语音处理方法、装置、设备、存储介质和计算机程序产品与流程
- 国知局
- 2024-06-21 11:49:41
本申请涉及计算机,特别是涉及一种语音处理方法、装置、计算机设备、存储介质和计算机程序产品,还涉及一种语音增强模型的处理方法、装置、计算机设备、存储介质和计算机程序产品。
背景技术:
1、随着计算机技术与智能终端的快速发展,语音已成为信息传递的常用方式,如语音人机交互指令、即时语音消息、语音会议等等。真实环境中采集到的语音信号通常含有噪声,这些噪声的形式是多种多样的,例如其它说话人的声音、背景噪音等等,其存在严重降低了语音的听觉感知质量和可懂度。
2、语音增强可以从带噪语音信号中尽可能提取有用的语音信号,同时抑制、降低噪声的干扰。相关技术中,语音增强方案主要侧重于去除背景噪声和混响,无法过滤掉干扰人声,对于个性化语音增强(personalized speech enhancement,pse)的性能较差。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种能够提升个性化语音增强性能的语音处理方法、装置、计算机设备、计算机可读存储介质和计算机程序产品,以及语音增强模型的处理方法、装置、计算机设备、计算机可读存储介质和计算机程序产品。
2、第一方面,本申请提供了一种语音处理方法。所述方法包括:
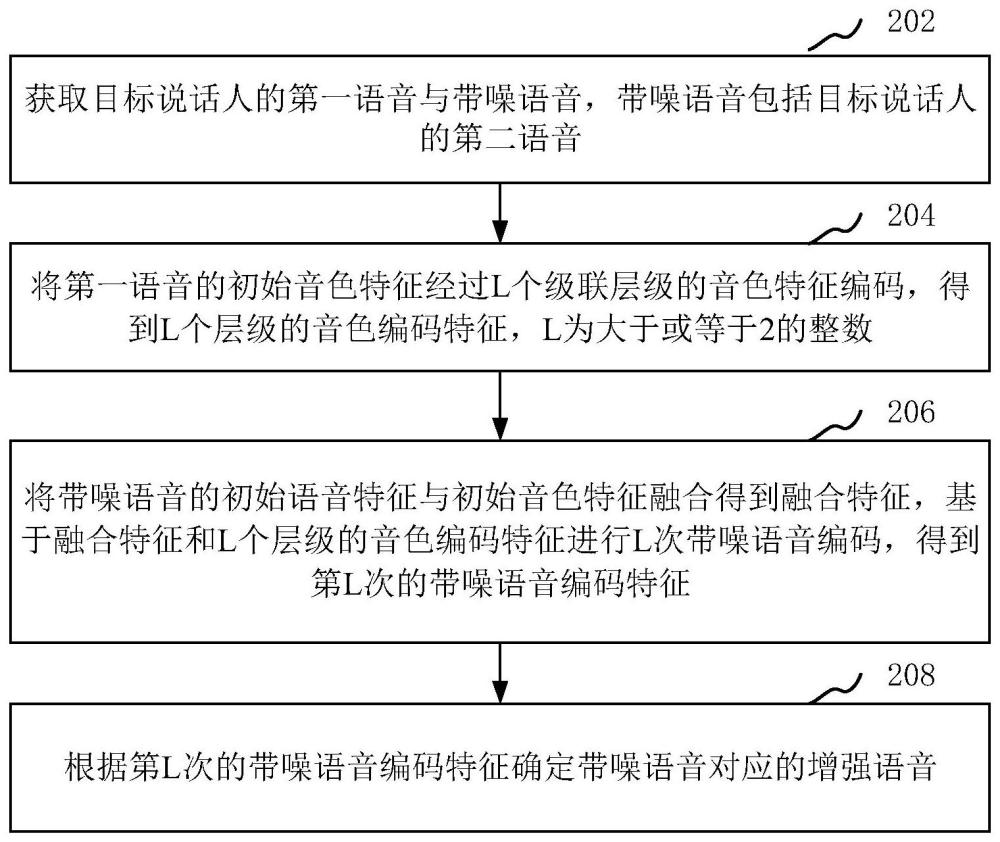
3、获取目标说话人的第一语音与带噪语音,所述带噪语音包括所述目标说话人的第二语音;
4、将所述第一语音的初始音色特征经过l个级联层级的音色特征编码,得到l个层级的音色编码特征;l为大于或等于2的整数;
5、将所述带噪语音的初始语音特征与所述初始音色特征融合得到融合特征;
6、基于所述融合特征和所述l个层级的音色编码特征进行l次带噪语音编码,得到第l次的带噪语音编码特征;
7、根据所述第l次的带噪语音编码特征确定所述带噪语音对应的增强语音。
8、第二方面,本申请还提供了一种语音处理装置。所述装置包括:
9、获取模块,用于获取目标说话人的第一语音与带噪语音,所述带噪语音包括所述目标说话人的第二语音;
10、音色特征编码模块,用于将所述第一语音的初始音色特征经过l个级联层级的音色特征编码,得到l个层级的音色编码特征;l为大于或等于2的整数;
11、带噪语音编码模块,用于将所述带噪语音的初始语音特征与所述初始音色特征融合得到融合特征;基于所述融合特征和所述l个层级的音色编码特征进行l次带噪语音编码,得到第l次的带噪语音编码特征;
12、增强语音确定模块,用于根据所述第l次的带噪语音编码特征确定所述带噪语音对应的增强语音。
13、第三方面,本申请还提供了一种计算机设备。所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
14、获取目标说话人的第一语音与带噪语音,所述带噪语音包括所述目标说话人的第二语音;
15、将所述第一语音的初始音色特征经过l个级联层级的音色特征编码,得到l个层级的音色编码特征;l为大于或等于2的整数;
16、将所述带噪语音的初始语音特征与所述初始音色特征融合得到融合特征;
17、基于所述融合特征和所述l个层级的音色编码特征进行l次带噪语音编码,得到第l次的带噪语音编码特征;
18、根据所述第l次的带噪语音编码特征确定所述带噪语音对应的增强语音。
19、第四方面,本申请还提供了一种计算机可读存储介质。所述计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
20、获取目标说话人的第一语音与带噪语音,所述带噪语音包括所述目标说话人的第二语音;
21、将所述第一语音的初始音色特征经过l个级联层级的音色特征编码,得到l个层级的音色编码特征;l为大于或等于2的整数;
22、将所述带噪语音的初始语音特征与所述初始音色特征融合得到融合特征;
23、基于所述融合特征和所述l个层级的音色编码特征进行l次带噪语音编码,得到第l次的带噪语音编码特征;
24、根据所述第l次的带噪语音编码特征确定所述带噪语音对应的增强语音。
25、第五方面,本申请还提供了一种计算机程序产品。所述计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现以下步骤:
26、获取目标说话人的第一语音与带噪语音,所述带噪语音包括所述目标说话人的第二语音;
27、将所述第一语音的初始音色特征经过l个级联层级的音色特征编码,得到l个层级的音色编码特征;l为大于或等于2的整数;
28、将所述带噪语音的初始语音特征与所述初始音色特征融合得到融合特征;
29、基于所述融合特征和所述l个层级的音色编码特征进行l次带噪语音编码,得到第l次的带噪语音编码特征;
30、根据所述第l次的带噪语音编码特征确定所述带噪语音对应的增强语音。
31、上述语音处理方法、装置、计算机设备、存储介质和计算机程序产品,获取第一语音与带噪语音,将该第一语音的初始音色特征经过l个级联层级的音色特征编码,可有效去除第一语音中除音色信息以外的其它信息,得到l个层级的音色编码特征,将该带噪语音的初始语音特征与该初始音色特征融合得到融合特征,基于该融合特征和该l个层级的音色编码特征进行l次带噪语音编码,得到第l次的带噪语音编码特征。该过程中,通过多次的交互融合可增强目标说话人音色信息的表达,有助于个性化语音的增强,根据该第l次的带噪语音编码特征确定该带噪语音对应的增强语音,有效地剔除了带噪语音中的噪音和其它说话人的干扰声音,提升了关于目标说话人的语音增强性能。
技术特征:1.一种语音处理方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述基于所述融合特征和所述l个层级的音色编码特征进行l次带噪语音编码,得到第l次的带噪语音编码特征,包括:
3.根据权利要求2所述的方法,其特征在于,所述方法还包括:
4.根据权利要求1所述的方法,其特征在于,所述根据所述第l次的带噪语音编码特征确定所述带噪语音对应的增强语音,包括:
5.根据权利要求1所述的方法,其特征在于,所述语音处理方法基于语音增强模型实现,所述语音增强模型的训练步骤包括:
6.根据权利要求1所述的方法,其特征在于,每次进行带噪语音编码的编码块由1维卷积层、1维批量归一化层、激活函数层、1维卷积层、时间维的实例规范化层、多头注意力层依次连接而成,所述时间维的实例规范化层,用于计算输入至所述时间维的实例规范化层的输入特征与所述输入特征的均值的差异,并根据所述输入特征的方差,对所述差异进行归一化处理,得到所述时间维的实例规范化层的输出特征。
7.根据权利要求1至6中任一项所述的方法,其特征在于,所述方法还包括:
8.一种语音处理装置,其特征在于,所述装置包括:
9.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至7中任一项所述的方法的步骤。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至7中任一项所述的方法的步骤。
11.一种计算机程序产品,包括计算机程序,其特征在于,该计算机程序被处理器执行时实现权利要求1至7中任一项所述的方法的步骤。
技术总结本申请涉及一种语音处理方法、装置、计算机设备、存储介质和计算机程序产品。方法包括:获取目标说话人的第一语音与带噪语音,带噪语音包括目标说话人的第二语音;将第一语音的初始音色特征经过L个级联层级的音色特征编码,得到L个层级的音色编码特征;L为大于或等于2的整数;将带噪语音的初始语音特征与初始音色特征融合得到融合特征;基于融合特征和L个层级的音色编码特征进行L次带噪语音编码,得到第L次的带噪语音编码特征;根据第L次的带噪语音编码特征确定带噪语音对应的增强语音。采用本方法能够提升关于目标说话人的语音增强性能。技术研发人员:熊雪军受保护的技术使用者:马上消费金融股份有限公司技术研发日:技术公布日:2024/5/8本文地址:https://www.jishuxx.com/zhuanli/20240618/23804.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
一种一位蜂鸣器的制作方法
下一篇
返回列表