语音降噪增强方法、装置、产品、车载语音降噪增强系统与流程
- 国知局
- 2024-06-21 11:50:58
本发明实施例涉及音频处理,尤其涉及语音降噪增强方法、装置、产品、车载语音降噪增强系统。
背景技术:
1、随着汽车消费升级、个性化需求和智能网联汽车的发展,车载语音系统已经成为人们购买汽车的重要考虑因素之一,车载语音是指在汽车内部使用语音识别交互、蓝牙电话和音视频录制等,提高出行的便捷性、乐趣和舒适度。但是目前降噪增强效果较好的方案为音频与视频唇动融合来对语音进行降噪增强处理,该方式存在以下弊端:车端部署难度高、使用成本高、系统算力资源占用高,处理速度慢。同时现有的降噪增强方式对于低信噪比、非稳态噪声、强混响环境下的语音进行增强时往往难以去除噪声成分,从而导致使用体验不佳。
技术实现思路
1、有鉴于此,本发明实施例提供一种语音降噪增强方法、装置、产品、车载语音降噪增强系统,旨在降低对语音进行降噪增强的资源占用的同时提升对语音的降噪增强效果。
2、本发明实施例第一方面提供了一种语音降噪增强方法,所述方法包括:
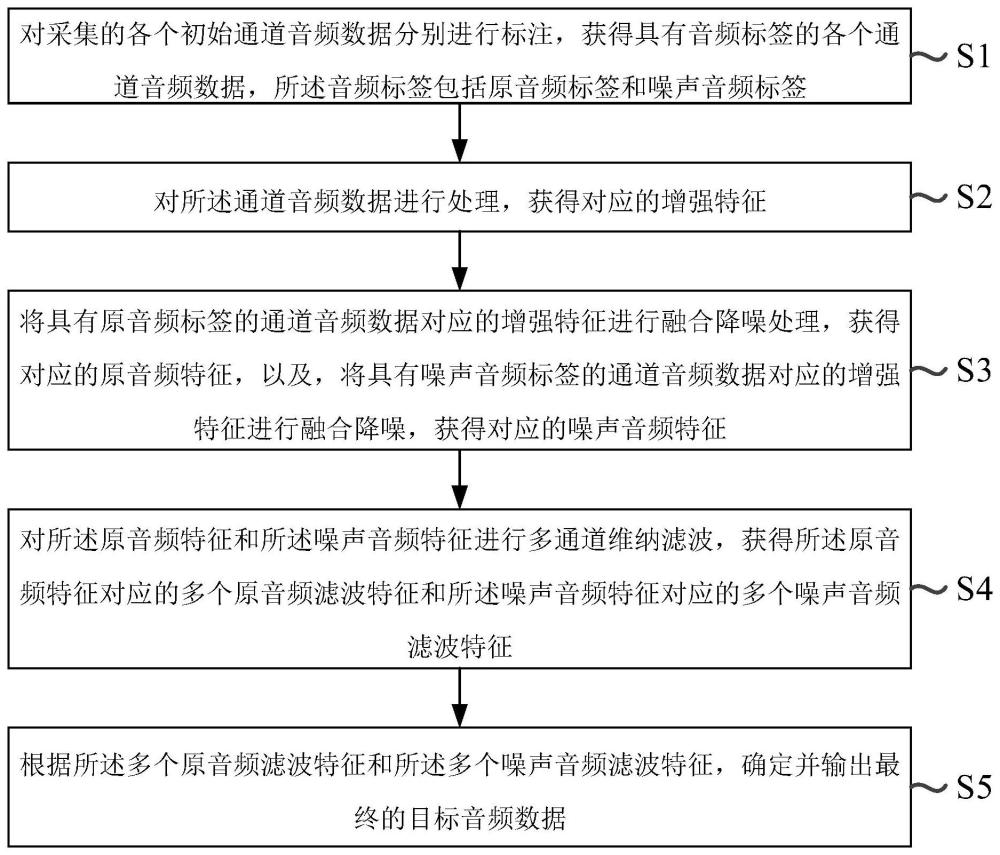
3、对采集的各个初始通道音频数据分别进行标注,获得具有音频标签的各个通道音频数据,所述音频标签包括原音频标签和噪声音频标签;
4、对所述通道音频数据进行处理,获得对应的增强特征;
5、将具有原音频标签的通道音频数据对应的增强特征进行融合降噪处理,获得对应的原音频特征,以及,将具有噪声音频标签的通道音频数据对应的增强特征进行融合降噪,获得对应的噪声音频特征;
6、对所述原音频特征和所述噪声音频特征进行多通道维纳滤波,获得所述原音频特征对应的多个原音频滤波特征和所述噪声音频特征对应的多个噪声音频滤波特征;
7、根据所述多个原音频滤波特征和所述多个噪声音频滤波特征,确定并输出最终的目标音频数据。
8、可选的,所述对所述通道音频数据进行处理,获得对应的增强特征,包括:
9、对所述通道音频数据进行傅里叶变换,获得对应的目标频域数据;
10、对所述目标频域数据进行增强处理,获得对应的频域特征;
11、对所述频域特征进行池化处理,获得对应的增强特征。
12、可选的,所述将具有原音频标签的通道音频数据对应的增强特征进行融合降噪处理,获得对应的原音频特征,以及,将具有噪声音频标签的通道音频数据对应的增强特征进行融合降噪,获得对应的噪声音频特征,包括:
13、将具有原音频标签的通道音频数据对应的增强特征进行融合,获得对应的原音频融合特征,以及,将具有噪声音频标签的通道音频数据对应的增强特征进行融合,获得对应的噪声音频融合特征;
14、对所述原音频融合特征和所述噪声音频融合特征进行并行降噪处理,获得原音频特征和噪声音频特征。
15、可选的,所述对所述通道音频数据进行傅里叶变换,获得对应的目标频域数据,包括:
16、通过时间窗函数对所述通道音频数据进行划分,获得对应的多个时间窗音频数据;
17、通过分析窗函数对所述多个时间窗音频数据进行并行计算,获得所述多个时间窗音频数据各自对应的中间音频数据;
18、对获得的多个中间音频数据进行并行傅里叶变换,获得所述多个中间音频数据各自对应的子频域数据;
19、将所述多个中间音频数据各自对应的子频域数据共同确定为所述通道音频数据对应的目标频域数据。
20、可选的,所述对所述目标频域数据进行增强处理,获得对应的频域特征,包括:
21、对构成所述目标频域数据的所有子频域数据进行并行增强处理,针对每个子频域数据获得对应的在不同频段的多个子频域特征;
22、将所述所有子音频数据各自对应的在不同频段的多个子频域特征共同确定为所述通道音频数据对应的频域特征。
23、可选的,所述对所述频域特征进行池化处理,获得对应的增强特征,包括:
24、对构成所述频域特征的所有子频域特征进行并行中值池化处理,针对每个子频域特征获得对应的中值特征;
25、将所述所有子频域特征各自对应的中值特征共同确定为所述通道音频数据对应的增强特征。
26、可选的,所述将具有原音频标签的通道音频数据对应的增强特征进行融合,获得对应的原音频融合特征,包括:
27、根据具有原音频标签的通道音频数据的数量,确定进行加权融合的第一权重;
28、根据所述第一权重,将具有原音频标签的相同时间窗口和相同频段下的中值特征进行加权融合,获得对应的原音频融合中值特征;
29、将获得的相同频段下的原音频融合中值特征按照时间先后顺序进行拼接,获得对应的初始原音频融合特征;
30、将不同频段下的初始原音频融合特征共同确定为具有原音频标签的原音频融合特征。
31、可选的,所述将具有噪声音频标签的通道音频数据对应的增强特征进行融合,获得对应的噪声音频融合特征,包括:
32、根据具有噪声音频标签的通道音频数据的数量,确定进行加权融合的第二权重;
33、根据所述第二权重,将具有噪声音频标签的相同时间窗口和相同频段下的中值特征进行加权融合,获得对应的初始噪声音频融合中值特征;
34、将获得的相同频段下的噪声音频融合中值特征按照时间先后顺序进行拼接,获得对应的初始噪声音频融合特征;
35、将不同频段下的初始噪声音频融合特征共同确定为具有噪声音频标签的噪声音频融合特征。
36、可选的,所述对所述原音频融合特征和所述噪声音频融合特征进行并行降噪处理,获得原音频特征和噪声音频特征,包括:
37、对构成所述原音频融合特征的不同频段下的初始原音频融合特征和对构成所述噪声音频融合特征的不同频段下的初始噪声音频融合特征进行并行降噪处理,针对每个频段下的初始原音频融合特征获得对应的初始原音频降噪特征,以及,针对每个频段下的初始噪声音频融合特征获得对应的初始噪声音频降噪特征;
38、将不同频段下的初始原音频降噪特征共同确定为原音频特征,以及,将不同频段下的初始噪声音频降噪特征共同确定为噪声音频特征。
39、可选的,所述对所述原音频特征和所述噪声音频特征进行多通道维纳滤波,获得所述原音频特征对应的多个原音频滤波特征和所述噪声音频特征对应的多个噪声音频滤波特征,包括:
40、将构成所述原音频特征的每种频段下的初始原音频降噪特征输入第一维纳滤波通道进行并行维纳滤波处理,针对每种频段下的初始原音频降噪特征获得对应的多个初始原音频滤波特征,所述第一维纳滤波通道与具有原音频标签的各个通道音频数据的通道一一对应;
41、将构成所述噪声音频特征的每种频段下的初始噪声音频降噪特征输入第二维纳滤波通道进行并行维纳滤波处理,针对每种频段下的初始噪声音频降噪特征获得对应的多个初始噪声音频滤波特征,所述第二维纳滤波通道与具有噪声音频标签的各个通道音频数据的通道一一对应;
42、将经过相同第一维纳滤波通道进行维纳滤波处理所获得的所有初始原音频滤波特征共同确定为对应的一个原音频滤波特征,以此获得所述原音频特征对应的多个原音频滤波特征;
43、将经过相同第二维纳滤波通道进行维纳滤波处理所获得的所有初始噪声音频滤波特征共同确定为对应的一个噪声音频滤波特征,以此获得所述噪声音频特征对应的多个噪声音频滤波特征。
44、本发明实施例第二方面提供了一种语音降噪增强装置,所述装置包括:
45、标注模块,用于对采集的各个初始通道音频数据分别进行标注,获得具有音频标签的各个通道音频数据,所述音频标签包括原音频标签和噪声音频标签;
46、增强处理模块,用于对所述通道音频数据进行处理,获得对应的增强特征;
47、加权融合降噪模块,用于将具有原音频标签的通道音频数据对应的增强特征进行融合降噪处理,获得对应的原音频特征,以及,将具有噪声音频标签的通道音频数据对应的增强特征进行融合降噪,获得对应的噪声音频特征;
48、维纳滤波模块,用于对所述原音频特征和所述噪声音频特征进行多通道维纳滤波,获得所述原音频特征对应的多个原音频滤波特征和所述噪声音频特征对应的多个噪声音频滤波特征;
49、目标音频数据确定模块,用于根据所述多个原音频滤波特征和所述多个噪声音频滤波特征,确定并输出最终的目标音频数据。
50、本发明实施例第三方面提供了一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现如本技术上述第一方面提供的一种语音降噪增强方法。
51、本发明实施例第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如本技术上述第一方面提供的一种语音降噪增强方法。
52、本发明实施例第五方面提供了一种车载语音降噪增强系统,所述系统包括:单个或多个麦克风阵列、信号处理模块、低通滤波器、模数转换模块,音频数字信号处理器、智能座舱主控器、音频流管理模块;
53、所述麦克风阵列,用于进行多个通道的音频数据的采集;
54、所述信号处理模块,用于对采集的多个通道的音频数据进行信号放大和降噪处理,获得多个通道的第一音频数据;
55、所述低通滤波器,用于去除所述多个通道的第一音频数据中的高频信号,获得多个通道的第二音频数据;
56、所述模数转换模块,用于对所述多个通道的第二音频数据进行模数转换,获得多个通道的第三音频数字信号;
57、所述音频数字信号处理器,用于对所述多个通道的第三音频数字信号进行数字降噪,获得多个初始通道音频数据,并将所述多个初始通道音频数据发送至所述智能座舱主控器;
58、所述智能座舱主控器,用于在硬件抽象层中通过如本技术上述第一方面提供的一种语音降噪增强方法,基于所述多个初始通道音频数据确定最终的目标音频数据;
59、所述音频流管理模块,用于对所述目标音频数据进行混音处理和自适应延时处理,获得第一目标音频数据;
60、所述音频信号数字处理器,还用于接收所述第一目标音频数据,并通过扬声器进行外放输出。
61、可选的,所述系统还包括云平台、通讯模块;
62、所述通讯模块,用于提供所述云平台与所述智能座舱主控器的通讯链路;
63、所述云平台,用于对硬件抽象层中的语音降噪增强功能进行ota更新和对预设神经网络进行在线训练。
64、通过本发明实施例提供的语音降噪增强方法,首先在空间内通过麦克风阵列采集多个通道的音频数据,以此获得多个初始通道音频数据;然后对采集的各个初始通道音频数据分别进行标注,获得具有音频标签的各个通道音频数据,该音频标签包括原音频标签和噪声音频标签;对所有通道音频数据进行处理,针对每个通道音频数据获得一个对应的增强特征;将具有原音频标签的所有通道音频数据各自对应的增强特征全部拿来进行融合降噪,获得一个对应的原音频特征,以及,将具有噪声音频标签的所有通道音频数据各自对应的增强特征全部拿来进行融合降噪,获得一个对应的噪声音频特征;对获得的原音频特征和获得的噪声音频特征进行多通道维纳滤波,针对原音频特征将获得对应的多个原音频滤波特征,针对噪声音频特征将获得对应的多个噪声音频滤波特征;根据获得的多个原音频滤波特征和获得的多个噪声音频滤波特征,确定最终的目标音频数据并进行输出。由此,本技术在进行语音的降噪增强不再考虑唇动数据,而通过语音单模方式对语音进行降噪增强,该方式可以有效降低降噪增强的资源占用,在不再考虑唇动数据可能出现降噪增强效果不佳的情况下,本技术通过引入多通道的音频数据和加权融合以及进行多通道的维纳滤波来提升对语音的降噪增强的效果,通过验证确定本技术对语音降噪增强具有很好的鲁棒性,并且在低信噪比时对各种语音交互场景的语音降噪增强效果提升很明显,客观语音质量评估(pesq)高。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23958.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
语音编辑方法及装置与流程
下一篇
返回列表