基于语音和语义的多模态语音唤醒识别方法及系统与流程
- 国知局
- 2024-06-21 11:44:34
本技术涉及信息,具体涉及一种基于语音和语义的多模态语音唤醒识别方法及系统。
背景技术:
1、近年来,互联网技术飞速发展,带来了全球共享的技术革命时代,人们的生活也在朝着更快节奏的方向发展。计算机、手机及其一些其他嵌入式设备则是承载着这种变革的重要工具,人们通过这些设备进行工作、交流以及娱乐等,互联网日渐影响到人们生活的方方面面。随着人工智能的飞速发展,市场上推出了各式各样的智能设备,ai语音的发展更是使得语音助手成为各大智能终端设备必不可少的嵌入式软件。语音交互使用的是人类直接的表达方式——语言,不需要和实物接触,可远程操控,对于人们来说是最方便自然的交流方式。自动语音识别(automatic speech recognition,asr)是一种将语音转化为文字的技术,是人与机器、人与人自然交流的关键技术之一。
2、语音唤醒是语音识别的入口,如何高效、准确地对用户指令给出反应成为这一技术的最重要的目标。语音唤醒技术的用途在于用户可以完全用语音对设备进行操作,脱离了双手的帮助;同时,利用唤醒机制,设备不需要一直保持工作模式,可以很大程度上减小设备的功耗。语音唤醒和语音识别的不同之处在于语音识别只处理某一段语音数据,待识别的语音段具有明确的开始和结束,语音唤醒则是对连续不断的语音流的处理,需要不间断地检测从麦克录到的语音中是否包含关键词信息。语音唤醒不需要对非关键词进行精确的识别,只需要负责检测出目标关键词即可,语音唤醒的核心任务就是将关键词从语音中识别、检测出来,从而激发、唤醒相应设备。
3、与语音识别相比,语音唤醒简单来理解可以认为是一个持续在线的单一关键词搜索任务。语音唤醒具有极其苛刻的唤醒率和误唤醒率要求。语音唤醒的实现框架可以分成语音信号预处理、特征提取、语音唤醒分类模型训练三个部分。语音信号如果想在神经网络中处理,需要先进行预处理,输入是一维的声音序列,对应到每个时间点,是信号的强度。通过处理之后,会产生一个二维的m乘n矩阵,m是每一帧能拿到的特征维度,n对应到每一帧是时间维度。单语音模型的输入只有用户的语音,语音加语义模型会把用户的语音和文本以及其他的一些语义特征,都输入到模型中去,语音加语义的模型效果在单语音特征的基础上加入了高维的语义特征信息,对神经网络和解码处理过程中的语音唤醒的准确率和误报率降低具有重要意义。
4、现有技术中,主要依赖单纯的唤醒语音的语音特征进行语音唤醒识别,在针对说话人带口音或环境噪声等实际应用场景中存在识别准确率不高和容易误激活的技术问题。
技术实现思路
1、本技术提供一种基于语音和语义的多模态语音唤醒识别方法及系统,可以解决现有技术中针对说话人带口音或环境噪声等实际应用场景语音交互存在的语音唤醒准确率不高和容易误激活的技术问题。
2、第一方面,本技术提供了一种基于语音和语义的多模态语音唤醒识别方法,包括以下步骤:
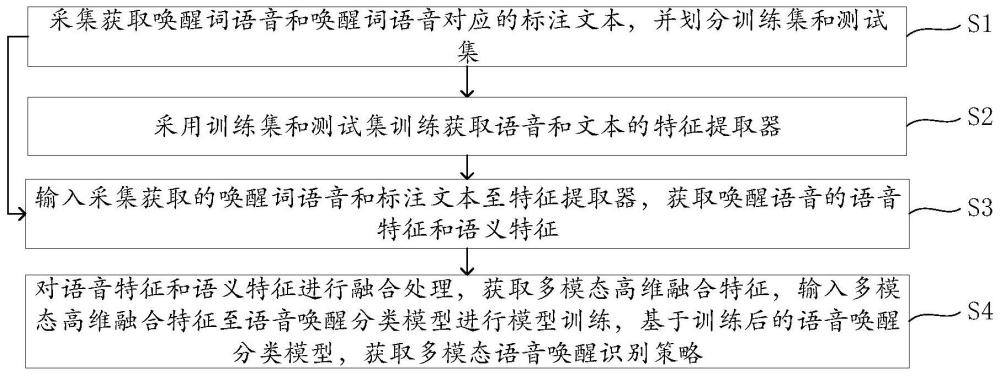
3、采集获取唤醒词语音和唤醒词语音对应的标注文本,并划分训练集和测试集;
4、采用训练集和测试集训练获取语音和文本的特征提取器;
5、输入采集获取的唤醒词语音和标注文本至特征提取器,获取唤醒语音的语音特征和语义特征;
6、对语音特征和语义特征进行融合处理,获取多模态高维融合特征,输入多模态高维融合特征至语音唤醒分类模型进行模型训练,基于训练后的语音唤醒分类模型,获取多模态语音唤醒识别策略。
7、结合第一方面,在一种实施方式中,所述采用训练集和测试集训练获取语音和文本的特征提取器步骤,具体包括以下步骤:
8、语音信号以mfcc特征作为输入,语义信号以唤醒词的字符特征作为输入,利用conformer+transformer模型进行语音和语义多模态目标训练,训练过程中计算获取语音信号损失和语音信息损失,使用目标函数损失最小化准则,分别使损失达到最优,获取训练后的conformer+transformer模型。
9、结合第一方面,在一种实施方式中,所述输入采集获取的唤醒词语音和标注文本至特征提取器,获取唤醒语音的语音特征和语义特征步骤,具体包括以下步骤:
10、输入唤醒词语音和标注文本至训练后的conformer+transformer模型的encoder部分,提取唤醒词的语音信号高维特征和语义信号高维特征。
11、结合第一方面,在一种实施方式中,所述对语音特征和语义特征进行融合处理,获取多模态高维融合特征,输入多模态高维融合特征至语音唤醒分类模型进行模型训练,基于训练后的语音唤醒分类模型,获取多模态语音唤醒识别策略步骤,具体包括以下步骤:
12、对获取的语音信号高维特征和语义信号高维特征进行多模态高位特征融合处理,获取语音唤醒词的多模态高维融合特征;
13、输入多模态高维融合特征至二分类softmax模型,训练语音唤醒分类模型,训练过程采用语音和唤醒词联合训练方法,获取训练后的语音唤醒分类模型;
14、基于获取的训练后的语音唤醒分类模型,获取唤醒词的唤醒概率。
15、结合第一方面,在一种实施方式中,所述融合处理包括但不限于线性拼接、加权求和以及基于注意力机制attention的融合办法。
16、结合第一方面,在一种实施方式中,所述多模态高维融合特征中唤醒语音和唤醒词一一对应为正样本,唤醒语音和唤醒词没有一一对应则为负样本。
17、第二方面,本技术提供了一种基于语音和语义的多模态语音唤醒识别系统,包括:
18、唤醒词获取模块,采集获取唤醒词语音和唤醒词语音对应的标注文本,并划分训练集和测试集;
19、特征提取器训练模块,与所述唤醒词获取模块通信连接,用于采用训练集和测试集训练获取语音和文本的特征提取器;
20、特征获取模块,与所述唤醒词获取模块和所述特征提取器训练模块通信连接,用于输入采集获取的唤醒词语音和标注文本至特征提取器,获取唤醒语音的语音特征和语义特征;
21、唤醒识别模块,与所述特征获取模块通信连接,用于对语音特征和语义特征进行融合处理,获取多模态高维融合特征,输入多模态高维融合特征至语音唤醒分类模型进行模型训练,基于训练后的语音唤醒分类模型,获取多模态语音唤醒识别策略。
22、结合第二方面,在一种实施方式中,所述唤醒识别模块包括:
23、特征融合单元,与所述特征获取模块通信连接,用于对获取的语音信号高维特征和语义信号高维特征进行多模态高位特征融合处理,获取语音唤醒词的多模态高维融合特征;
24、语音唤醒分类单元,与所述特征融合单元通信连接,用于输入多模态高维融合特征至二分类softmax模型,训练语音唤醒分类模型,训练过程采用语音和唤醒词联合训练方法,获取训练后的语音唤醒分类模型;
25、唤醒概率获取模块,与所述语音唤醒分类模型通信连接,用于基于获取的训练后的语音唤醒分类模型,获取唤醒词的唤醒概率。
26、本技术实施例提供的技术方案带来的有益效果至少包括:
27、本技术提供的一种基于语音和语义的多模态语音唤醒识别方法,训练获取特征提取器和语音唤醒分类模型,在单语音特征的基础上加入了高维的语义特征信息,有利于提升神经网络和解码处理过程中语音唤醒的准确率,降低误报率。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23281.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。