可感知混响特性的深度网络驱动麦克风阵列语音增强方法
- 国知局
- 2024-06-21 11:43:08
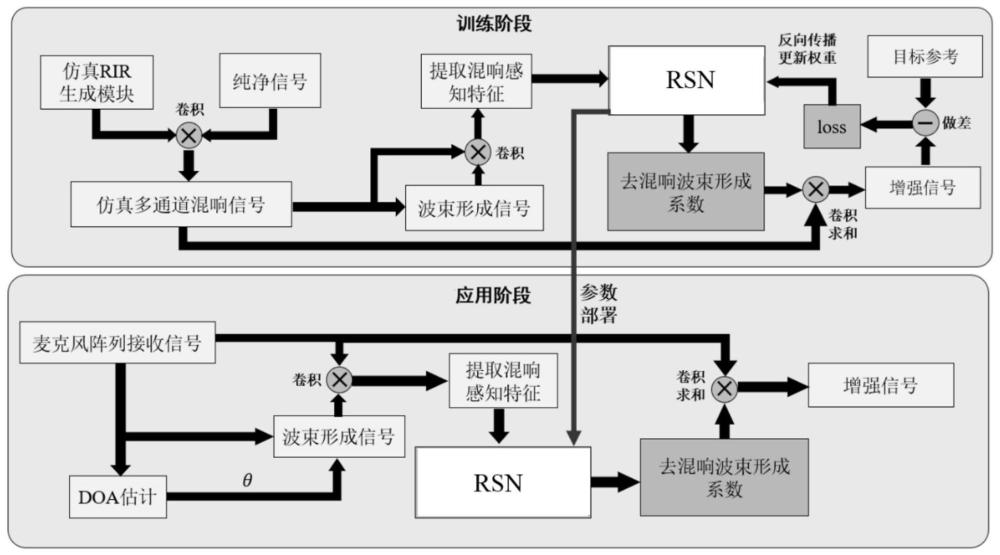
本发明属于语音增强算法,具体涉及一种可感知混响特性的深度网络驱动麦克风阵列语音增强方法及装置。
背景技术:
1、随着5g、物联网及人工智能的快速发展,语音成为各类智能化终端、设备的主流人机交互入口,广泛应用于智能家居、可穿戴设备、线上会议、智能交互机器人等领域。但是,随着语音技术应用环境变得复杂多样,混响和噪声等严重影响语音质量,对智能语音技术提出了更高的要求。面向复杂、多变的语音应用场景,传统麦克风阵列语音增强算法效果有限;引入机器学习(深度学习)的数据驱动麦克风阵列优化模型可获得明显的性能提升,但此类方法具有数据依赖性,在变化的实际环境下模型与环境不匹配导致效果变差、甚至失效。
2、yang等人提出一种基于mclp的去混响双线性形式方法,用空间滤波器和时间滤波器的kronecker积。表示mclp滤波器,在此基础上与递归最小二乘(recursive leastsquares,rls)结合,推导出了一种的自适应语音去混响算法。与原始的基于mclp的自适应算法相比,计算复杂度显著降低,适合动态场景,对噪声更具鲁棒性;
3、muckenhirn h等人提出一种基于cyclegan的去混响方法,该方法可以在未配对数据上训练去混响模型,通过将所提出的未配对模型与具有相同架构并在相同数据集的配对版本上训练的配对模型进行比较,来量化使用未配对数据训练对模型性能的影响,结果表明未配对模型与配对模型有着相当的性能;
4、nakatani t等人提出一种估计卷积波束形成器的方法,该方法生成的波束形成器可以同时以最优的方式进行去噪和去混响。具体而言,将wpe和mpdr波束形成器(minimum-power distortionless response,mpdr)统一为一个卷积波束形成器,并基于统一优化准则对其进行优化。该方法有机地将wpe和波束形成相结合,效果远优于大部分传统算法;
5、通常基于神经网络的语音增强算法是在匹配数据上训练的,这种方法的主要限制是,模型需要在大量数据和各种房间脉冲响应上进行训练,因为获取真正的匹配数据成本巨大,当模型与数据失配时效果将大打折扣。模型与数据失配的首要因素就是混响,训练集无法穷尽所有的室内混响模式,实际的室内混响也各不相同,导致语音增强不佳。
6、针对深度学习等智能算法训练模型与实际条件不适配而导致效果不佳的问题,通常的解决方法在于扩增数据集、扩大神经网络规模来提高模型泛化能力,诚然深度学习可以自动提取学习数据中的深层特征,但是这是需要大模型、大数据的支持,仅能在服务器端进行运算处理,且深度学习本身可视为黑箱模型,对于网络自动提取的特征缺乏可解释性。
7、wang z q等人提出一种双dnn+前向卷积预测(forward convolutiveprediction,fcp)的架构来实现单通道语音的混响抑制和语音分离。该方法通过感知房间混响特性并输入模型具备对环境混响特性的适用能力,首先使用一个dnn通过复数谱映射来估计目标扬声器的直达声信号,然后利用估计的直达声通过fcp滤波器逼近原始混响信号,通过fcp滤波器获得房间冲激响应(room impulse response,rir)的估计,最后将fcp滤波器混响信息与第一个dnn输出的直达声估计一起送入第二个dnn网络实现更好的去混响效果。但该方法采用两个dnn网络进行处理,运算复杂度高,无法在现场硬件工程实现。
8、有鉴于此,提出一种可感知混响特性的深度网络驱动麦克风阵列语音增强方法及装置是非常具有意义的。
技术实现思路
1、为了解决现有技术中存在的问题,本发明提供一种可感知混响特性的深度网络驱动麦克风阵列语音增强方法及装置,以解决上述存在的技术缺陷问题。
2、第一方面,本发明提出了一种可感知混响特性的深度网络驱动麦克风阵列语音增强方法,该方法包括如下步骤:
3、训练步骤,训练混响感知网络rsn使其拥有根据混响特征解耦生成去混响波束形成系数的能力;
4、驱动步骤,将训练得到的网络模型参数部署到实现系统或者终端硬件侧,在获得目标声源方向后,对麦阵实时接收到的信号进行不同环境下混响感知bcc特征提取,将部署完成训练的rsn网络模型并生成对应不同环境的去混响波束形成系数,所述去混响波束形成系数以卷积运算的方式作用于原始信号上得到抗混响增强信号。
5、优选的,训练步骤具体包括:
6、采用本领域通用的image方法生成多种室内rir混响模型,通过纯净语音与模拟rir进行卷积得到多通道的模拟混响信号,通过混响感知获得携带环境混响和空域信息的波束互相关特征bcc,输入可感知混响特性的网络模型进行训练,网络模型在训练中通过输出多通道的去混响波束形成系数与目标参考相减获得误差进行网络参数迭代,在完成网络模型训练后保存网络模型参数。
7、进一步优选的,训练步骤还包括训练特征提取:
8、将多通道麦克风接收信号与单通道波束形成信号之间的互相关结果定义为波束互相关特征bcc,其表征当前环境的近似房间冲激响应,bcc特征定义如下:
9、
10、其中,ybf(n,θ0)为对准θ0方向的波束形成增强信号,xm(n)为第m通道的原始信号;
11、提取各通道bcc特征的峰值处以及向前后扩展点的相关值,扩展的点数根据实际需要确定,取的点数越多其包含的混响和空域信息则越多,对于一个直径为d,m元的圆阵,扩展点数不得少于n:
12、
13、其中fs是采样率,c是声音在空气中的传播速度;则对于每一通道特征表示为:
14、hm=[bccm(i-n),…,bccm(i),…,bccm(i+n)]
15、其中i表示的是最大值的索引;
16、提取的bcc特征维度为(m,2n+1),最终将bcc矩阵展平成一维向量hr送入rsn网络:
17、hr=[h1,h2,…,hm]。
18、进一步优选的,还包括:
19、所述混响感知网络rsn模型采用标准的dnn网络模型框架,分为输入层、隐藏层和输出层;
20、对原始麦阵信号提取bcc特征展平成一维特征向量hr送入神经网络;
21、隐藏层采用双层的全连接层,网络的输出为期望方向的去混响波束形成系数hbf,即训练目标;
22、网络输出的维度是(m×l),其中m为阵元个数,l为每个通道的系数阶数;将输出结果作为卷积核参数与原始多通道信号进行卷积操作得到增强信号yout(n),并与目标参考信号ytarget(n)在时域上求损失,之后进行梯度运算和反向传播。
23、进一步优选的,还包括通过rsn训练出匹配不同混响程度的各个方向的去混响波束形成系数,期望的波束模型根据实际情况手动调节参数来训练,具体包括:
24、根据期望波束设计模型来构造不同角度来波的目标信号,假设训练波束方向为麦阵实际来波方向为θ,则两者存在一个角度差δθ为:
25、
26、根据角度差δθ对参考信号的幅度进行加权控制,设计出不同非目标方向空域谱衰减的效果,其中,ωd(δθ)为角度差δθ情况下对参考目标信号进行幅度调节的系数;
27、通过上述加权操作来构建标签集,根据训练目标,模型采用本领域通用的mse作为训练的损失函数:
28、
29、其中yout(n)为增强的单通道输出信号,ytarget(n)为幅度控制权重后的目标信号,lall为样本总数。
30、进一步优选的,驱动步骤具体包括混响感知深度网络驱动去混响波束形成:
31、将训练过程完成训练的rsn网络部署到实际应用系统中;
32、在不同使用环境下,麦阵接收到信号在利用本领域通用的doa估计方法估计出目标声源方向后,对该方向形成波束;
33、将波束形成信号与原始多通道信号根据bcc特征定义计算获得对应不同使用环境的bcc近似冲激响应;
34、选择合适的点数对多通道bcc进行降维得到一维特征向量hr,再送入已完成训练的rsn网络模型进行前向传播运算,输出对应不同使用环境的多通道去混响波束形成系数hbf,并将hbf与原始多通道信号进行卷积运算,以深度网络驱动的方式进行去混响波束形成语音增强。
35、进一步优选的,还包括采集数据集:
36、基于本领域通用的image混响模型方法,使用rir_generator工具来构造不同混响程度的房间脉冲响应,通过将原始纯净语料库中的语音通过与房间脉冲响应进行卷积得到不同混响程度的语音信号来模拟麦阵多通道原始接收信号;
37、将空间分为24个子空间,以0°方向系数,生成混响时间为0.1~1s,间隔0.1s共10种房间脉冲响应在,作为训练集样本。
38、进一步优选的,还包括设置模型参数:
39、两层隐藏层神经元个数分别设置为256和512,激活函数采用relu;
40、设置输入特征向量hr维度为1×66,输出维度为6×64,即每一个通道的滤波器系数为64阶;
41、训练次数epoch设置为300,批处理大小batch_size设置为24,采用adma优化器,学习率learning_rate采用指数型衰减,初始设置为0.001,衰减率为0.98;
42、网络中神经网络的权重采用零均值,方差为0.01的正态分布进行初始化。
43、第二方面,本发明实施例还提供了一种可感知混响特性的深度网络驱动麦克风阵列语音增强装置,包括:
44、训练模块,配置用于训练混响感知网络rsn使其拥有根据混响特征解耦生成去混响波束形成系数的能力;
45、驱动模块,配置用于将训练得到的网络模型参数部署到实现系统或者终端硬件侧,在获得目标声源方向后,对麦阵实时接收到的信号进行不同环境下混响感知bcc特征提取,将部署完成训练的rsn网络模型并生成对应不同环境的去混响波束形成系数,所述去混响波束形成系数以卷积运算的方式作用于原始信号上得到抗混响增强信号。
46、与现有技术相比,本发明的有益成果在于:
47、(1)本发明公开了一种可感知混响特性的深度网络驱动麦克风阵列语音增强方法及装置,该方法在训练阶段通过感知环境混响特性并输入深度网络进行训练获得深度优化网络模型参数,在实际应用阶段将感知的环境混响特性输入完成训练的深度网络模型生成抗混响波束形成系数,从而以深度网络驱动而非深度网络直接运行的方式通过其生成的抗混响波束形成系数进行抗混响语音增强处理。
48、(2)本发明提出一种可感知混响特性的深度网络驱动麦克风阵列语音增强方法及装置,本发明提出的rsn方法相较于fsb算法有着更好的波束表现,语音增强效果也普遍强于fsb;虽然rsn方法增强效果不如rnnoise和dccrn算法,但是其在降噪的同时对语音损伤较小,且由于感知混响对不同环境的适应能力更强,因此在提升听感和语音识别率上效果显著。
49、(3)本发明的方法在现场硬件端不涉及深度网络模型的训练和直接运行,即具有计算高复杂度和存储资源需求的深度网络模型训练可在具有强大运算能力支撑的后端事先完成,并不在现场硬件端运行,而是直接调用前述第一个步骤中已完成训练的网络模型参数,以不同环境下实时混响感知bcc特征作为输入生成对应不同环境的去混响波束形成系数,从而以深度网络驱动的方式进行抗混响语音增强处理,因而计算复杂度低,易于在移动硬件平台部署并实时增强麦阵语音信号。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23112.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表