一种基于声音检测的智能疾病诊断系统
- 国知局
- 2024-06-21 11:49:43
本发明属于智慧医疗领域,具体涉及一种基于声音检测的智能疾病诊断系统。
背景技术:
1、在利用音频信号进行疾病的智能疾病诊断领域,现有的方法可以分为三大类。第一类使用计算机视觉(cv)方法对从声音中提取的视觉表示,如mfcc或频谱图进行分类。这一类中常用的模型包括cnn、resnet和vit。第二类专注于音频信号的序列特征分类,其中广泛使用了诸如rnn、gru、lstm等模型。第三类是前两者的融合,研究人员结合并改进了这两种方法,例如在心音分类中应用的cnn-x模型。然而,每一类方法都有其固有的局限性。第一类本质上是图像分类,往往忽略了时间相关性,使其不太适合以声音作为诊断依据的任务。而第二类虽然关注时间相关性,但通常处理的是原始数据,其中关键特征深藏不露,导致提取最重要信息的能力减弱。第三类融合了前两者的优势,通常表现更佳。然而,它仍然面临一些挑战,如对某些相关维度的关注不足、规模有限,以及缺乏标记数据。后者限制了网络的潜在可扩展性。除此之外,已有方法通常都需要较大的数据集规模才能达到可观的表现水平,这限制了其推广和应用。
技术实现思路
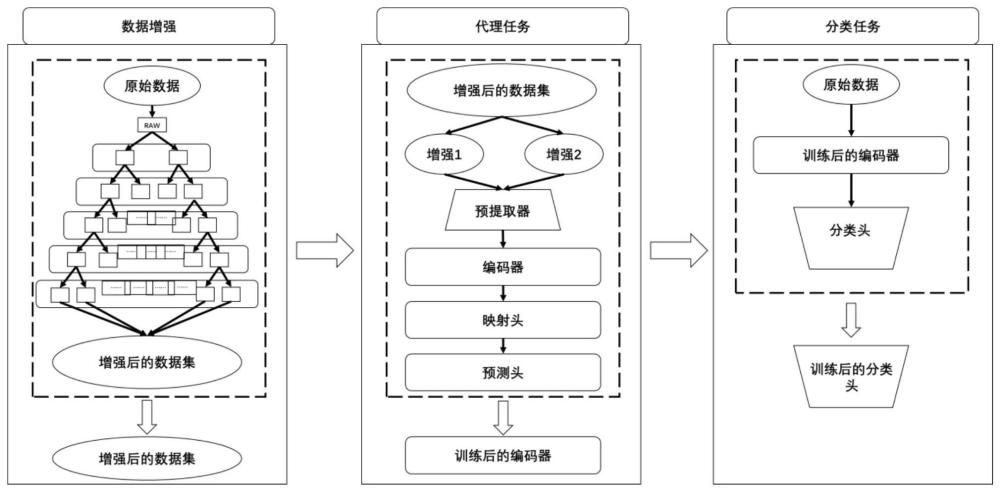
1、为解决上述技术问题,本发明提供了一种基于声音检测的智能疾病诊断系统,包括数据增强任务模块、代理任务模块和分类任务模块,该系统以深度学习为基础,以对比学习框架为核心,对多个模块分别采取针对性的训练,提高了特征提取能力,极大程度上增大隐藏特征被捕捉到的可能性,有效解决了传统方法针对声音信号进行编码时关注尺度有限的问题。
2、为达到上述目的,本发明采用了如下技术方案:
3、一种基于声音检测的智能疾病诊断系统,包括数据增强任务模块、代理任务模块和分类任务模块;
4、其中,数据增强模块采用层次化数据增强策略进行训练;
5、所述代理任务模块包括预提取模块、编码器模块、映射头、预测头;
6、所述分类任务模块仅采用一个全连接层作为分类头来完成分类任务。
7、进一步地,所述层次化数据增强策略包括五种音频增强方法:音量增强、噪声引入、速度调整、时间轴移动和频率轴移动,分别记为f1,f2,f3,f4,f5 ,每一种方法都在层次化框架内被分配一个独特的层,每个后续的增强层都会接收已经被其前一层增强过的数据,设第i层增强后的数据量为di,则有:di+1=2di。
8、进一步地,所述预提取模块为多尺度特征提取模块,使用多个不同大小的卷积核对时序信息进行多尺度信息的预提取,将不同大小卷积核的输出合并为一个多通道的数据,将此数据输入到后续的编码器模块;
9、所述编码器模块包括轴向多头自注意力模块和降维模块,采用双轴向自注意力机制将信息在各个尺度上进行提取,获取不同位置信息间的相互关系,最终输出能够表征输入数据的特征向量;
10、所述映射头包括投影模块,用于将特征向量进行投影,将编码器模块输出的特征向量映射到一个新的特征空间,获取更高维的信息;
11、所述预测头包括预测模块,用于使投影后的特征向量预测另一个分支投影模块的输出,利用余弦损失函数来衡量预测头的输出与映射头的输出之间的差异;
12、所述预测头和映射头均为若干层全连接神经网络;
13、所述分类任务模块仅采用一个全连接层作为分类头来完成分类任务,选择交叉熵损失函数作为损失函数,经过训练完成的所述编码器模块获得特定长度的特征向量,再使用该特征向量作为输入,将输出和标签的损失函数反向传播更新参数,最终获取一个能够完成特定任务的分类头。
14、本发明的有益效果:
15、(1)小样本下效果好:在医疗领域中,经常面临的一个挑战是标注数据的稀缺。而本发明恰好可以在这方面发挥优势,它可以最大化地利用有限的标签数据,在分类头上实现更高效的训练;
16、(2)充分提取多尺度特征考虑到音频特征通常存在于某一特定长度的片段上,为了充分捕捉特征,通过不同大小的卷积核来提取多尺度特征。由于在预提取阶段采用了一致的步长并进行了不同长度的填充处理,因此在编码器的最后阶段使用了较大的卷积核来融合来自不同通道的信息,并同时降低了数据的维度。这样的设计能极大程度上增大隐藏特征被捕捉到的可能性,有效解决了传统方法针对声音信号进行编码时关注尺度有限的问题。
17、(3)多轴注意力机制匹配音频特征图的信息分布:创新性地在编码器中引入了轴向多头自注意力机制,不同于经典的多头注意力,这一机制从梅尔频率倒谱系数(mfcc)的两个维度中提取特征,更好地适应了mfcc这一数据形式。这一创新点有效地增加了模型关注相关特征的维度范围,从而提高深度学习模型的特征提取上的能力。
技术特征:1.一种基于声音检测的智能疾病诊断系统,其特征在于,包括数据增强任务模块、代理任务模块和分类任务模块;
2.根据权利要求1所述的一种基于声音检测的智能疾病诊断系统,其特征在于,所述层次化数据增强策略包括五种音频增强方法:音量增强、噪声引入、速度调整、时间轴移动和频率轴移动,分别记为f1,f2,f3,f4,f5,每一种方法都在层次化框架内被分配一个独特的层,每个后续的增强层都会接收已经被前一层增强过的数据,设第i层增强后的数据量为di,则有:di+1=2di。
3.根据权利要求1所述的一种基于声音检测的智能疾病诊断系统,其特征在于,所述预提取模块包括多尺度特征提取模块,使用多个不同大小的卷积核对时序信息进行多尺度信息的预提取,将不同大小卷积核的输出合并为多通道的数据,将该多通道的数据输入到所述编码器模块;
4.根据权利要求1所述的一种基于声音检测的智能疾病诊断系统,其特征在于,所述分类任务模块仅采用一个全连接层作为分类头来完成分类任务具体包括,选择交叉熵损失函数作为损失函数,经过训练完成的所述编码器模块获得特定长度的特征向量,使用该特征向量作为输入,将输出和标签的损失函数反向传播更新参数,最终获取一个能够完成特定任务的分类头。
技术总结本发明提供了一种基于声音检测的智能疾病诊断系统,包括数据增强任务模块、代理任务模块和分类任务模块,所述系统基于自监督学习的思想和原理,针对数据增强任务模块采用层次化数据增强策略进行训练,针对代理任务模块采用对比学习的方法进行训练,针对分类任务模块采用一个全连接层作为分类头。该系统能极大程度上增大隐藏特征被捕捉到的可能性,有效解决了传统方法针对声音信号进行编码时关注尺度有限的问题,且有效地增加了模型关注相关特征的维度范围,从而提高深度学习模型的特征提取上的能力。技术研发人员:秦琳琳,吴刚,石春,孙文超受保护的技术使用者:中国科学技术大学技术研发日:技术公布日:2024/5/8本文地址:https://www.jishuxx.com/zhuanli/20240618/23807.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表