一种基于鲁棒声纹反欺诈系统的制作方法
- 国知局
- 2024-06-21 11:55:28
本发明涉及信息安全和语音识别,更具体地说,涉及一种基于鲁棒声纹反欺诈系统。
背景技术:
1、随着科技的飞速发展,网络欺诈行为已经成为一个日益严重的问题,给人们的生活带来了极大的困扰。传统的反欺诈手段主要依赖于人工审核,这种方式不仅效率低下,而且容易出错。近年来,声纹识别技术因其独特的安全性和便捷性,被广泛应用于反欺诈领域。声纹识别技术是一种基于人的声音特征进行身份验证的技术。它通过分析和比对人体发出的声音信号,提取出独特的声纹特征,从而实现对个体身份的准确识别。与传统的反欺诈手段相比,声纹识别技术具有以下几个显著优势:首先,声纹识别技术具有高度的安全性。每个人的声纹特征都是独一无二的,即使是同卵双胞胎也无法拥有完全相同的声纹。因此,声纹识别技术可以有效地防止身份冒用和欺诈行为的发生。其次,声纹识别技术具有便捷性。用户只需通过语音输入即可完成身份验证,无需进行复杂的操作或携带额外的设备。这种便捷的使用方式使得声纹识别技术在反欺诈领域的应用更加广泛。此外,声纹识别技术还具有较高的准确性和可靠性。经过大量的研究和实践证明,声纹识别技术在识别准确率方面已经达到了相当高的水平。同时,声纹识别技术还可以有效地应对各种环境噪声和语音干扰,确保身份验证的准确性和可靠性。
2、然而,尽管现有的声纹识别系统在许多方面都取得了显著的进展,但在面对复杂的欺诈行为时,其识别准确率和鲁棒性仍有待提高。这意味着,目前的声纹识别技术可能无法完全满足实际应用中对于安全性和可靠性的需求。我们需要认识到声纹识别系统的识别准确率受到多种因素的影响。例如,说话人的声音特征可能会因为年龄、性别、健康状况等因素而发生变化,这可能导致声纹识别系统在识别过程中出现误判。此外,环境噪声、设备性能等外部因素也可能对识别准确率产生影响。因此,为了提高声纹识别系统的识别准确率,我们需要不断优化算法,使其能够更好地适应各种复杂场景。
3、为此,提出一种基于鲁棒声纹反欺诈系统。
技术实现思路
1、针对现有技术中存在的问题,本发明的目的在于提供一种基于鲁棒声纹反欺诈系统。
2、为解决上述问题,本发明采用如下的技术方案。
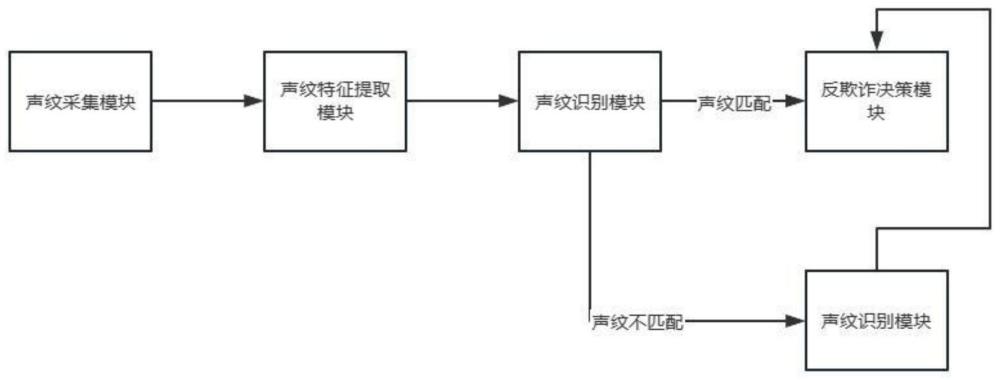
3、一种基于鲁棒声纹反欺诈系统,包括声纹采集模块、声纹特征提取模块、声纹识别模块和反欺诈决策模块,所述声纹采集模块用于采集用户的声纹数据,所述声纹特征提取模块用于从声纹数据中提取出鲁棒的声纹特征,所述声纹识别模块用于将提取出的声纹特征与数据库中的声纹特征进行比对,得出识别结果,所述反欺诈决策模块根据声纹识别模块的识别结果,做出是否为欺诈行为的决策。
4、优选地,所述声纹采集模块包括麦克风阵列,利用多个麦克风采集声音信号,用于提高声纹识别的准确性和稳定性,所述声音信号收集后进行预处理,所述预处理包括音频降噪和音频增强,所述音频降噪去除背景噪音,提高声纹质量,所述音频增强放大声音信号,提高声纹可辨度。
5、优选地,所述声纹特征提取模块包括mfcc特征和梅尔倒谱系数(mfcc)特征,所述mfcc(mel频率倒谱系数)特征是一种在语音识别领域广泛应用的音频处理技术,它通过将音频信号进行短时傅里叶变换(short-time fourier transform,stft),提取主要频率成分,从而实现对音频信号的特征提取,短时傅里叶变换是一种将时间域信号转换为频域信号的算法,它通过在时间域上对信号进行分段,然后对每个时间段内的信号进行傅里叶变换,这种方法可以有效地将音频信号分解为不同频率成分,以便进一步分析,在mfcc特征提取过程中,主要步骤如下:
6、(1)分段:将音频信号划分为多个短时帧,通常采用一种叫做帧长度的固定窗口进行处理,帧长度的选择需要考虑到信号的频率特性,以保证在捕捉到有效信息的同时,减少计算复杂度;
7、(2)预加重:为了更好地捕捉音频信号的高频成分,在短时傅里叶变换之前,我们对信号进行预加重处理,预加重是通过一个一阶高通滤波器实现的,它可以提高音频信号的高频部分,从而提高识别性能;
8、(3)短时傅里叶变换:将预处理后的信号进行短时傅里叶变换,得到每个时间帧的频谱表示,这一步的目的是将时间域信号转换为频域信号,以便分析音频信号的频率成分;
9、(4)提取主要频率成分:在得到频谱表示后,我们需要提取其中的主要频率成分,这可以通过计算频谱的功率谱密度(power spectral density,psd)来实现,功率谱密度反映了音频信号在不同频率上的能量分布,我们可以根据这一特性来确定主要频率成分;
10、(5)计算mfcc:在提取主要频率成分的基础上,我们计算mfcc,mfcc是通过将功率谱密度进行离散余弦变换(dct)得到的,离散余弦变换可以将功率谱密度转换为一系列离散的频率系数,这些系数可以有效地表征音频信号的频率特性;
11、(6)降维:为了降低特征维数,我们对mfcc进行主成分分析(pca)或其他降维方法,这可以使我们保留大部分有用信息,同时减少计算量和噪声;
12、通过以上步骤,我们可以得到一个低维的mfcc特征向量,用于后续的语音识别任务,mfcc特征在语音识别领域具有较高的识别性能,是因为它能够有效地捕捉音频信号的频率成分,同时具有较强的鲁棒性和泛化能力;
13、所述梅尔倒谱系数(mfcc)特征在mfcc基础上,加入线性预测编码(lpc)和高通滤波器,梅尔倒谱系数(mfcc)是一种在语音信号处理领域广泛应用的声学特征参数,它通过将声音信号转换为频域,然后对频谱幅度进行加权,最后得到一系列反映声音信号频谱特性的梅尔频率倒谱系数,在mfcc基础上,为进一步提高特征的表达能力,研究者们提出了加入线性预测编码(lpc)和高通滤波器的改进方法,线性预测编码是一种用于预测语音信号的算法,通过计算语音信号的短时自相关函数,得到一组参数,用于表示语音信号的谐波结构,这些参数可以作为特征向量,提高语音处理的性能,高通滤波器则在信号处理中起到保留高频信息的作用,在mfcc计算过程中,高通滤波器能够有效地去除低频噪声,使得提取的梅尔倒谱系数更能反映语音信号的特性,通过加入高通滤波器,我们可以得到更加聚焦于高频信息的梅尔倒谱系数,进一步提高特征的鲁棒性。
14、优选地,所述声纹识别模块包括支持向量机(svm)分类器和深度学习算法(如卷积神经网络cnn、循环神经网络rnn),所述支持向量机(svm)分类器通过训练数据学习一个最优的分类模型,对新的声音信号进行分类,所述深度学习方法(如卷积神经网络cnn、循环神经网络rnn)利用深度学习模型自动学习声纹特征,提高声纹识别的准确性和鲁棒性。
15、优选地,所述反欺诈决策模块包括风险评估模型和实时监控与预警,所述风险评估模型根据声纹识别结果和历史欺诈案例,计算用户的风险等级,所述实时监控与预警实时监测用户的声纹识别结果,发现异常行为并及时预警。
16、相比于现有技术,本发明的有益效果在于:
17、(1)本方案采用的声纹特征提取方法通过优化预处理、特征提取和模型匹配等环节,能够有效地提高声纹识别的鲁棒性,从而提高反欺诈的准确性。
18、(2)本方案反欺诈决策模块,能够根据声纹识别的结果,快速准确地判断出是否为欺诈行为,提高了反欺诈的效率。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24492.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表