一种基于文本情感的中文情感语音合成方法、系统、设备及介质
- 国知局
- 2024-06-21 11:43:28
本发明涉及文本分析和情感语音合成,特别涉及一种基于文本情感的中文情感语音合成方法、系统、设备及介质。
背景技术:
1、随着人工智能和深度学习技术的快速发展,情感语音合成已经逐渐成为人工智能生成领域的一个重要研究方向。情感语音合成在诸多领域有丰富的研究场景和现实意义,例如,在人机交互层面,情感语音合成可以增强人机交互体验,使计算机具备更加智能和亲近的特性,使用户感受到更真实、亲切的沟通体验;在教育与培训方面,情感语音合成可以应用于语言学习、演讲训练等领域,帮助学习者更好地理解、模仿和传达情感,提高学习效果;在医疗领域,情感语音合成可以用于帮助那些失去声音的人或喉癌患者通过计算机来表达情感,提高他们的生活质量;在游戏、虚拟现实和动画等娱乐领域,情感语音合成可以为角色赋予更加逼真的情感表达,增强用户的沉浸感和情感共鸣。然而,现有情感语音合成技术仍存在着诸多挑战和不足,例如如何提高生成文本的准确性和情感表达的逼真度,在合成语言中实现贴近人类情感语音细腻度的情感细节;以及如何在无人工干预的情况下使得合成语音情感与文本内容匹配。
2、公开号为cn116402059a的专利申请,公开了一种基于dualgcn的文本情感分析方法,具体包括:首先对文本进行预处理,使用预训练的glove词嵌入,利用bert作为encoder来挖掘句子的隐藏状态向量,利用生成树提供的短语级语法结构和依赖树从句语法结构的信息。最后通过语法模块和语义模块的信息交流,由softmax来输出分类结果。该方法利用了语法结构的信息,缓解了gcn容易出现的过度平滑现象,能有效提高分类的精度。
3、公开号为cn115578998a的专利申请,公开了一种语音合成方法、电子设备和存储介质,该方法具体内容如下:通过预先将多种情感声学特征经由参考编码模块得到的多种情感嵌入向量和类别标识存入预先训练完成的声学模型中,在推理阶段将目标文本和情感参数输入至声学模型,查找到目标情感嵌入向量与经由文本编码模块获取的目标文本嵌入向量进行融合,然后将融合所得向量转换为目标声学特征向量,目标声学特征向量再经由声码器最后得到目标音频信息。
4、但是,现有情感语音合成技术存在以下问题:
5、(1)目前的情感语音合成技术尚存在准确性不足的问题。虽然情感语音合成模型可以在一定程度上表达不同情感,但在捕捉情感的细微差异方面还存在限制。现有模型主要通过情感编码器来建模整体的情感风格,却难以在情感种类和强度方面进行精细调节。这使得合成语音在表达情感时显得不够自然和真实,难以准确地反映人类语音中微妙的情感变化。因此,需要进一步的研究来改进情感语音合成技术,以更好地捕捉和表达情感的多样性和复杂性;
6、(2)目前的情感语音合成技术尚存在语音情感与内容的不协调的问题。合成语音的情感通常是人工指定的,无法根据不同的文本内容自动产生相应的情感语音。为了实现与文本内容相匹配的情感语音合成,需要结合文本情感分析技术。目前,中文情感分析领域已经涌现出许多表现优秀的算法模型,然而,将这些技术与情感语音合成方法相融合的应用仍然存在较大的空白。
技术实现思路
1、为了克服上述现有技术的缺点,本发明的目的在于提供一种基于文本情感的中文情感语音合成方法、系统、设备及介质,通过基于变分自动编码器的风格生成模型从输入音频中学习情感风格,通过中文情感分析模块获取输入内容的情感权重向量,同时在情感嵌入获取模块增加输入通道,利用变分自动编码器的特性,结合情感权重微调融合情感风格特征,将特征序列和文本序列输入端到端语音合成模型,提升了模型整体的情感细节建模能力和文本情感关联性,提高了合成语音的情感表现力。
2、为了实现上述目的,本发明采取的技术方案如下:
3、一种基于文本情感的中文情感语音合成方法,包括如下步骤:
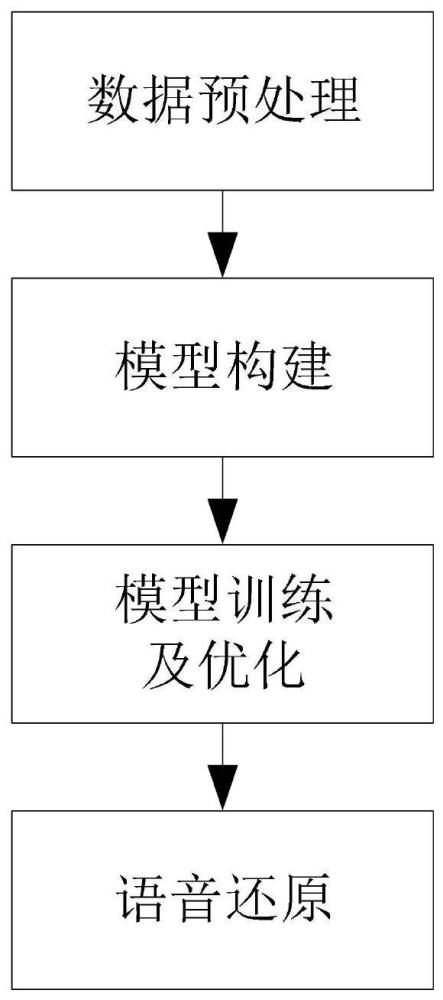
4、步骤1,数据预处理:获取情感语音数据,对情感语音数据进行预处理,利用预处理后的情感语音数据构建完备情感语音数据集,所述完备情感语音数据集中的数据包括情感语音文本信息、情感类别信息和情感语音声学特征;获取中文情感文本数据,对中文情感文本数据进行预处理,利用预处理后的中文情感文本数据构建完备情感文本数据集,所述完备情感文本数据集中的数据包括中文情感文本信息和情感类别信息;
5、步骤2,模型构建:构建基于文本情感的中文情感语音合成模型,所述基于文本情感的中文情感语音合成模型包括中文情感分析模型、风格生成模型和端到端语音合成模型;
6、步骤3,模型训练及优化:将步骤1完备情感文本数据集中的中文情感文本信息和情感类别信息转换为音素序列和情感数值标签,将中文情感文本信息和情感语音声学特征输入步骤2构建的中文情感分析模型中,训练并优化中文情感分析模型,得到目标文本的情感权重向量;将步骤1完备情感语音数据集中的情感语音文本信息与情感语音声学特征通过输入处理,转化为音素序列和音频梅尔频谱声学特征,将情感语音文本信息和音频梅尔频谱声学特征输入步骤2构建的风格生成模型和端到端语音合成模型,并对风格生成模型和端到端语音合成模型同时训练优化,得到目标合成语音的梅尔频谱声学特征;
7、步骤4,语音还原:利用waveglow声码器处理步骤3得到的梅尔频谱声学特征,并将特征序列还原为情感语音。
8、所述步骤1中情感语音数据预处理的具体过程为:
9、步骤1.1.1:对情感语音数据的音频进行采样率校验,将所有输入音频的采样率强制转换为目标采样率;
10、步骤1.1.2:对步骤1.1.1中转换为目标采样率后的音频进行降噪和能量归一化处理,并对音频内容和情感种类进行标注,得到完备情感语音数据集,所述完备情感语音数据集中的数据包括情感语音文本信息、情感类别信息和情感语音声学特征;
11、步骤1.1.3:将步骤1.1.2得到的完备情感语音数据集中的数据划分为训练集、测试集和验证集。
12、所述步骤1中中文情感文本数据预处理的具体过程为:
13、步骤1.2.1:文本清洗,去除中文情感文本数据的特殊字符、标点符号、html标签、无关的空格,同时处理缩写词和拼写错误;
14、步骤1.2.2:将步骤1.2.1处理后的中文情感文本数据的情感标签映射为数值形式,将文本分割成词序列,得到完备情感文本数据集,所述完备情感文本数据集中的数据包括中文情感文本信息和情感类别信息;
15、步骤1.2.3:将步骤1.2.2得到的完备情感文本数据集中的数据划分为训练集、测试集和验证集。
16、所述步骤2中的中文情感分析模型用于从情感语音文本信息中得到目标文本的情感权重向量;
17、所述步骤2中的风格生成模型用于实现输入声学特征到情感风格向量的转换,包括情感嵌入获取模块和情感嵌入微调模块;
18、情感嵌入获取模块:用于实现从输入声学特征中获取单一情感的原始嵌入信息;
19、情感嵌入微调模块:利用变分自动编码的解缠结、可组合缩放的特性,通过中文情感分析得到的情感权重对多种单一情感的原始嵌入信息进行组合,实现情感强度控制和多情感融合;
20、所述步骤2中端到端语音合成模型以tacotron2算法为基础,包括编码器模块,解码器模块和注意力机制模块;
21、编码器模块:用于接收语音嵌入信息并提取特征;
22、解码器模块:用于将编码特征输出成目标语音;
23、注意力机制模块:用于对齐输入文本与输出语音的对应关系,帮助模型在生成语音时关注与当前输出帧最相关的文本部分。
24、所述步骤3中训练并优化中文情感分析模型的具体过程为:
25、步骤3.1.1:指定输出文件的保存路径,并设置随机种子;
26、步骤3.1.2:将步骤1.2.3完备情感文本数据集中的训练集输入步骤2构建的风格生成模型,在每个训练周期内,遍历训练集的每个批次,使用中文情感分析模型预测输出和计算损失,计算损失对中文情感分析模型参数的梯度,对梯度进行裁剪,更新模型参数,并计算训练批次的准确率;
27、步骤3.1.3:在每个训练周期结束后,中文情感分析模型进入验证模式,使用验证集进行评估,计算验证数据的损失、输出和准确率,得到目标文本的情感权重向量;
28、所述步骤3.1.2与步骤3.1.3中的损失为交叉熵损失,损失函数为:
29、
30、式中,n表示总情感类别数,yij表示情感类别的真实分布,表示模型预测情感类别的分布,其中0≤i≤n,0≤j≤batch_size。
31、所述步骤3中训练并优化风格生成模型和端到端语音合成模型的具体过程为:
32、步骤3.2.1:将步骤1.1.3完备情感语音数据集中训练集的情感语音文本信息经过文本嵌入层,得到文本嵌入向量,并进行维度转置,将转置后的文本嵌入向量通过步骤2端到端语音合成模型的编码器模块得到编码的文本特征;
33、步骤3.2.2:将步骤1.1.3训练集中的情感语音声学特征输入步骤2的风格生成模型对目标语音进行编码得到情感风格特征;
34、步骤3.2.3:将步骤3.2.1获得的文本特征和步骤3.2.2获得的情感风格特征输入步骤2端到端语音合成模型中的解码器模块,对端到端语音合成模型进行训练优化,得到目标合成语音的梅尔频谱声学特征和对齐信息;
35、所述步骤3.2.3训练优化过程中的损失函数为重构损失与kl散度损失的叠加,具体为:
36、loss=fkl-anneal*kl[qφ(z|x)||pθ(z)]+lossrec
37、式中,fkl-anneal为kl散度损失的退火函数,即kl散度损失的可变权重,训练开始时权重接近于零,然后逐渐增加;loss为重构损失;z为情感风格嵌入;
38、rec x为情感语音的特征序列;qφ(z|x)为识别模型;pθ(z)为情感风格嵌入的先验概率;
39、所述lossrec为重构损失,具体为:
40、
41、式中,lstop为停止标记损失;z为情感风格嵌入;t为输入文本;pθ(x|z,t)为以t为条件的后验概率密度函数;
42、所述kl散度损失的退火函数fkl-anneal具体为:
43、
44、式中,p表示权重上界限,x0表示步数间隔,r为系数。
45、所述步骤4的具体过程为:
46、步骤4.1:对waveglow声码器进行初始化,设置合成音频采样率,使合成音频采样率与步骤1.1.1中目标采样率匹配;
47、步骤4.2:加载语音合成模块和waveglow声码器的参数,并将其设置为可用状态;
48、步骤4.3:通过合成方法合成音频,确定waveglow声码器的输入为文本输入、输出路径和情感比例,在生成过程中,使用端到端语音合成模型编码输入序列,并根据条件计算风格向量;
49、步骤4.4:使用步骤4.3设置完成的waveglow声码器将步骤3.2.3生成的梅尔频谱声学特征转换为情感语音,并将生成的情感语音保存到指定的输出路径。
50、一种基于文本情感的中文情感语音合成系统,包括:
51、数据预处理模块:获取情感语音数据,对情感语音数据进行预处理,利用预处理后的情感语音数据构建完备情感语音数据集,所述完备情感语音数据集中的数据包括情感语音文本信息、情感类别信息和情感语音声学特征;获取中文情感文本数据,对中文情感文本数据进行预处理,利用预处理后的中文情感文本数据构建完备情感文本数据集,所述完备情感文本数据集中的数据包括中文情感文本信息和情感类别信息;
52、模型构建模块:构建基于文本情感的中文情感语音合成模型,所述基于文本情感的中文情感语音合成模型包括中文情感分析模型、风格生成模型和端到端语音合成模型;
53、模型训练及优化模块:将数据预处理模块中完备情感文本数据集中的中文情感文本信息和情感类别信息转换为音素序列和情感数值标签,将中文情感文本信息和情感语音声学特征输入模型构建模块构建的中文情感分析模型中,训练并优化中文情感分析模型,得到目标文本的情感权重向量;将数据预处理模块中完备情感语音数据集中的情感语音文本信息与情感语音声学特征通过输入处理,转化为音素序列和音频梅尔频谱声学特征,将情感语音文本信息和音频梅尔频谱声学特征输入模型构建模块构建的风格生成模型和端到端语音合成模型,并对风格生成模型和端到端语音合成模型同时训练优化,得到目标合成语音的梅尔频谱声学特征;
54、语音还原模块:利用waveglow声码器处理步骤3得到的梅尔频谱声学特征,并将特征序列还原为情感语音。
55、一种基于文本情感的中文情感语音合成设备,包括:
56、存储器:用于存储实现所述的一种基于文本情感的中文情感语音合成方法的计算机程序;
57、处理器:用于执行所述计算机程序时实现所述的一种基于文本情感的中文情感语音合成方法。
58、一种计算机可读存储介质:
59、所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时能够实现一种基于文本情感的中文情感语音合成方法。
60、相对于现有技术,本发明的有益效果在于:
61、1、本发明通过步骤2所构建的中文情感语音合成模型的输入通道,相较于现有方法,增加了直接利用中文情感分析模型进行文本情感分析通道,能够实现直接从文本中获取情感种类或情感细节,从而规避了人工干预指定情感种类的操作,减少了实际应用中的操作复杂性,提高了系统整体效率,同时新通道的引入使得系统更加灵活,能够适应不同类型和风格的输入文本。
62、2、本发明通过步骤2中同时训练和优化风格生成模型和端到端语音合成模型这两个关键模型,使它们能够更好地协同工作,相较于现有技术先训练局部模型的策略,这一步能够推动模型整体性能的提升,使得两个模型能够相互调整,以更好地适应彼此的输出,从而创造出更为令人满意和逼真的情感语音合成结果。提高了模型的整体性能。
63、3、本发明提供了一种改进情感语音合成技术的方法,旨在解决现有技术在捕捉情感细微差异和多样性方面的不足,通过引入新的情感建模策略,本技术能够精细调节情感种类和强度,从而使合成语音更加自然、真实,并准确地反映人类语音中微妙的情感变化,与现有技术相比,本发明有助于提升情感语音合成技术在多领域的应用,包括语音助手、媒体内容制作等,为用户提供更为丰富和准确的情感表达体验。
64、4、本发明在情感语音合成领域引入了文本情感分析技术,以实现情感语音与文本内容的协调性增强,通过将先进的中文情感分析算法模型与情感语音合成方法相融合,与现有技术相比,本发明能够根据不同的文本内容自动产生相应的情感语音,从而消除了语音情感与内容不协调的问题,提升了情感语音合成的逼真程度和应用价值,为语音广告、情感交流等领域提供了更加精准和有感染力的情感表达工具。
65、综上所述,与现有技术相比,本发明能够准确捕捉和表达情感的细微差异和多样性,从而增强了合成语音的自然度和真实感;同时,本发明引入了中文情感分析算法模型,实现了情感语音与文本内容的协调性增强,使得合成语音能够根据不同文本内容自动产生相应情感,消除了情感与内容不协调的问题。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23132.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。