一种双模态语音情感识别方法及系统
- 国知局
- 2024-06-21 11:52:04
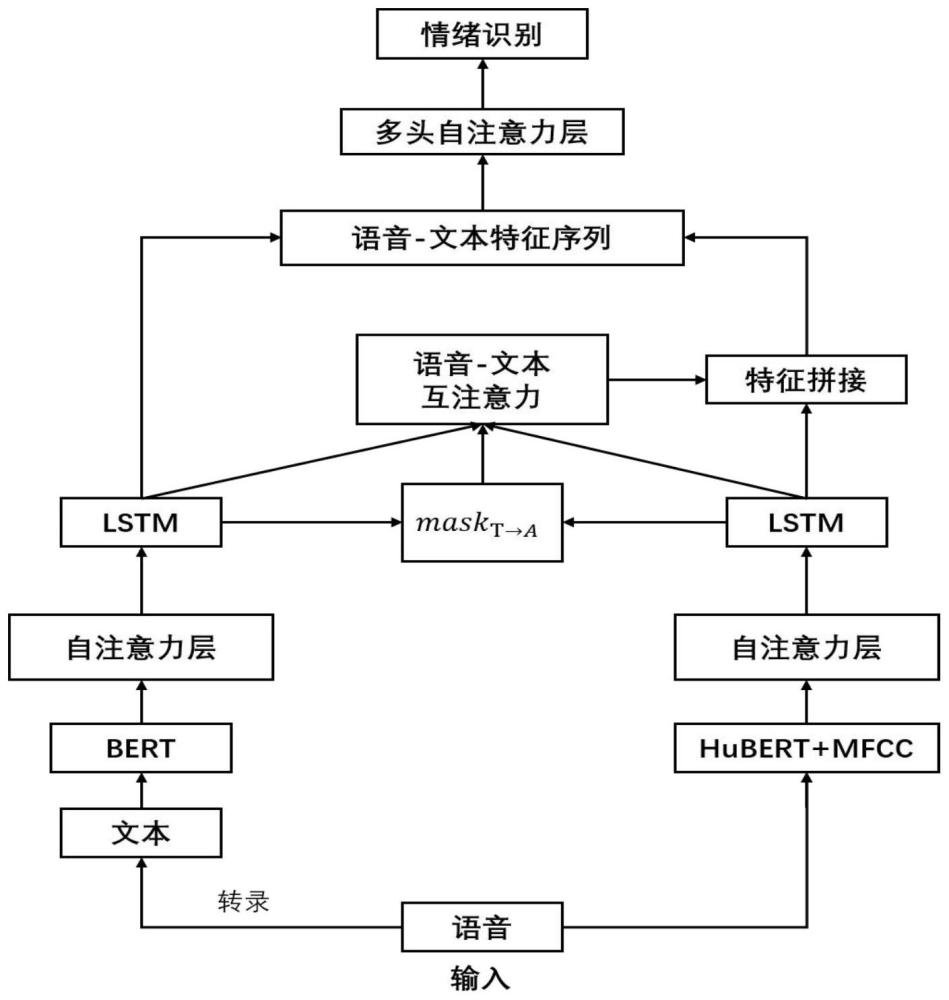
本发明涉及情绪识别,具体涉及一种双模态语音情感识别方法及系统。
背景技术:
1、情绪识别是人工智能研究中十分重要的一个分支领域,在教育医疗、商业营销分析与智能机器人等方面都存在着良好的应用前景。近年来,各大公司推出了许多的智能语音助手,如百度小度、小米小爱、微软小冰等,让用户可以通过语音文字等方式进行人机交互,但若想实现更加真实的智能交互,则需要语音助手能够更加精准的理解分析出用户的情绪状态,并做出合理的回应。
2、目前,语音情绪识别主要是通过提取语音不同的声学特征与频谱特征,再利用深度学习网络分析学习这些特征中含有的情感信息,以实现情绪识别。这种方法仍存在着一些问题,一方面提取出的声学特征与频谱特征的表征能力一般,无法很好的对语音信息进行高效的表示;另一方面,在情绪识别中,使用单一模态的数据往往存在信息的局限性,无法充分挖掘表达者的情绪信息。
技术实现思路
1、针对现有技术使用单一模态的数据往往存在信息的局限性,无法充分挖掘表达者的情绪信息的不足,本发明提出一种双模态语音情感识别方法及系统,通过利用语音中的音频和文本,以更全面地分析和识别个体的情感状态,从而解决现有技术使用单一模态的数据往往存在信息的局限性,无法充分挖掘表达者的情绪信息的问题。
2、一种双模态语音情感识别方法,包括以下步骤:
3、获取待识别语音数据的语音信号,并提取其中的文本信息;
4、对语音信号进行分帧处理,将分帧后的每帧语音信号输入语音预训练模型中进行编码,获得语音信号的高级特征;
5、提取语音信息中的mfcc声学特征,并将语音信号的高级特征与声学特征按帧拼接,获得语音特征序列;
6、使用文本预训练模型提取文本信息的高级特征,构建出文本特征序列;
7、使用自注意力机制分别提取语音特征序列和文本特征序列中的关键情感特征,并通过长短期记忆神经网络给每个关键情感特征分别添加时序信息,获得语音深度情感特征和文本深度情感特征;
8、采用模态融合算法将语音深度情感特征和文本深度情感特征进行融合,获得语音情感特征;
9、根据语音情感特征对待识别语音数据进行情感识别。
10、进一步地,通过语音转录api或本地语音转录模型对语音信号进行转录,提取其中的文本信息。
11、进一步地,所述对语音信号进行分帧处理,将分帧后的每帧语音信号输入语音预训练模型中进行编码,获得语音信号的高级特征,具体包括以下步骤:
12、将语音信号以20ms的长度为一帧的方式进行切分,获得语音序列a={a1,a2,a3,…,an};
13、将语音序列输入卷积神经网络cnn中进行编码,获取中间特征序列m={m1,m2,m3,…,mn}。
14、进一步地,还包括在将语音序列输入卷积神经网络cnn中进行编码时对transformer的编码形式进行改进,在中间特征序列m中的每个元素加入相对位置编码其表示为:
15、
16、其中,ri-j是i相对j的位置编码,u和v是待学习的参数,wk被分解为和分别表示输入和位置编码;
17、将加入相对位置编码后的中间特征序列m输入经过改进的transformer encoder中,利用序列上下文特征信息来预测中间特征的信息,初步融合上下文信息,获得语音信号的预训练特征fhubert={h1,h2,h3,…,hn};
18、f=transformer(m)
19、其中,fhubert∈rn×768,n为语音帧数。
20、进一步地,所述提取语音信息中的mfcc声学特征,具体包括以下步骤:
21、将语音信号序列a={a1,a2,a3,…,an}乘上汉明窗w(i,k),得到a'={a'1,a'2,a'3,…,a'n},表示为:
22、
23、a'=a*w(i,k)
24、对特征a'进行傅里叶变换得到各帧在频谱上的能量分布,并对语音信号的频谱取模平方得到语音信号的功率谱;
25、设语音信号的dft为:
26、
27、其中,a'i为经过加窗输入的语音信号;
28、将得到每帧的功率谱通过一组mel尺度的三角形滤波器组,计算每个滤波器组输出的对数能量;
29、将对数能量带入离散余弦变换,求出l阶的mel参数;其中,所述l阶为mfcc系数阶数,进而获取每帧信号的mfcc声学特征,其包括以下步骤:
30、定义一个有m个滤波器的滤波器组,其中采用的滤波器为三角滤波器,中心频率为f(m),m取值在22-26之间,各f(m)之间的间隔随着m值的减小而缩小,随着m值的增大而增宽;
31、三角滤波器的频率响应定义为:
32、
33、计算每个滤波器组输出的对数能量为:
34、
35、经离散余弦变换(dct)得到mfcc系数:
36、
37、将上述的对数能量带入离散余弦变换,求出l阶的mel参数,l阶指mfc c系数阶数本通常取13,m是三角滤波器个数;
38、经离散余弦变换(dct)得到mfcc系数:
39、
40、将对数能量带入离散余弦变换,求出l阶的mel参数;
41、获取每帧信号的mfcc特征,fmfcc={mfcc1,mfcc2,mfcc3,…,mfccn}。
42、进一步地,所述将语音信号的高级特征与声学特征按帧拼接,获得语音特征序列;其具体包括以下步骤:
43、将高级语音特征fhubert={h1,h2,h3,…,hn}与mfcc声学特征按照帧的维度进行拼接,获取语音的模态特征序列。
44、进一步地,所述使用文本预训练模型提取文本信息的高级特征,构建出文本特征序列;其包括以下步骤:
45、假设文本初始序列为t={w1,w2,w3,…,wn},其中wi代表文本序列中的第i个字;
46、对文本初始序列的首尾分别添加补充cls、sep,得到:
47、t=[wcls,w1,w2,……,wn,wsep]
48、使用库函数bert tokenizer处理输入的文本序列t,得到input_ids、token_type_ids、attention_mask三个列表;
49、将三个列表送入文本预训练模型中获取文本的高级特征序列其中ft∈rn×768大小为n×768,每个字获得一个768维的词向量。
50、进一步地,所述使用自注意力机制分别提取语音特征序列和文本特征序列中的关键情感特征,并通过长短期记忆神经网络给每个关键情感特征分别添加时序信息,获得语音深度情感特征和文本深度情感特征,包括以下步骤:
51、对语音特征序列创建三个学习矩阵对文本特征序列创建三个学习矩阵通过以下方式获取自注意力机制输入。
52、
53、
54、
55、其中,querya/keya/valuea∈rn×m,queryt/keyt/valuet∈rn×m。
56、对每一个query与key计算相似度:
57、
58、对求的相似度分数使用softmax进行归一化处理,将相似度分数变成权重和为1的概率分布:
59、
60、使用求得的权重系数对value值进行加权求和,得到语音特征序列的atten tion分数为:
61、
62、文本特征序列的attention分数为:
63、
64、计算得到的注意力特征从而获取语音自注意力特征序列ya和文本自注意力特征序列yt;
65、利用lstm向语音自注意力特征序列ya和文本自注意力特征序列yt添加前后时序信息,得到新的语音特征序列faudio和新的文本特征序列ftext:
66、faudio=lstm(ya),ftext=lstm(yt)。
67、进一步地,所述采用模态融合算法将语音深度情感特征和文本深度情感特征进行融合,获得语音情感特征,包括以下步骤:
68、假设掩码矩阵为maskt→a,对于文本序列中的第m个特征,计算语音序列中所有特征对其的注意力权重
69、
70、对注意力权重按照大小对其排序,选择前k大的值对应的语音序列节点m={m1,m2,…,mk},将掩码矩阵maskt→a中位置(m,t)置1,其余位置置0,m∈m;
71、对语音特征序列中每一个特征对文本特征序列ftext的相似分数,记作sa→t;
72、
73、使用softmax函数计算注意力权重wa→t,同时使用掩码矩阵屏蔽其他不重要的特征;
74、
75、wa→t=wa→t*maskt→a
76、获得来自文本与的共享情感语义特征向量ct;
77、ct=wa→t*ftext
78、利用lstm给共享语义特征添加时序信息,获得共享情感语义fshare;
79、fshare=lstm(ct)
80、将语音情感语义特征与共享情感语义特征拼接,获得增强的语音情感特征fen_audio;
81、fen_audio=concat(faudio,fshare)
82、将增强的语音情感特征与文本特征组合成新的特征序列,利用多头自注意力机制学习不同子空间语音与文本特征的关联,获得多模态情感特征;
83、
84、ftemp1=multihead_self_6ttention(ftemp)
85、fmulti=concate(ftemp1[0],ftemp1[1])。
86、进一步地,一种双模态语音情感识别系统,包括:
87、获取模块,用于获取待识别语音数据的语音信号,并提取其中的文本信息;
88、处理模块,用于对语音信号进行分帧处理,将分帧后的每帧语音信号输入语音预训练模型中进行编码,获得语音信号的高级特征;
89、拼接模块,用于提取语音信息中的mfcc声学特征,并将语音信号的高级特征与声学特征按帧拼接,获得语音特征序列;
90、文本特征序列构建模块,用于使用文本预训练模型提取文本信息的高级特征,构建出文本特征序列;
91、情感特征提取模块,用于使用自注意力机制分别提取语音特征序列和文本特征序列中的关键情感特征,并通过长短期记忆神经网络给每个关键情感特征分别添加时序信息,获得语音深度情感特征和文本深度情感特征;
92、融合模块,用于采用模态融合算法将语音深度情感特征和文本深度情感特征进行融合,获得语音情感特征;
93、识别模块,用于根据语音情感特征对待识别语音数据进行情感识别。
94、本发明提供了一种双模态语音情感识别方法及系统,具备以下有益效果:
95、本发明的双模态语音情感识别方法与传统方法相比,传统方法通常仅依赖于语音数据,而本发明将语音与文本两种模态的信息有机地融合,利用预训练模型提取高级特征,并通过自适应特征学习以及多模态情感表示,将这些特征融合得更全面和准确;这不仅提高了情感识别的准确性和鲁棒性,还减少了对大量标记数据的依赖,使得方法更具可扩展性,同时综合考虑语音和文本信息,在情感识别领域具有巨大的潜力,可应用于情感智能助手、智能客户服务、情感分析等多个领域,为用户提供更优质的体验和更精准的决策支持。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24102.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。