一种残障人士辅助发音装置
- 国知局
- 2024-06-21 11:52:37
本技术涉及聋哑助言装置,具体涉及一种残障人士辅助发音装置。
背景技术:
1、人类的发声机理复杂,是一系列器官协调工作的结果,有一定规则的可重复性动作,而发音障碍是指发音困难、发音异常、发音不清但用语正确,是由于发音器官肌肉瘫痪、共济失调或肌张力增高所致。表现为语音障碍,构音障碍,发音无力、生硬,言语流畅性障碍等。常见疾病有肌肉萎缩侧索硬化、延髓空洞症、多发性硬化症、重症肌无力、进行性肌营养不良症等。
2、发声障碍是常见言语残疾,病患众多,极大影响病人的生活质量和社会稳定,目前,发声障碍患者通常是采用手语或写字与他人交流,但是目前社会上能掌握使用手语的人较少,写字交流速度也较慢,这些不便都影响了发生障碍患者与他人交流的欲望,同时在发声障碍患者独自在外遇到急事时,也难以快速有效的与旁人沟通求助,因此亟需一种便携式可以用来将使用者发声和练习的内容进行实时翻译输出给他人的装置。
技术实现思路
1、本发明的目的在于:针对目前现有技术的不足,提供一种残障人士辅助发音装置,对使用者对发声器官的运动进行识别提取特征信息,根据特征信息判断出正确的发音。
2、为了实现上述发明目的,本发明提供了以下技术方案:
3、在本技术的第一方面,提供一种残障人士辅助发音装置,包括:
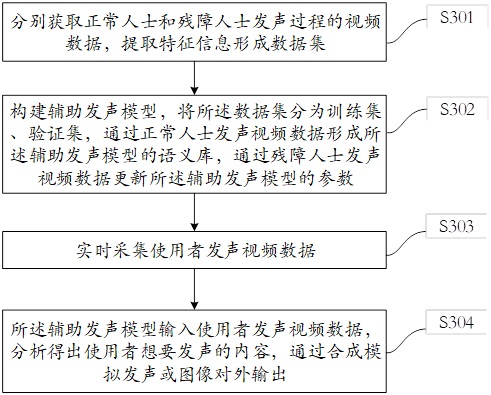
4、视频获取模块:分别获取正常人士和残障人士发声过程的视频数据,提取特征信息形成数据集;
5、模型训练模块:构建辅助发声模型,将所述数据集分为训练集、验证集,通过正常人士发声视频数据形成所述辅助发声模型的语义库,通过残障人士发声视频数据更新所述辅助发声模型的参数;
6、视频采集模块:实时采集使用者发声视频数据;
7、分析输出模块:所述辅助发声模型输入使用者发声视频数据,分析得出使用者想要发声的内容,通过合成模拟发声或图像对外输出。
8、在本技术一实施例中,所述分析输出模块合成模拟发声或图像对外输出后,该装置还包括:
9、语义判断模块:使用者根据对外输出的合成模拟发声或图像内容判断是否为自己想要发声的内容;
10、模型修正模块:将合成模拟发声或图像对应的使用者发声视频数据,以及合成模拟发声或图像内容是否正确的结果一并返回所述数据集中,更新所述辅助发声模型的参数。
11、在本技术一实施例中,所述语义判断模块具体包括快速判断子模块和部分判断子模块:
12、所述快速判断子模块在合成模拟发声或图像内容输出后,使用者立即判断输出内容是否正确,所述分析输出模块根据匹配度生成输出的和备用的合成模拟发声或图像内容,使用者判断输出内容错误时,所述快速判断子模块可选择输出备用的合成模拟发声或图像内容,或者重新通过所述视频采集模块采集使用者发声视频数据;使用者判断输出内容正确时,所述视频采集模块继续进行采集使用者发声视频数据;并将判断结果发送至所述模型修正模块;
13、所述部分判断子模块将输出的合成模拟发声或图像内容匹配对应时间所述视频采集模块采集的视频数据,一同提供给使用者,使用者对输出的合成模拟发声或图像内容的整体或部分进行修改,并将修改结果发送至所述模型修正模块。
14、在本技术一实施例中,使用者可以通过按压外接按钮向所述快速判断子模块发送判断输出内容正确或错误的结果,所述外接按钮包括正确按钮和错误按钮;
15、使用者还可以通过表情设置向所述快速判断子模块发送判断输出内容正确或错误的结果,所述表情设置提前设置使用者做出相应表情,规定相应表情所表达的语义为正确或错误,使用过程中通过所述视频采集模块采集到使用者做出相应表情时,根据相应表情匹配的语义,向所述快速判断子模块发送判断输出内容正确或错误的结果。
16、在本技术一实施例中,所述快速判断子模块还包括在线求助模块,当所述快速判断子模块检测到使用者连续多次判断输出内容错误时,询问使用者是否开启所述在线求助模块,所述在线求助模块连线提前设置的使用者家属或在线手语老师,通过使用者家属或在线手语老师为使用者输出想要表达的内容,同时向使用者家属或在线手语老师发送使用者坐标定位。
17、在本技术一实施例中,所述视频采集模块和所述视频获取模块还包括分割子模块,所述分割子模块对视频内容进行识别,识别出面部以及喉部的区域;
18、通过边缘检测算法得出面部以及喉部的边缘,并根据面部以及喉部的边缘对面部以及喉部进行框选;
19、将没有被框选的视频区域进行删除操作。
20、在本技术一实施例中,所述视频采集模块可以收纳至贴合使用者体表,也可以伸长至使用者面前,所述视频采集模块不使用时可以收纳至贴合使用者体表,各模块进入待机状态,所述视频采集模块使用时伸长至使用者面前,所述视频采集模块开始采集使用者面部以及喉部的实时影像,各模块自动开始工作。
21、在本技术一实施例中,所述模型修正模块将所述辅助发声模型更新前的参数进行存储为通用数据库,将更新的所述辅助发声模型的参数进行存储为附加数据库,不同使用者得到的不同更新所述辅助发声模型的参数进行独立存储,形成一个所述通用数据库和多个所述附加数据库,一个使用者多次更新对应一个所述附加数据库。
22、在本技术一实施例中,所述视频采集模块还包括采集使用者的人脸数据,所述人脸数据与所述附加数据库相对应,通过所述视频采集模块开始采集使用者面部以及喉部的实时影像之前对使用者的人脸数据进行采集,当所述人脸数据存在有对应的所述附加数据库时,切换使用该附加数据库;当所述人脸数据没有对应的所述附加数据库时,使用通用数据库。
23、在本技术一实施例中,所述附加数据库包括主数据库和副数据库,所述主数据库对应所述使用者中最常使用的使用者,对所述主数据库进行本地存储;所述副数据库对应其他使用者,对所述副数据库进行云端存储。
24、本技术具有以下有益效果:
25、在本技术方案中,尽管发声障碍人士难以同正常人士一样清楚的将语句进行发音,但是发声障碍人士在发声时面部以及喉部的肌肉动作与正常人士相似,因此只需要对部分发声器官的运动进行识别,提取到足够特征信息,就能够判断出正确的发音,通过建立语义库将发音使面部以及喉部的肌肉运动情况与语义库中的具体语句建立联系,发声障碍患者就可以不通过手语或写字就可以与他人交流,在发声障碍患者独自在外遇到急事时,也难以快速有效的与旁人沟通求助,解决了发声障碍人士与他人交流的问题,帮助他们辅助发声,以达到与人交流的目的,使得他们恢复正常人的生活方式,正常的沟通交流,工作,学习;进一步的由于发声障碍人士由于所患疾病不同、习惯不同,因此每一个发声障碍人士发声时面部以及喉部的肌肉动作可能会有个体化差异,提前训练好的辅助发声模型针对性不强,对于患病较为罕见,面部及喉部动作差异性较大的发声障碍患者使用辅助发声模型容易无法输出使用者想说的内容,因此使用者通过语义判断模块判断所述辅助发声模型输出的内容是否为自己想说的内容,再通过模型修正模块将判断结果返回到所述数据集中再进行辅助发声模型的训练,使所述辅助发声模型在使用者使用过程中,输出内容的准确性会根据修正次数的增多而越来越高。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24186.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表