一种场景感知与事件分类的多任务声学分析方法
- 国知局
- 2024-06-21 11:49:50
本发明涉及环境声音分析,特别涉及一种场景感知与事件分类的多任务声学分析方法。
背景技术:
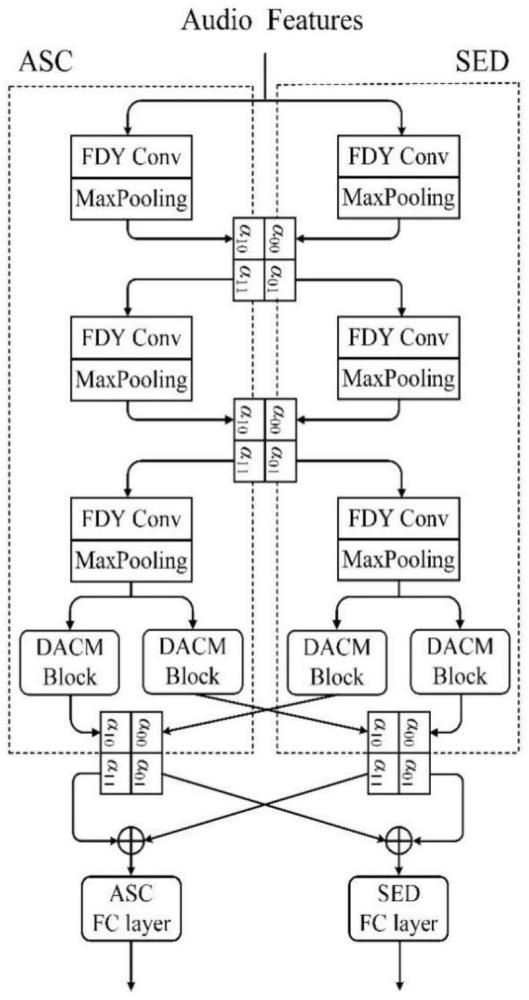
1、随着现代智能技术的迅猛发展,环境声音分析已经成为一个备受关注的研究领域,并在众多应用场景中展现出极大的重要性和潜力。例如自动生活记录系统、监控系统、异常声音检测系统以及生物监测系统等。环境声音分析领域主要集中于两个关键任务,分别是声音事件检测(sound event detection,sed)和声学场景分类(acoustic sceneclassification,asc)。声音事件检测涉及对采集到的音频数据进行分析,目的是识别和分类音频中特定的声音事件。如“儿童玩耍”、“车辆通过”、“枪声”或“报警声”等。此过程不仅要求准确识别声音的类型,如“敲击键盘”、“汽车行驶”、“餐具碰撞”或“人们交谈”等,还要估计每个声音事件的起始和结束时间。声学场景分类的目标是从不同音频片段中识别并区分具体的场景类别信息,以便帮助机器更有效的理解和判断其所处的声学环境。诸如“室内环境下的办公室”、“咖啡馆”和“杂货店”等常见场景,这些场景通常由多种类别的复杂声学事件构成,共同形成了一个既复杂又真实的声学环境。
2、在传统研究领域内,声音事件检测和声学场景分类通常被视为两个独立的任务。然而,许多声音事件与声学场景之间存在着内在的相关性,且能为彼此的识别提供关键性的辅助信息。例如“敲击键盘”、“鼠标点击”和“人们交谈”等声音事件在“办公室”这样的声学场景中更为常见,而“汽车行驶”和“鸟鸣”等声音事件在“办公室”环境中出现的可能性则相对较低。因此,在进行声音事件检测时,如果已知声音事件发生在特定的声学场景如“办公室”,这一信息可以增加“敲击键盘”和“鼠标点击”等声音事件识别的准确性,反之亦然。
3、现有技术一
4、在传统的单任务学习方法中,声学场景分类和声音事件检测通常被视为独立任务。这种方法采用专门为每种任务设计的单独模型,针对性地优化和处理每个任务,但是存在以下缺陷:
5、1)无法利用任务间的潜在联系
6、单任务学习方法在处理每个任务时,无法充分利用与其他任务的相关信息。由于缺乏跨任务的信息交流,可能导致性能受限。
7、2)资源和计算效率不足
8、由于需要为每个任务单独训练和优化模型,这种方法可能导致资源利用率低下和计算效率降低。这在处理多个相关任务时尤为明显,因为每个任务都需要独立的数据处理和模型训练。
9、3)泛化能力有限
10、尽管单任务学习方法在处理特定任务时可能表现良好,但它们通常处理多样化数据和场景时泛化能力较弱,限制了其在更广泛环境下的应用潜力。
11、现有技术二
12、鉴于声学场景和声音事件之间的密切联系,现有技术二提出了基于多任务学习(mtl)的神经网络对声学场景和事件进行联合分析。然而,该方案主要采用硬参数共享机制,这在一定程度上限制了不同任务间在训练过程中的信息流动和协同学习。它通常涉及在网络的不同层之间共享参数,以在处理多个任务时提高效率和性能。但是现有技术二存在以下缺陷:
13、1)限制任务间信息流动与协同学习
14、在硬参数共享机制中,不同任务共享相同的网络层。这可能导致信息流动和协同学习过程受限,因为共享层需要满足所有任务要求,可能无法对任何单一任务进行深度优化。
15、2)泛化能力有限
16、硬参数共享机制可能导致网络在处理新颖或未见过的数据时表现不佳。这是因为共享参数的调整主要基于特定训练数据集中的任务,可能无法很好地适应新的或变化的场景。
17、3)灵活性较差
18、硬参数共享的架构可能不够灵活。由于所有任务都依赖于相同的参数集,这限制了对特定任务进行优化。
19、参考文献
20、[1]tsubaki s,imoto k,ono n.joint analysis of acoustic scenes andsound events with weakly labeled data[c]//2022international workshop onacoustic signal enhancement(iwaenc).ieee,2022:1-5;
21、[2]nada k,imoto k,iwamae r,et al.multitask learning of acousticscenes and events using dynamic weight adaptation based on multi-focal loss[c]//2021 asia-pacific signal and information processing association annualsummit and conference(apsipa asc).ieee,2021:1156-1160;
22、[3]igarashi a,imoto k,komatsu y,et al.how information on acousticscenes and sound events mutually benefits event detection and sceneclassification tasks[c]//2022asia-pacific signal and information processingassociation annual summit and conference(apsipa asc).ieee,2022:7-11;
23、[4]nada k,imoto k,tsuchiya t.joint analysis of acoustic scenes andsound events based on multitask learning with dynamic weight adaptation[j].acoustical science and technology,2023,44(3):167-175;
24、[5]tonami n,imoto k,niitsuma m,et al.joint analysis of acousticevents and scenes based on multitask learning[c]//2019ieee workshop onapplications of signal processing to audio and acoustics(waspaa).ieee,2019:338-342;
25、[6]n.tonami,k.imoto,r.yamanishi and y.yamashita,“joint analysis ofsound events and acoustic scenes using multitask learning,’ieicetrans.inf.syst.,e104-d,294–301(2021);
26、[7]h.l.bear,i.nolasco and e.benetos,“towards joint sound scene andpolyphonic sound event recognition,’proc.inter-speech 2019,pp.4594–4598(2019);
27、[8]liang h,ji w,wang r,et al.a scene-dependent sound event detectionapproach using multi-task learning[j].ieee sensors journal,2021,22(18):17483-17489;
28、[9]komatsu t,imoto k,togami m.scene-dependent acoustic eventdetection with scene conditioning and fake-scene-conditioned loss[c]//icassp2020-2020ieee international conference on acoustics,speech and signalprocessing(icassp).ieee,2020:646-650。
技术实现思路
1、本发明针对现有技术的缺陷,提供了一种场景感知与事件分类的多任务声学分析方法。采用软参数共享机制,促进了声学场景分类与声音事件检测任务的协同学习,从而提升了声音事件检测的准确度。
2、为了实现以上发明目的,本发明采取的技术方案如下:
3、一种场景感知与事件分类的多任务声学分析方法,包括以下步骤:
4、1)数据准备:收集和准备声音事件检测(sed)和声音场景分类(asc)所需的声学数据集,包括音频片段和它们对应的标签(事件标签和场景标签)。
5、2)多分支注意力卷积网络设计:采用多任务联合学习网络,该网络设计两个子网络,一个用于声音事件检测,另一个用于声音场景分类,每个子网络都包括频率动态卷积、池化层、注意力机制和全连接层等模块。在每个卷积和注意力模块的后端都连接了cross-stitch模块,cross-stitch模块用于连接sed和asc两个任务,允许它们相互监督并确定共享信息与任务特有信息的最佳组合方式。
6、3)软参数共享:通过cross-stitch模块实现任务间特征的共享,以增强网络对关键特征的处理能力,并有效避免可能出现的性能损失。
7、4)损失函数:采用cross-entropy(ce)损失函数来训练asc的模型参数,用于计算模型对于声学场景分类的损失。采用binary cross-entropy(bce)损失函数来训练sed的模型参数,用于计算模型对于声音事件检测的损失。最终的损失函数是两个任务损失函数的加权和,通过加权联合优化,以实现更准确的分类性能。
8、5)模型训练:使用准备好的数据集和设计好的网络结构,进行模型训练,通过反向传播算法优化模型参数,以使得两个任务的损失函数都能够得到有效的减小。
9、6)将训练好的模型应用于实际场景感知与事件分类任务中,对输入的声音数据进行分类和分析,以实现声音事件检测和声学场景分类的多任务声学分析。
10、进一步地,步骤1)中选择对数梅尔特征作为音频的时频域特征。使用librosa库从原始音频信号中计算梅尔频谱图,再将梅尔频谱图转换为对数尺度。
11、进一步地,所述时频域特征中有64个梅尔频带,512的帧跳跃长度和2048点短时傅里叶变换大小;
12、计算梅尔频谱图的具体步骤包括将音频信号分为40毫秒的汉明窗,然后进行短时傅里叶变换来提取梅尔频谱图,并选择了64个带通滤波器。
13、进一步地,所述sed和asc两个任务中均采用3×3的频率动态卷积。在时间轴上对输入信号进行平均池化,沿着通道轴进行一维卷积来提取频率适应性的注意力权重。经过softmax函数对注意力权重进行调整,生成适应于特定频率的卷积核。这些卷积核被应用于标准的二维卷积中。
14、进一步地,所述多分支注意力卷积网络由两个并行分支模块组成,分别是注意力分支模块和卷积分支模块。注意力分支模块用于提取全局特征,卷积分支模块用于提取局部细节特征。这两个分支接收相同的输入特征,并分别进行独立处理,然后将处理后的特征合并送入融合单元。融合单元采用坐标注意力机制,用于对特征图进行更加精细化的处理。此外,该网络还采用了残差连接策略。将原始的输入特征通过残差连接传递到网络的后续层,与深层处理后的特征进行结合。
15、进一步地,所述注意力分支模块具体包括:对输入序列的全局上下文进行建模。对输入特征进行层归一化,以使得输入特征的分布更加稳定。使用多头自注意力机制来捕获序列中的全局信息。执行dropout操作来随机地将一部分神经元的输出置为零,以减少模型的过拟合程度。
16、进一步地,所述卷积分支模块具体包括:
17、卷积分支模块对输入数据进行层归一化,确保数据在不同网络层之间保持一致性和稳定性。
18、卷积分支模块中,卷积块的前后分别采用了两层线性层,并结合了gelu(gaussianerror linear unit)激活函数。通过线性变换和非线性激活,增强对输入特征的表征能力。
19、卷积块采用了深度可分离卷积。
20、卷积块引入了残差连接,将输入与最终的输出进行连接。
21、进一步地,所述融合单元的执行步骤如下:
22、1)对特征图y进行全局池化操作,分别在宽度和高度方向进行,得到yh和yw。
23、yh=globalavgpoolh(y),yw=globalavgpoolw(y)
24、2)yh和yw通过两层全连接层和激活函数生成注意力向量ah和aw。
25、ah=σ(fc(relu(fc(yh)))),aw=σ(fc(relu(fc(yw))))
26、3)使用生成的注意力向量对特征图y进行加权,得到调整后的特征图y'
27、
28、4)将调整后的特征图y′h和y′w在通道维度上合并,并与原始特征图y相加,得到最终的融合特征图yca。
29、yca=y+concat(y′h,y′w)
30、融合单元:融合单元采用坐标注意力机制,用于对特征图进行更加精细化的处理。经过深度可分离卷积后,通过坐标注意力生成注意力向量,再将注意力向量对特征图进行加权调整,与原始特征图合并,形成最终的融合特征图。
31、进一步地,所述cross-stitch模块的公式如下:
32、
33、式中,α是2×2矩阵,α00、α01、α10和α11为sed和asc两个任务间的融合权重,cross-stitch单元的参数设置在[0,1]之间,xasc、xsed、和分别为两任务的输入和加权融合后的输出。
34、进一步地,损失函数的流程如下:
35、采用cross-entropy(ce)损失函数来训练asc的模型参数。最终预测层设置了与数据集中声音场景标签数量相同的softmax单元,损失函数表示如下所示:
36、
37、其中,yn为网络的输出,n和sn分别代表声学场景类别数目和目标场景标签。对于sed任务,采用针对多标签分类的binary cross-entropy(bce)损失函数来训练模型参数。最终预测层包括与数据集中声音事件标签一样多的sigmoid单元,损失函数表示如下所示:
38、
39、其中,yt,m为网络输出,t、m和zt,m分别表示时间帧的数目、声音事件类别的数目和目标事件标签。
40、asc和sed任务的任务损失函数进行加权和。通过加权联合优化,联合损失函数如下式:
41、
42、与现有技术相比,本发明的优点在于:
43、(1)提高声音事件检测的准确度
44、通过采用软参数共享机制,促进了声学场景分类与声音事件检测任务的协同学习,显著提高了声音事件检测的准确度。在实验中,相比传统单任务学习模型,本发明提出的方法在tut acoustic scenes 2016/2017和tut sound events 2016/2017数据集以及synthetic sound scenes数据集上的平均f-score分别达到52.54%和47.92%,充分证明了方法的有效性。
45、(2)多任务学习网络设计的创新
46、本发明设计的多任务学习网络模型,能够高效地并行处理声学场景分类和声音事件检测任务。这种设计巧妙地利用了两个任务之间的关联性,不仅提高了任务处理的效率,也增强了准确性。实验结果表明,相较于最先进的方法,我们的模型在tut acousticscenes 2016/2017和tut sound events 2016/2017数据集以及synthetic sound scenes数据集的平均f-score分别提升了2.27%和3.22%。
47、(3)双分支注意力模块的优化
48、本发明设计了双分支注意力模块来有效地捕捉音频序列中的全局与局部上下文信息。此外,引入的坐标注意力机制作为模型的关键融合单元,进一步提升了模型的整体性能和感知能力。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23829.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表