一种基于语音识别的考评方法和系统与流程
- 国知局
- 2024-06-21 11:44:55
本发明涉及语音识别领域,尤其是一种基于语音识别的考评方法和系统。
背景技术:
1、由于电力行业作业人员要经常涉及到对各种电力设施设备的操作,一旦操作不当发生事故往往都是致人重伤或死亡的重大安全事故。因此对电力行业相关作业制定了安全行为规范,要求相关作业人员定期参加安全规范作业考评。对未通过考评的员工,会暂时吊销其上岗资格,待其重新参加安全规范作业培训并重新通过考评后才能重新上岗,用此机制帮助提高作业人员的安全意识。考评中通常会有一个监考员全程陪伴,负责给考生打分并监护考试期间的人员安全。考评中操作项众多,除了考生必须按照相应规范完成这些操作以外,在每个操作前后考生必须口述操作注意事项及操作结果,这些口述也是纳入考评的打分点的。但由于实际考试中,无法做到所有操作都是完全按照评分表中的顺序执行的,监考员也要时刻监护考生的安全,往往会造成误打分和漏打分。随着人工智能深度学习的发展,尤其是语音识别方面取得的重大进展,通过计算机将语音音频转写成文字成为了可能。然而在嘈杂环境中和带有严重口音的普通话语音识别及语音考点的自动匹配打分环节上还有不少细节上的难点,技术也在不断迭代更新。
2、专利cn103258534a《语音命令识别方法和电子装置》公开了一种语音命令识别方法,其特征在于,包括:从浏览文件的多个与命令相关的文本字符串中选择多个候选文本字符串;为每个候选文本字符串准备候选语音字符串;接收语音命令;从多个候选语音字符串中搜索匹配所述语音命令的目标语音字符串,其中所述目标语音字符串对应与所述多个候选文本字符串中的目标文本字符串;以及执行与所述目标文本字符串相关的命令。
3、该专利中的语音字符串提供者其实就是把候选文本字符串逐字转成对应的语音单元(可以为音节或音素)并形成语音字符串,然后将嘴边的麦克风收到的语音信号通过语音识别得到的文本也转换成同样格式的语音字符串。语音识别得到的语音字符串只有在语音字符串提供者提供的候选语音字符串中的其中一条完全相等,才能成功匹配到对应的目标文本字符串。但是在电力行业考评的环境中,考生面前并没有文字提示让他完全按照每个语音考点的关键句来说,所以通过语音识别得到的语音字符串也大概率不会和候选的关键句所对应的语音字符串一致。因此该专利无法应用到电力行业考评环境中。
4、专利cn103456297b《一种语音识别匹配的方法和设备》公开了一种语音识别匹配的方法和设备,其主要内容包括:在确定语音信息转化得到的拼音形式的字符信息后,根据模糊匹配策略,从本地数据库中以拼音和汉字形式存储的字符信息中,对转化得到的字符信息根据拼音进行模糊匹配,将现有技术中采用单一的完全匹配策略扩展至对转化得到的拼音形式的字符信息根据拼音进行模糊匹配,有效地增加了对转化得到的字符信息的语音识别率,进而提高了语音识别技术的效率。
5、该专利先将语音识别结果转化为拼音,先把和数据库中拼音字段数量相同的关键句的拼音做模糊完全匹配,如果满足第一阈值条件则找到匹配的关键句,如果未满足第一阈值条件则进入第二步:将剩下所有数据库中拼音字段数量大于语音识别拼音字段结果数量的关键句进行分词,即每次去除一些拼音使剩下的拼音字段数量与语音识别结果拼音字段数量相等然后做模糊完全匹配;没有匹配到的话再将语音识别拼音字段结果进行分词,降低自身拼音字段数量,然后和数据库中拼音字段数量小于原语音识别拼音字段结果数量的关键句做模糊完全匹配。但是在电力行业考评的环境中,因为操作数量众多,事先存在数据库中的关键句也相应很多,且考生为边操作边口述,语音识别出的结果含义上和目标关键句相同可是整个句子字段长度大概率不同,按此专利的分词方式需要对每个关键句索引都要做一次分词组合,计算复杂度非常高,不能满足考评中实时语音识别匹配的需求。且考生因为有时说话会出现卡顿,因为实时语音识别系统的特性,音频中一旦出现长时间没有语音的特征会自动进行断句,所以经常会把关键句分成2、3句话,这种情况此专利更加无法做关键句匹配。因此该专利无法应用到电力行业考评环境中。
6、因此急需提供一种电力行业考评系统,用于解决电力行业考评中语音打分点只能靠监考人手动打分,导致打分效率低,打分准确率低的问题。
技术实现思路
1、本发明的目的在于解决解决考评中语音打分点只能靠监考人手动打分,导致打分效率低,打分准确率低的问题,提供了一种基于语音识别的考评方法和系统,该系统基于关键词拼音的模糊匹配策略,实现实时对语音识别片段做关键句匹配并打分,基于深度学习的去除噪声及语音识别技术,提高在嘈杂环境下对口音偏重的普通话语音识别的准确性。
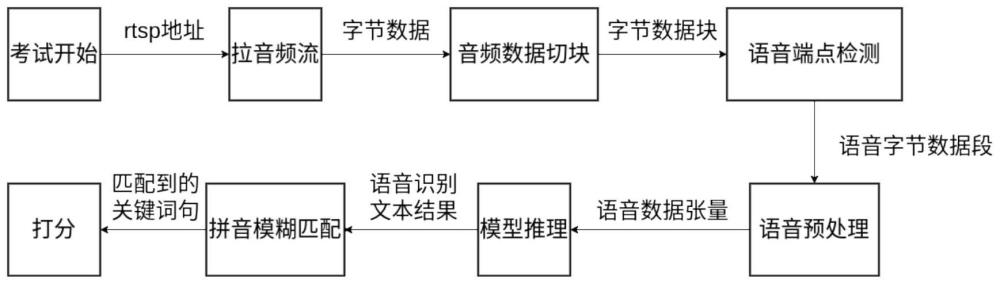
2、为了实现这一目的本发明提供了一种基于语音识别的考评方法包括以下步骤:
3、从软件端接收考试开始信号和拉流地址;
4、拉音频流;
5、将音频数据切块;
6、检测字节数据块的语音端点;
7、对语音字节数据段进行语音预处理;
8、将语音数据张量识别成文本;
9、将语音识别文本结果进行拼音模糊匹配;
10、对匹配到的关键词句进行打分并输出。
11、从软件端接收考试开始信号和拉流地址是通过rabbitmq通信模块的"voice_tipmessage"通信管道运行的,其中"voice_tipmessage"为rabbitmq队列。
12、拉音频流是通过ffmpeg-python拉流模块完成的,其工作流程为:程序在接收到第一个拉流地址后,会将其送入此模块,此模块会根据拉流地址的格式和输入选择,在子进程中做相应的拉流,将编解码器为pcm_s16le,采样率为16000hz,通道数为1这样格式的音频数据以字节方式存入audio_pipe。
13、ffmpeg-python拉流模块的输入源是麦克风时,设置audio_pipe为none;然后再用rnnoise模型对获得的音频进行去噪。
14、音频数据切块是在pyaudio音频数据切块模块中完成的,其流程为:设置pyaudio的音频流,用callback()函数实时取出audio_pipe中的数据,按照每秒50个块,每个块包含320个图文框的方式切块,然后送入audio_queue。
15、检测字节数据块的语音端点是在webrtcvad语音端点检测模块中完成的,其流程为:设置一个环形缓冲区的队列,最大长度为50(即存放最大时长1秒=50块),每个块送入环形缓冲区前需要用webrtcvad语音端点检测器给其打上是否为语音的标签,如果环形缓冲区中达到一半以上的语音块时,将环形缓冲区中的数据送入一个语音段的字节队列中,如果环形缓冲区中语音块少于一半时,在最后一个语音块后加一个none作为截止符,将截止符前的数据送入语音段,然后输出语音段给下游模块,如果这个语音段过长(连续20秒以上的数据),则会被舍弃,防止在模型推理步骤中时间维度超过其允许的最大值而出现报错。
16、对语音字节数据段进行语音预处理是在语音预处理模块中完成的,其流程为:将语音段里的字节数据转换成np.int16格式numpy阵列,做归一化并转成np.float32格式,最后转成(1,<time_length>)格式的张量。
17、将语音数据张量识别成文本是在语音识别模型推理模块中完成的,语音识别模型推理模块使用了wav2vec2语言识别模型将语音转换为文本。
18、wav2vec2语言识别模型的工作流程如下:
19、(1)将输入的语音信号进行预处理,包括采样率转换和频谱分析;
20、(2)使用mel-frequency cepstral coefficients特征提取算法将语音信号转换为特征向量;
21、(3)将特征向量输入到wav2vec2模型中,通过模型的多层神经网络进行分析;
22、(4)wav2vec2模型根据输入的特征向量预测出文本的字符序列;
23、(5)wav2vec2模型将预测的字符序列转换为文本,并返回结果。
24、wav2vec2语言识别模型输入为预处理好后的张量,输出的识别结果为带空格的字符串,空格为令牌的分割符。
25、wav2vec2语言识别模型采用无监督的方式进行大量无标注语音做预训练,然后仅使用极少的带标注的语音数据集做细粒度调整。
26、wav2vec2语言识别模型在做细粒度调整时,添加了现场采集的带口音的语音数据合并到普通话语音数据集中,并在数据增强中添加了噪声数据集。
27、将语音识别文本结果进行拼音模糊匹配是在rapidfuzz拼音模糊匹配模块中完成的,其流程为:先将识别结果去空格再转换成拼音,再按照现在工作阶段取出该阶段的关键词库,将这些关键词也转换成拼音,输入rapidfuzz算法进行字符串相似度匹配,按匹配到的关键词按置信度由高到低列出,然后遍历关键词,如果其与关键句是1比1对应的,则返回该关键句,如果其在多个关键句中出现,将这些关键句与这个关键词相关的另一个关键词取出看是否在剩余匹配到的关键词列表中,如存在,返回该关键句;对匹配到的关键词句进行打分并输出。
28、rapidfuzz拼音模糊匹配模块使用的是levenshtein距离算法来衡量两个字符串差异的度量。
29、rapidfuzz拼音模糊匹配模块使用分词n-grams和字符n-grams技术来提高字符串匹配和比较算法的准确性和速度。
30、对匹配到的关键词句进行打分并输出是在rabbitmq通信模块的"voice_contentmessage"通信管道中完成的,其中"voice_contentmessage"为rabbitmq交换器,用于在程序最末端将语音识别和匹配结果发送回软件端。
31、对匹配到的关键词句进行打分并输出是基于关键词拼音的模糊匹配策略,实现实时对语音识别片断做关键句匹配并打分。
32、为了实现这一目的本发明提供了一种基于语音识别的考评系统包括以下模块:
33、通信模块:用于在分布式系统中存储、转发和路由消息;
34、拉流模块:用来记录、转换和流传输音视频;
35、音频数据切块模块:访问麦克风和扬声器等音频设备;
36、语音端点检测模块:可以用于检测语音信号中的端点,即输入语音信号的开始和结束位置;
37、语音预处理模块:将语音段里的字节数据做归一化处理;
38、语音识别模型推理模块:可以用来将语音转换为文本;
39、拼音模糊匹配模块:提供了近似字符串匹配和比较的算法;
40、以上模块依次连接。
41、语音预处理模块将语音段里的字节数据转换成np.int16格式numpy阵列,做归一化并转成np.float32格式,最后转成(1,<time_length>)格式的张量。
42、通信模块包括3个通信管道:
43、"voice_tipmessage":为rabbitmq队列,用于从软件端接收考试开始信号和拉流地址;
44、"voice_tipstage":为rabbitmq队列,用于从软件端接收阶段跳转信号;
45、"voice_contentmessage":为rabbitmq交换器,用于在程序最末端将语音识别和匹配结果发送回软件端。
46、拉流模块是使用ffmpeg来进行音视频转码、多媒体格式转换、流传输和录制的任务。拉流模块会根据拉流地址的格式和输入选择,在子进程中做相应的拉流,将编解码器为pcm_s16le,采样率为16000hz,通道数为1这样格式的音频数据以字节方式存入audio_pipe,再用rnnoise模型对获得的音频进行去噪。当输入源是麦克风,则设置audio_pipe为none。
47、音频数据切块模块使用了portaudio库用于各种音频应用的开发,其工作流程为:设置pyaudio的stream,用callback()函数实时取出audio_pipe中的数据,按照每秒50个块,每个块包含320个图文框的方式切块,送入audio_queue。其工作流程为:设置一个环形缓冲区的队列,最大长度为50(即存放最大时长1秒=50块),每个块送入环形缓冲区前需要用webrtcvad语音端点检测器给其打上是否为语音的标签,如果环形缓冲区中达到一半以上的语音块时,将环形缓冲器中的数据送入一个语音段的字节序列中,如果环形缓冲器中语音块少于一半时,在最后一个语音块后加一个none作为截止符,将截止符前的数据送入语音段,然后输出语音段给下游模块,如果这个语音段过长(连续20秒以上的数据),则会被舍弃,防止在模型推理步骤中时间维度超过其允许的最大值而出现报错。
48、语音预处理模块,其工作流程为:将语音段里的字节数据转换成np.int16格式numpy行列式,做归一化并转成np.float32格式,最后转成(1,<time_length>)格式的张量。语音识别模型推理模块使用了wav2vec2语言识别模型将语音转换为文本。
49、wav2vec2语言识别模型的工作流程如下:
50、(1)将输入的语音信号进行预处理,包括采样率转换和频谱分析;
51、(2)使用mel-frequency cepstral coefficients特征提取算法将语音信号转换为特征向量;
52、(3)将特征向量输入到wav2vec2模型中,通过模型的多层神经网络进行分析;
53、(4)wav2vec2模型根据输入的特征向量预测出文本的字符序列;
54、(5)wav2vec2模型将预测的字符序列转换为文本,并返回结果。
55、wav2vec2语言识别模型输入为预处理好后的张量,输出的识别结果为带空格的字符串,空格为令牌的分割符。
56、wav2vec2语言识别模型采用无监督的方式进行大量无标注语音做预训练,然后仅使用极少的带标注的语音数据集做细粒度调整。
57、wav2vec2语言识别模型在做细粒度调整时,添加了现场采集的带口音的语音数据合并到普通话语音数据集中,并在数据增强中添加了噪声数据集。
58、拼音模糊匹配模块是使用的建立在fuzzywuzzy库之上的rapidfuzz。
59、拼音模糊匹配模块使用的是levenshtein距离算法来衡量两个字符串差异的度量,levenshtein距离越小,两个字符串就被认为越相似。
60、拼音模糊匹配模块使用分词n-grams和字符n-grams技术来提高字符串匹配和比较算法的准确性和速度。
61、拼音模糊匹配模块,其工作流程为:先将识别结果去空格再转换成拼音,再按照现在工作阶段取出该阶段的关键词库,将这些关键词也转换成拼音,输入rapidfuzz算法进行字符串相似度匹配,按匹配到的关键词按置信度由高到低列出,然后遍历关键词,如果其与关键句是1比1对应的,则返回该关键句,如果其在多个关键句中出现,将这些关键句与这个关键词相关的另一个关键词取出看是否在剩余匹配到的关键词列表中,如存在,返回该关键句;对匹配到的关键词句进行打分并输出。
62、本发明的有益效果是语音去噪使用了rnnoise音频去噪模型,用来去除人声语音中的背景噪声,能有效提高语音识别准确性;wav2vec2语音识别模型用无监督的方式进行大量无标注语音做预训练,仅使用极少的带标注的语音数据集做细粒度调整便可达到其他模型使用100倍以上大小带标注的语音数据集训练的同等效果;另外,在细粒度调整wav2vec2语音识别模型时,添加了现场采集的带口音的语音数据合并到普通话语音数据集中并在数据增强中添加了噪声数据集,这样细粒度调整出来的模型对现场噪声下的口音做语音识别鲁棒性更强;rapidfuzz使用levenshtein距离算法,,相比先做组合操作再计算相似度的方式,计算复杂度大大降低,从而能做到实时关键句匹配;另外从识别结果中抽关键词与数据库每个关键句中的关键词做匹配,大大提高了多断句情况下,成功匹配关键句的概率。
63、为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23335.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。