及存储介质。
背景技术:
1、现阶段主流的人机交互系统通常由asr语音识别,llm大语言模型,tts语音合成系统等多个算法模块,结合复杂的算法流程和异常处理逻辑开发来共同完成,被广泛应用在各类智能人机交互场景。其中,asr语音识别算法模块,用于将人的语音输入识别成文字内容;llm大语言模型接收asr模块的文字输出,进行用户意图识别和语义理解后,输出对应的文本响应;最后llm大语言模型生成的文本内容送入到tts语言合成模块,生成高质量、自然、拟人的语音播放出来。
2、尽管当前人机交互组成的各算法模型,在各自的模态下独立进行的优化和性能提升,但是仍然面临着几个较难解决的问题:
3、1、asr对场景(远近场、环境噪声)、说话人(口音、语速)、方言等自适应能力和鲁棒性不足,导致识别效果较差,从而在第一步就导致交互失败;
4、2、由于asr的训练数据中蕴含的文本语义信息较少,asr模型常采用外接ngram或rnn语言模型,以提升转写的准确性,但此类外接的语言模型仍基于单一语种的文本内容构建,只适用于特点的语言和场景,通用性较低;
5、3、llm大语言模型只有文本单一模态的信息,在交互时,缺乏语音中蕴含的副语言信息,使得无法正确理解用户意图,导致生成的内容南辕北辙,影响实际交互体验;
6、4、tts语音合成的文本前端模块,将文本转换成正确的读法、发音、韵律停顿,需要依赖大量的人工进行维护和异常修复,但文本新词层出不穷,文本内容丰富多样,极大的影响了预测准确度,从而导致合成的可懂度,自然度下降;
7、5、各算法模型的相互独立,在交互流程中,产生的识别误差会级联放大,从而降低整体交互效果。
8、因此,上述人机交互方案中由于缺乏更高层的语义、更底层的细腻的语音特性信息,往往导致的人机交互体验较差,是亟需解决的技术问题。
技术实现思路
1、为了克服上述缺陷,提出了本发明,以提供解决或至少部分地解决传统人机交互方案中由于缺乏更高层的语义、更底层的细腻的语音特性信息所导致的人机交互体验较差的技术问题。
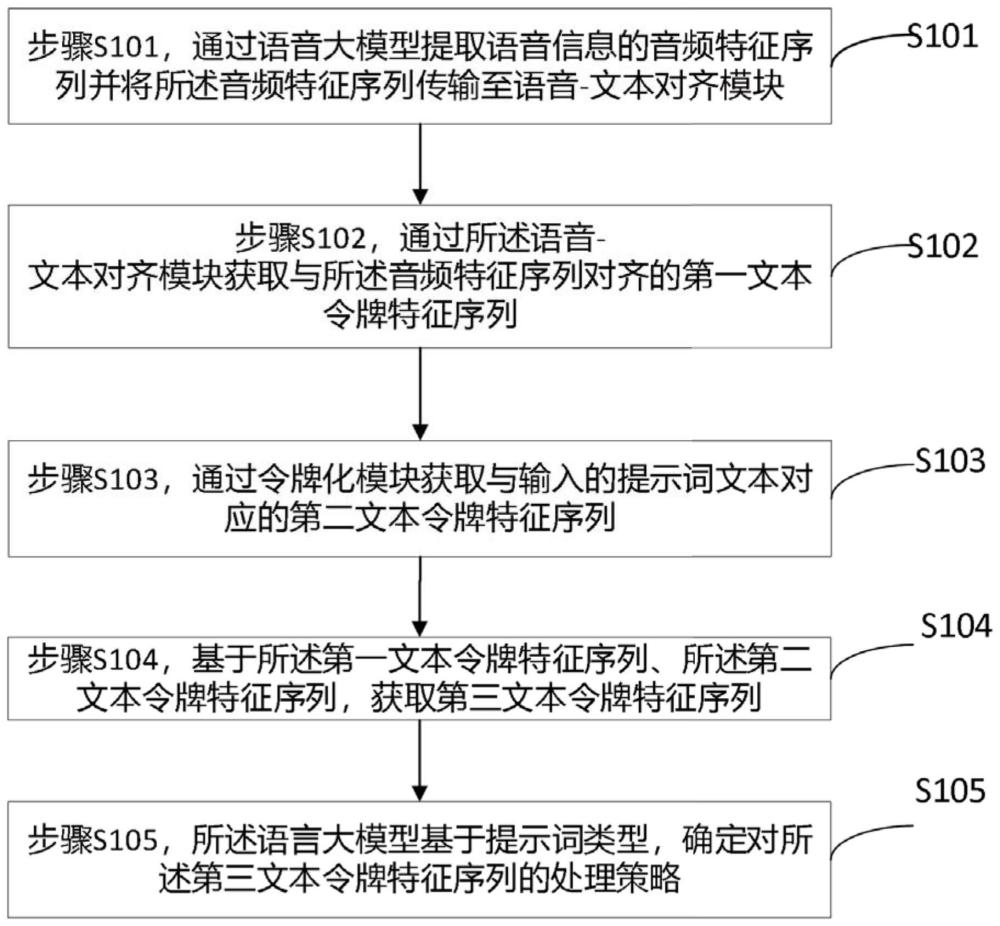
2、在第一方面,本发明提供了一种基于大模型的智能交互方法,包括:
3、通过语音大模型提取语音信息的音频特征序列并将所述音频特征序列传输至语音-文本对齐模块;
4、通过所述语音-文本对齐模块获取与所述音频特征序列对齐的第一文本令牌特征序列;
5、通过令牌化模块获取与输入的提示词文本对应的第二文本令牌特征序列;
6、基于所述第一文本令牌特征序列、所述第二文本令牌特征序列,获取第三文本令牌特征序列;
7、所述语言大模型基于提示词类型,确定对所述第三文本令牌特征序列的处理策略。
8、在一个实施例中,所述令牌化模块是指将任意一段文本编码为文本token令牌特征序列。
9、在一个实施例中,所述语音-文本对齐模块,用于完成音频特征序列到文本令牌特征序列的对齐映射。
10、在一个实施例中,对所述第一文本令牌特征序列、所述第二文本令牌特征序列进行拼接处理,获取第三文本令牌特征序列。
11、在一个实施例中,所述提示词类型包括以下至少之一:识别类型、音频输出类型。
12、在一个实施例中,若所述提示词类型为识别类型时,则通过所述语言大模型,对所述第三文本令牌特征序列进行反序列化操作,输出文本回复内容。
13、在一个实施例中,若所述提示词类型为音频输出类型时,则通过所述语言大模型,对所述第三文本令牌特征序列进行处理后,获取第四文本令牌特征序列。
14、在一个实施例中,通过文本-语音对齐模块获取与所述第四文本令牌特征序列对齐的音频特征序列;其中,所述文本-语音对齐模块,用于实现文本令牌特征序列到音频特征序列的对齐映射。
15、在一个实施例中,基于所述对齐的音频特征序列,输出目标语音信息。
16、在一个实施例中,所述语音大模型是指通过大量语音数据训练的深度学习模型,其中,训练方法包括以下至少之一:有监督、自监督、半监督;
17、所述语言大模型是指通过大量文本数据训练的深度学习模型;其中,训练方法包括以下至少之一:有监督、自监督、半监督。
18、在一个实施例中,通过语音大模型提取输入语音的帧级别的高维特征序列作为音频特征序列。
19、在一个实施例中,所述音频特征序列承载了音频内容信息、音频情感信息、音频韵律信息、音频声纹信息、音频场景信息、音频事件信息。
20、在第二方面,本发明提供一种基于大模型的智能交互系统,包括:第一获取模块、对齐模块、第二获取模块、第三获取模块、处理模块;
21、第一获取模块,用于通过语音大模型提取语音信息的音频特征序列并将所述音频特征序列传输至语音-文本对齐模块;
22、对齐模块,用于通过所述语音-文本对齐模块获取与所述音频特征序列对齐的第一文本令牌特征序列;
23、第二获取模块,用于通过令牌化模块获取与输入的提示词文本对应的第二文本令牌特征序列;
24、第三获取模块,用于基于所述第一文本令牌特征序列、所述第二文本令牌特征序列,获取第三文本令牌特征序列;
25、处理模块,用于所述语言大模型基于提示词类型,确定对所述第三文本令牌特征序列的处理策略。
26、在第三方面,提供一种计算机设备,包括处理器和存储装置,其中所述存储器中存储有程序,所述处理器执行所述程序时实现上述方法的技术方案中任一项技术方案所述的基于大模型的智能交互方法。
27、在第四方面,提供一种计算机可读存储介质,存储有程序,所述程序被执行时实现上述方法的技术方案中任一项技术方案所述的基于大模型的智能交互方法。
28、本发明上述一个或多个技术方案,至少具有如下一种或多种有益效果:
29、在实施本发明的技术方案:通过语音大模型提取语音信息的音频特征序列并将所述音频特征序列传输至语音-文本对齐模块;通过所述语音-文本对齐模块获取与所述音频特征序列对齐的第一文本令牌特征序列;通过令牌化模块获取与输入的提示词文本对应的第二文本令牌特征序列;基于所述第一文本令牌特征序列、所述第二文本令牌特征序列,获取第三文本令牌特征序列;所述语言大模型基于提示词类型,确定对所述第三文本令牌特征序列的处理策略。通过语音大模型对语音信息的提取,保留了更高层的语义,同时,通过语音-文本对齐模块获取音频特征序列对齐的第一文本令牌特征序列,使得语言大模型处理时可以获取更底层的细腻的语音特性,更好地识别用户意图,提高用户人机交互的体验。
30、进一步地,本方案可跳过asr的识别结果、tts文本前端转换等中间结果,不再受限于这两个模块的准确度,直接进行端到端的语音-语音的交互,整体提升交互的效果。
31、进一步地,可通过不同的prompt文本(提示词),本技术的端到端多模态人机交互系统,可同时进行单模态的文本交互、asr语音识别、声纹识别、情绪识别等任务,使得nlp文本和speech语音两个模态的任务在本系统框架下得到统一。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23106.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表